Generative AI is rapidly reshaping the music industry, empowering creators—regardless of skill—to create studio-quality tracks with foundation models (FMs) that personalize compositions in real time. As demand for unique, instantly generated content grows and creators seek smarter, faster tools, Splash Music collaborated with AWS to develop and scale music generation FMs, making professional music creation accessible to millions.
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.
Challenge: Scaling music generation
Splash Music has empowered a new generation of creators to make music, and has already driven over 600 million streams worldwide. By giving users tools that adapt to their evolving tastes and styles, the service makes music production accessible, fun, and relevant to how fans actually want to create. However, building the technology to unlock this creative freedom, especially the models that power it, meant overcoming several key challenges:
- Model complexity and scale – Splash Music developed HummingLM—a cutting-edge, multi-billion-parameter model tailored for generative music to deliver its mission of making music creation truly accessible. HummingLM is engineered to capture the subtlety of human humming, converting creative ideas into music tracks. Meeting these high standards of fidelity meant Splash had to scale up computing power and storage significantly, so the model could deliver studio-quality music.
- Rapid pace of change – The pace of industry and technological change, driven by rapid AI advancement, means Splash Music must continually adapt, train, fine-tune, and deploy new models to meet user expectations for fresh, relevant features.
- Infrastructure scaling – Managing and scaling large clusters in the generative AI model development lifecycle brought unpredictable costs, frequent interruptions, and time-consuming manual management. Prior to AWS, Splash Music relied on externally managed GPU clusters, which involved unpredictable latency, additional troubleshooting, and management complexity that hindered their ability to experiment and scale as quickly as needed.
The service needed a scalable, automated, and cost-effective infrastructure.
Overview of HummingLM: Splash Music’s foundation model
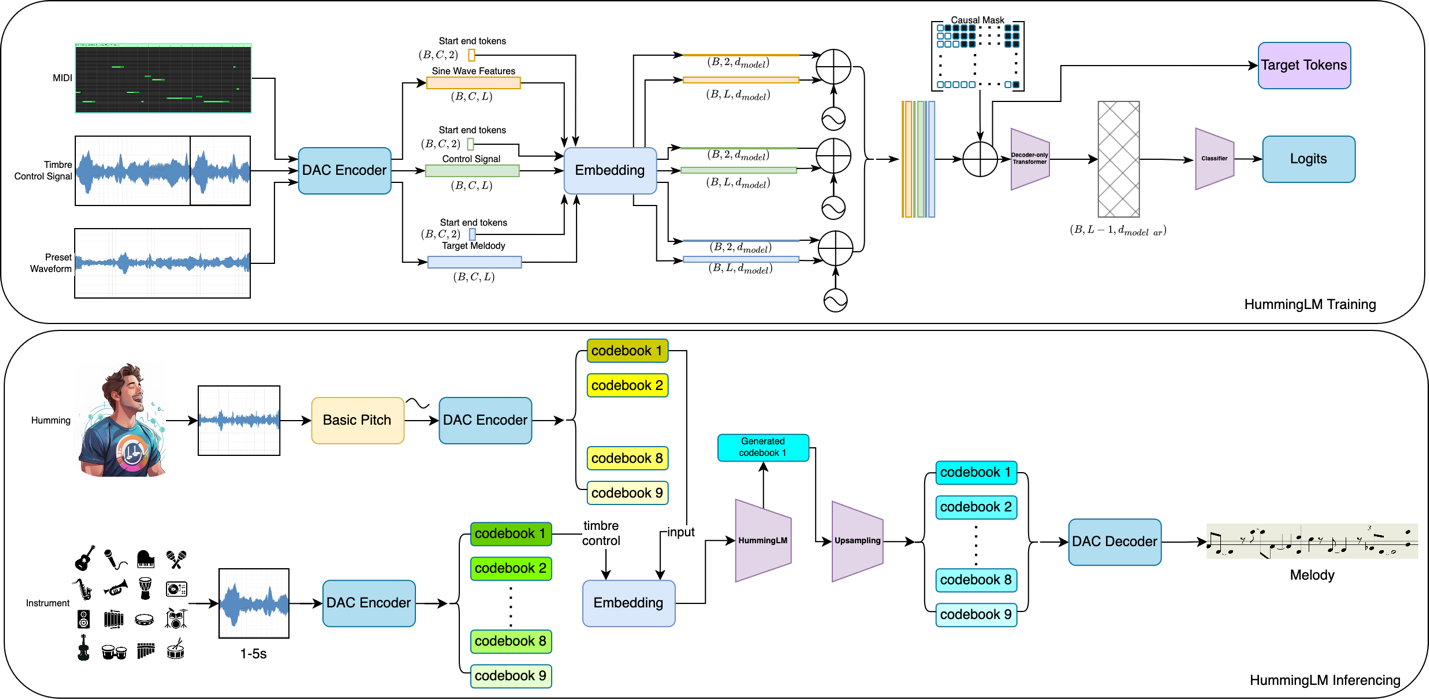
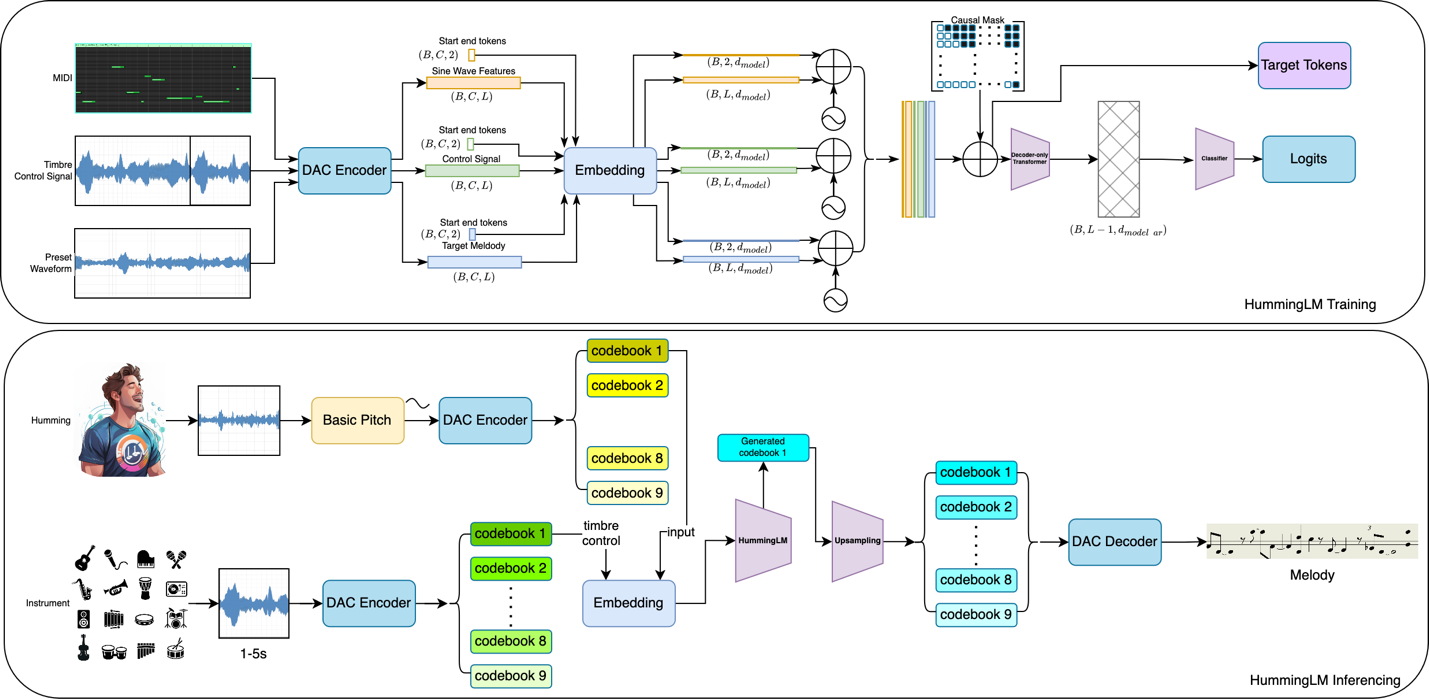
HummingLM is Splash Music’s proprietary, multi-modal generative model, developed in close collaboration with the GenAIIC. It represents an improvement in how AI can interpret and generate music. The model’s architecture is built around a transformer-based large language model (LLM) coupled with a specialized music encoder upsampler:
- HummingLM uses Descript-Audio-Codec (DAC) audio encoding to obtain compressed audio representations that capture both frequency and timbre characteristics
- The system transforms hummed melodies into professional instrumental performances without explicit timbre representation learning
The innovation lies in how HummingLM fuses these token streams. Using a transformer-based backbone, the model learns to blend the melodic intent from humming with the stylistic and structural cues from instrument sound (for example, to make the humming sound like a guitar, piano, flute, or different synthesized sound). Users can hum a tune, add an instrument control signal, and receive a fully arranged, high-fidelity track in return. HummingLM’s architecture is designed for both efficiency and expressiveness. By using discrete token representations, the model achieves faster convergence and reduced computational overhead compared to traditional waveform-based approaches. This makes it possible to train on diverse, large-scale datasets and adapt quickly to new genres or user preferences.
