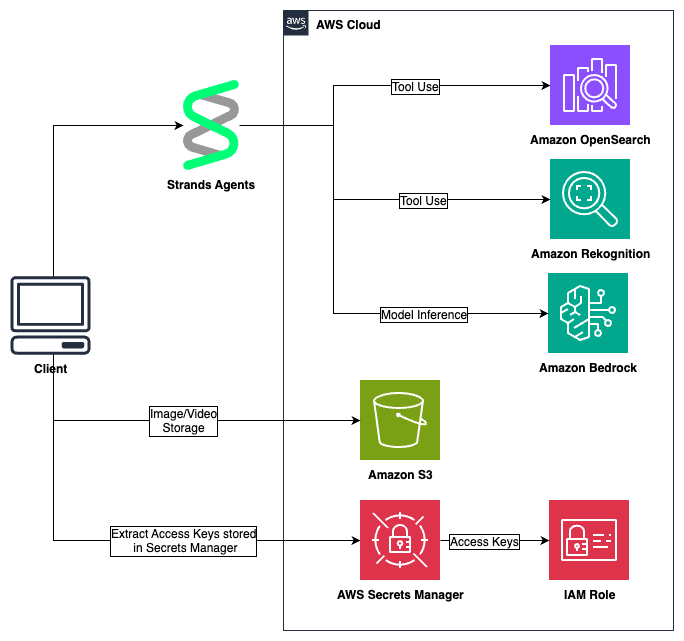
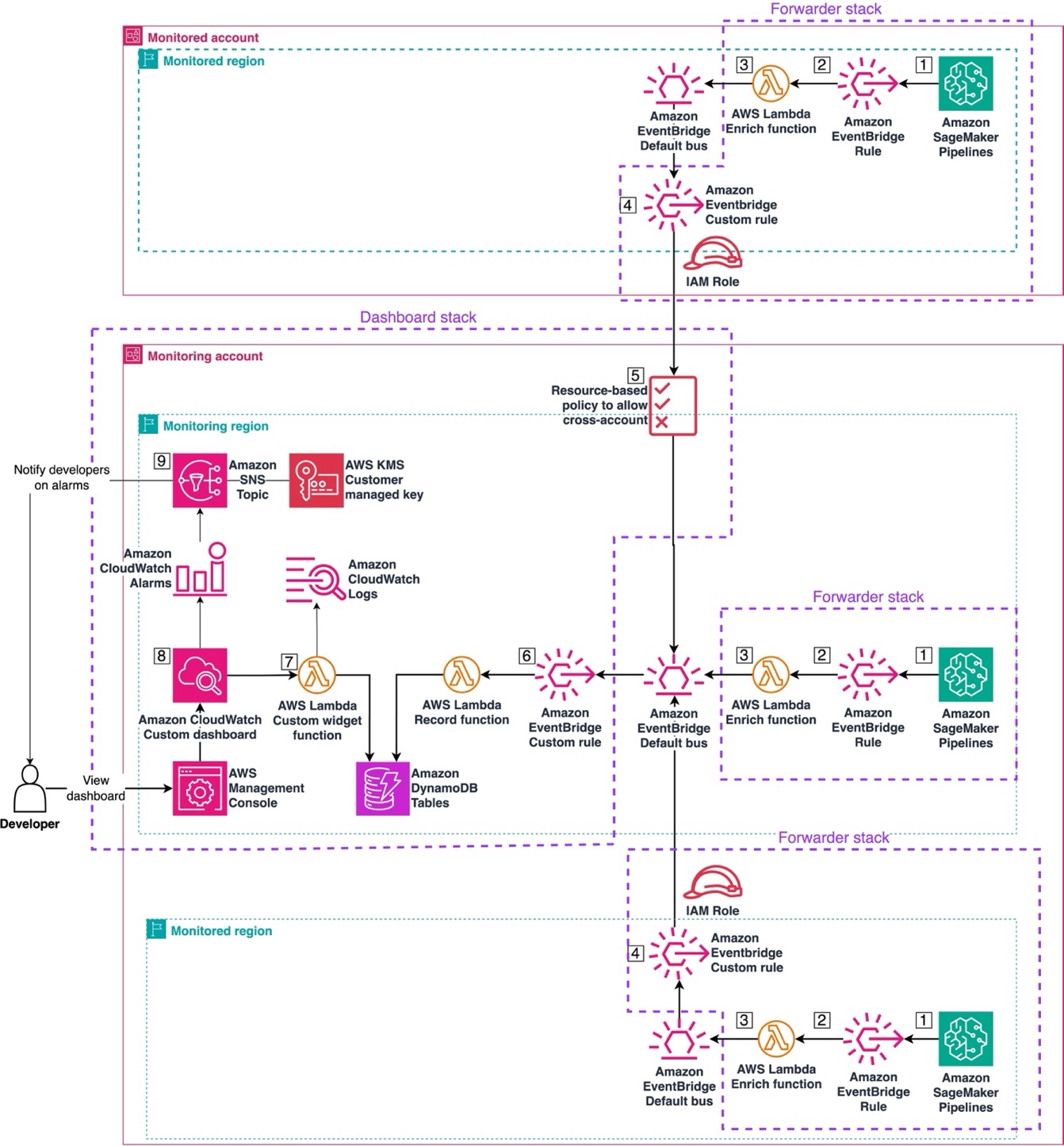
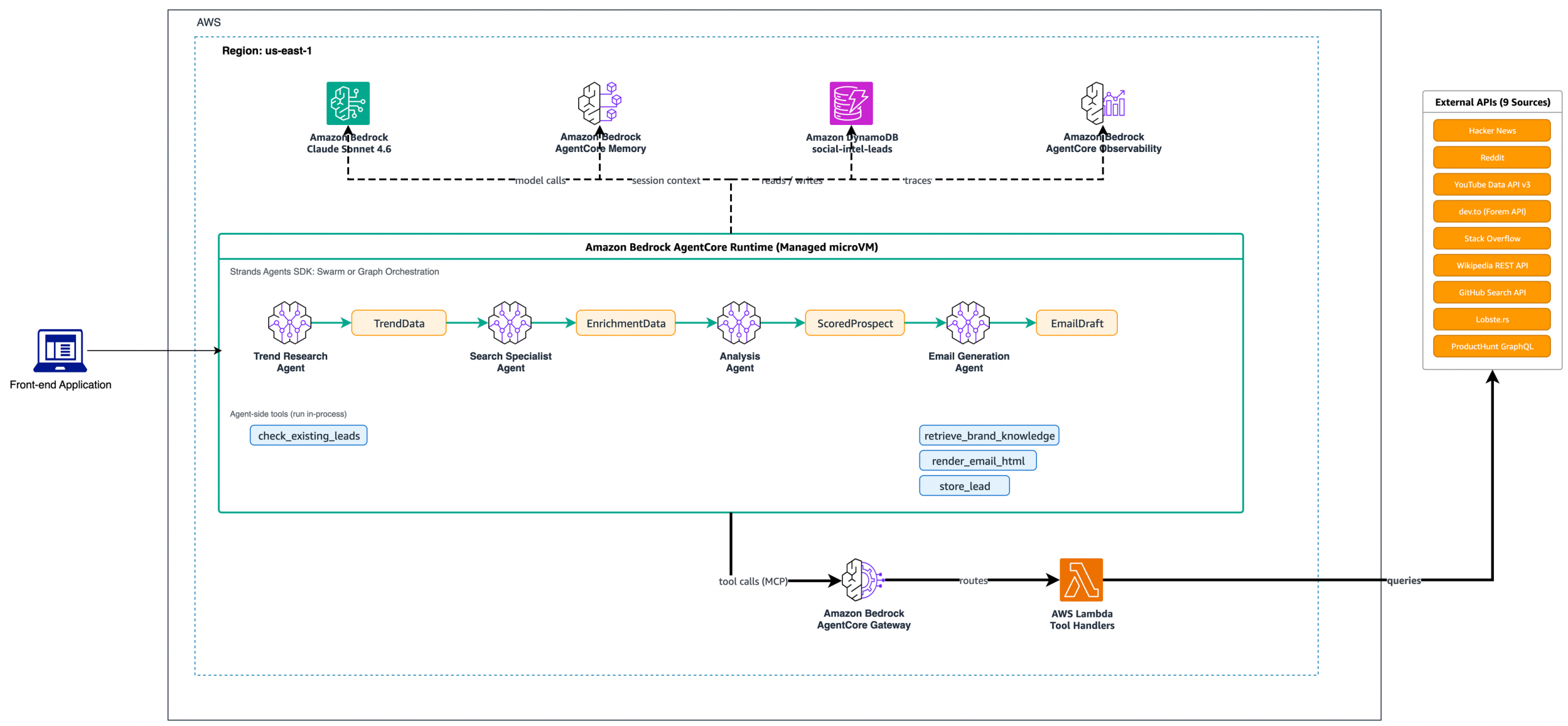
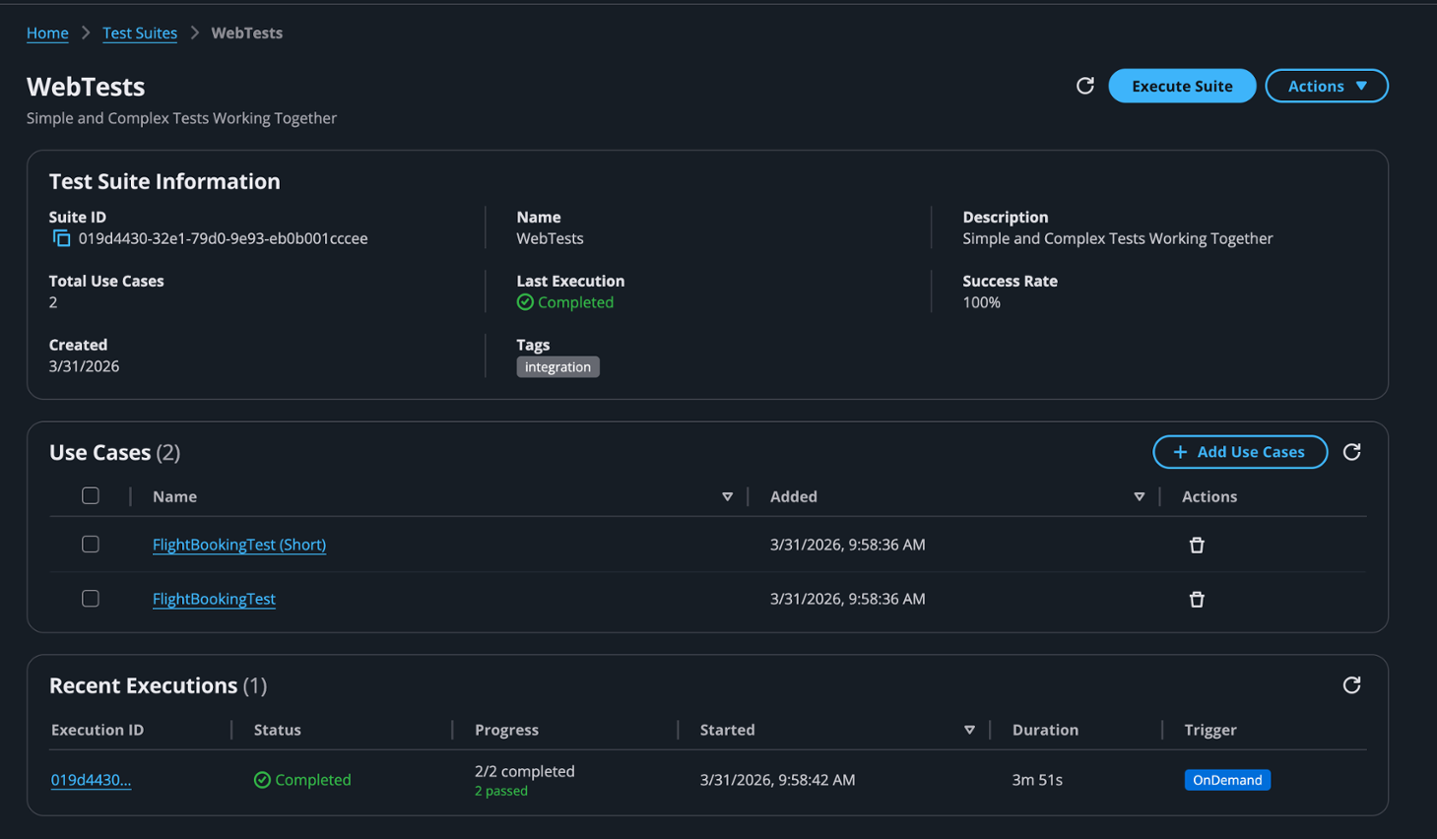
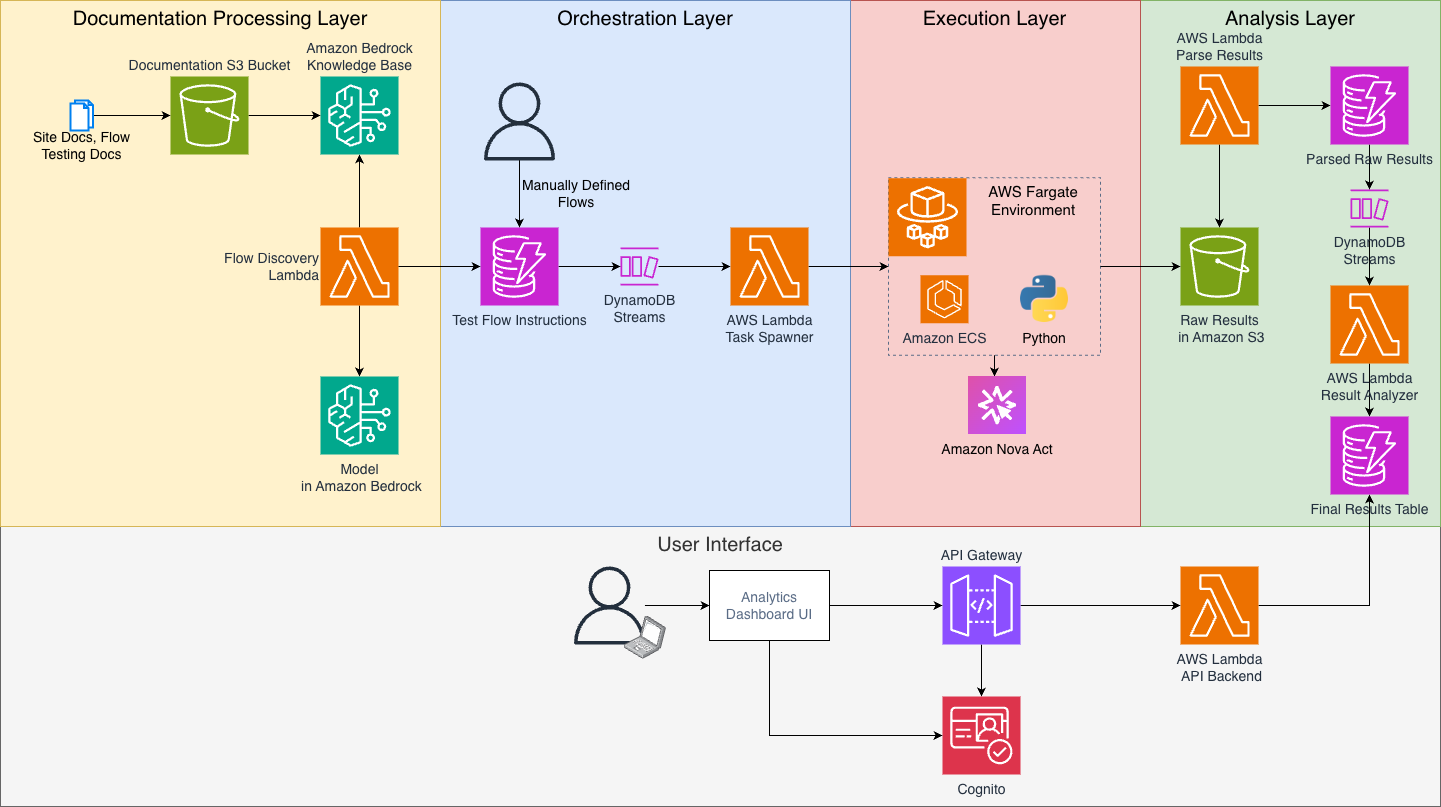
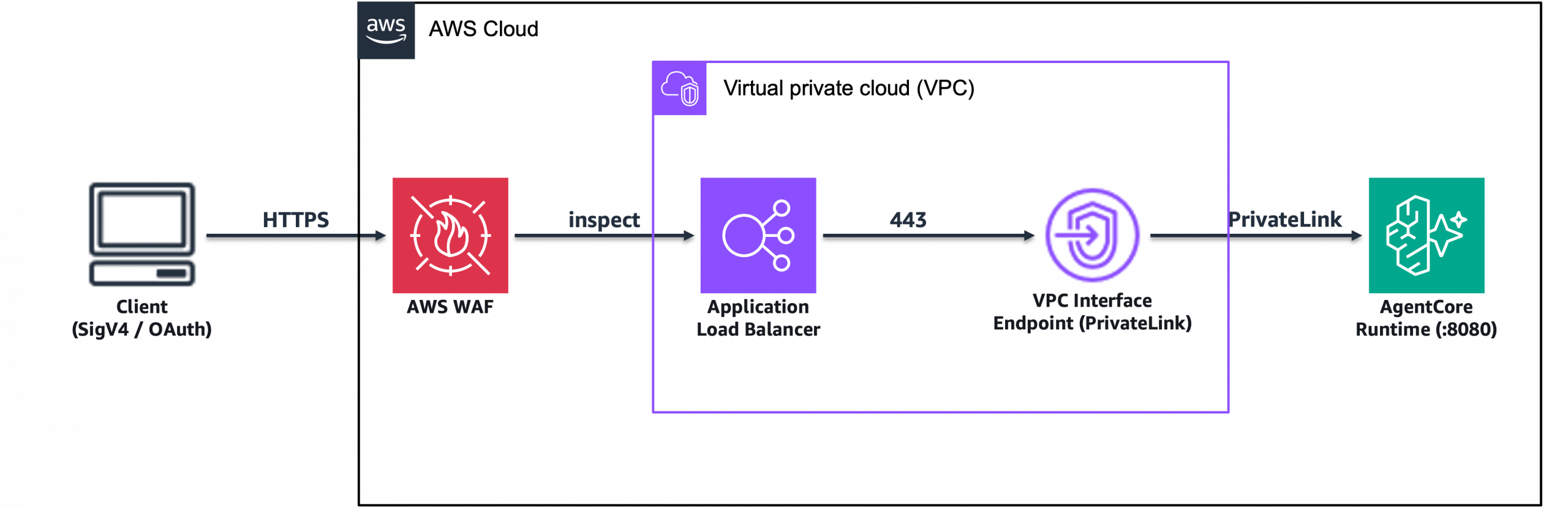