The following diagram illustrates how HummingLM is trained and the inference process to generate high-quality music:
Solution overview: Accelerating model development with AWS Trainium on Amazon SageMaker HyperPod
Splash Music collaborated with the GenAIIC to advance its HummingLM foundation model, using the combined capabilities of Amazon SageMaker HyperPod and AWS Trainium chips for model training.
Splash Music’s architecture follows SageMaker HyperPod best-practices using Amazon Elastic Kubernetes Service (EKS) as the orchestrator, FSx for Lustre for storage to store over 2 PB of data, and AWS Trainium EC2 instances for acceleration. The following diagram illustrates the solution architecture.
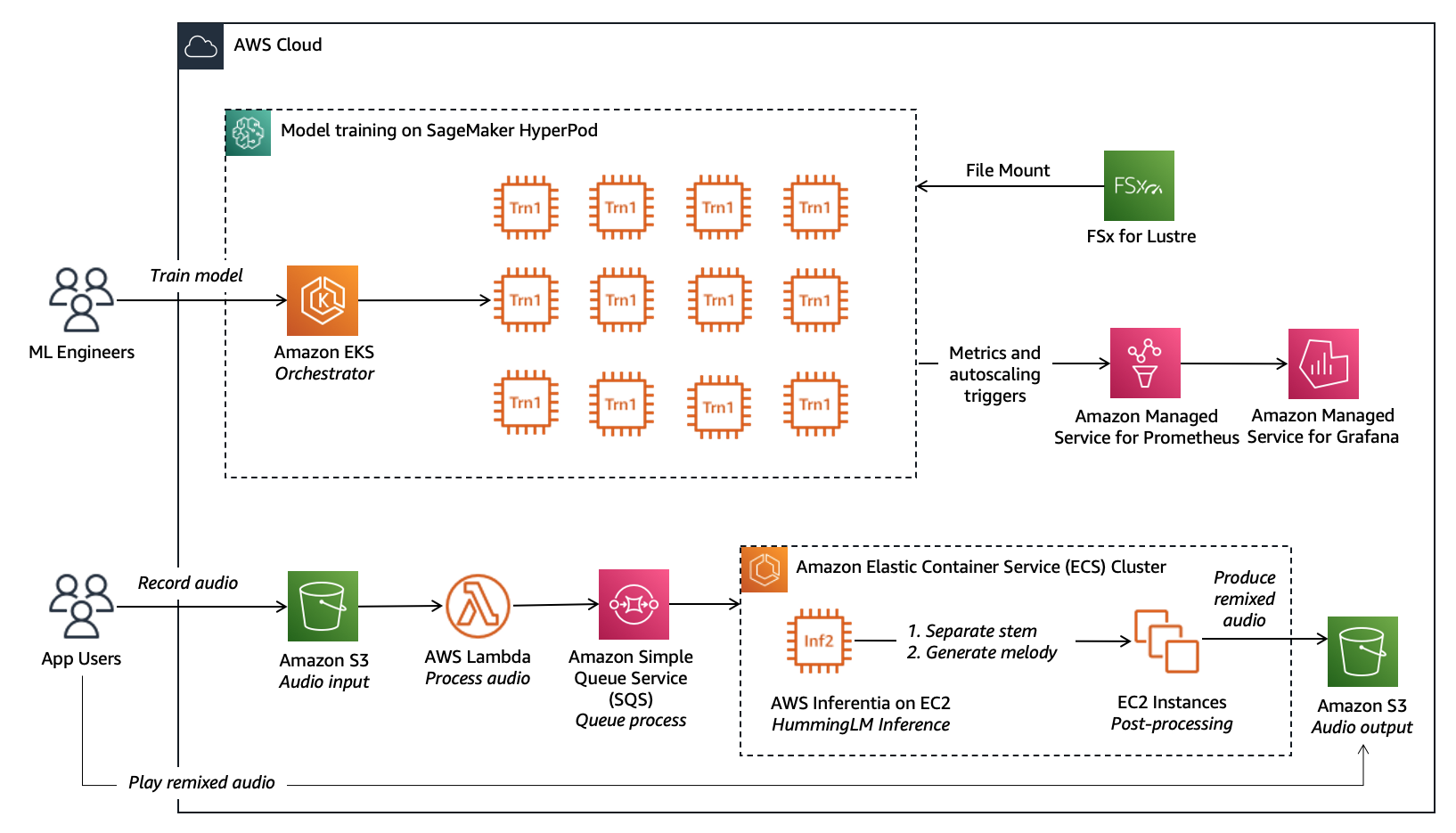
In the following sections, we walk through each step of the model development lifecycle, from dataset preparation to compilation for optimized inference.