Built Technologies builds an AI-powered document intelligence solution on AWS to power agents across real estate finance
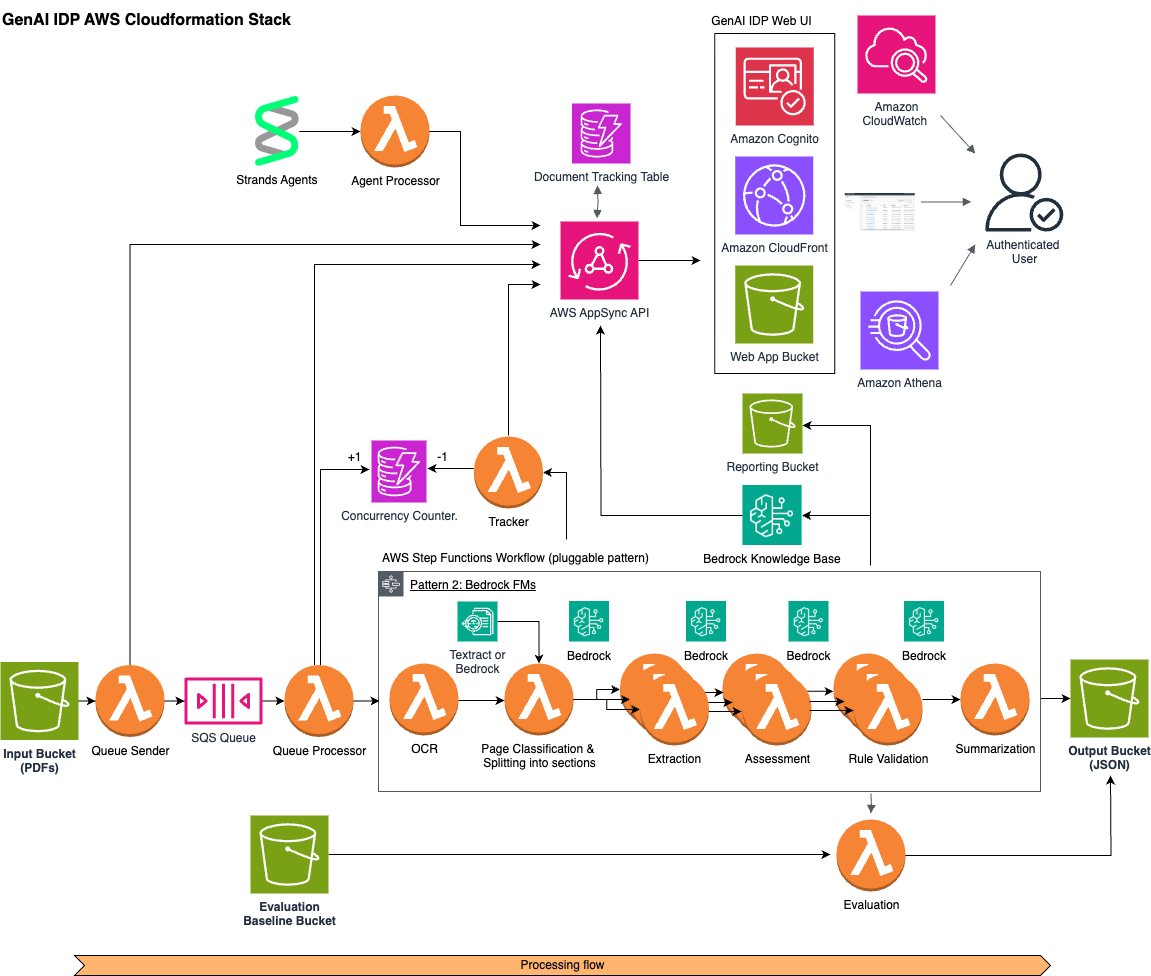
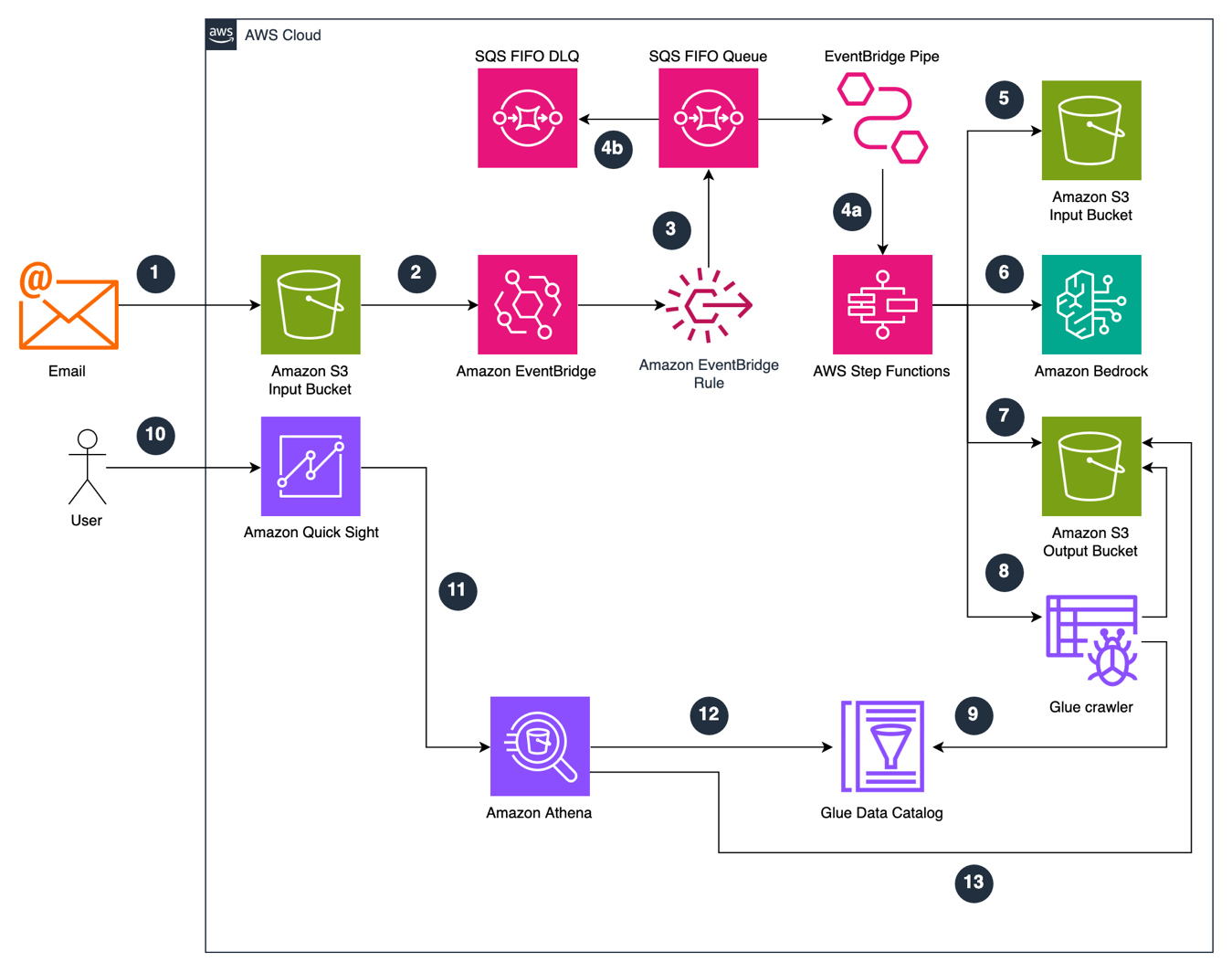
Document processing in real estate is complex and highly manual, impacting critical business decisions at scale, making it ripe for automation. Built Technologies, a real estate finance software provider, processes over $500B in real estate projects. The company deployed an AI-powered document processing engine on Amazon Bedrock and the AWS Intelligent Document Processing (IDP) Accelerator. … Read more