Dataset preparation
Efficient preparation and processing of large-scale audio datasets is critical for developing controllable music generation models:
- Feature extraction pipeline – Splash Music built a feature extraction pipeline for efficient, scalable processing of large volumes of audio data, producing high-quality features for model training. It starts by retrieving audio in batches from a centralized database, minimizing I/O overhead and supporting large-scale operations.
- Audio processing – Each audio file is resampled from 44,100 Hz to 22,050 Hz to standardize inputs and reduce computational load. A mono reference signal is also created by averaging the stereo channels from a reference audio file, serving as a consistent benchmark for analysis. In parallel, a Basic Pitch Extractor generates a synthetic, MIDI-like version of the audio, providing a symbolic representation of pitch and rhythm that enhances the richness of extracted features.
- Descript Audio Codec (DAC) extractor – The pipeline processes three audio streams: the stereo channels from the original audio, the mono reference, and the synthetic MIDI signal. This multi-stream approach captures diverse aspects of the audio signal, producing a robust set of features. Extracted data is organized into two main sets: audio-feature, which includes features from the original stereo channels, and sine-audio-feature, which contains features from the MIDI and mono reference audio. This structure streamlines downstream model training.
- Parallel processing: To maximize performance, the pipeline uses parallel processing for concurrent feature extraction and data uploading. This significantly boosts efficiency, making sure the system handles large datasets with speed and consistency.
In addition, the solution uses an advanced stem separation system that isolates songs into six distinct audio stems: drums, bass, vocals, lead, chordal, and other instruments:
- Stem Preparation: Splash Music creates high-quality training data by preparing separate stems for each musical element. Lead and chordal stems are generated using a synthesizer tool and a diverse dataset of music tracks. This rich dataset covers multiple genres and styles. This provides a strong foundation for the model to learn precise component separation.
By streamlining data handling from the outset, we make sure that the subsequent model training stages have access to clean, well-structured features.
Model architecture and optimization
HummingLM employs a dual-component architecture:
- LLM for coarse token generation – A 385 M parameter transformer-based language model (24 layers, 1024 embedding dimension, 16 attention heads) that generates foundational musical structure
- Upsampling component – A specialized component that expands the coarse representation into complete, high-fidelity audio.
This division of labor is key to HummingLM’s effectiveness: the LLM captures high-level musical intent, and the upsampling component handles acoustic details. Together with the GenAIIC, Splash collaborated on research to optimize the HummingLM model to facilitate optimal performance:
- Flexible control signal design – The model accepts control signals of varying durations (1-5 seconds), a significant improvement over fixed-window approaches.
- Zero-shot capability – Unlike systems requiring explicit timbre embedding learning, HummingLM can generalize to unseen instrument presets without additional training.
- Non-autoregressive generation – The upsampling component uses parallel token prediction for significantly faster inference compared to traditional autoregressive approaches.
Our evaluation demonstrated HummingLM’s superior first codebook prediction capabilities – a critical factor in residual quantization systems where the first codebook contains most acoustic information. The model consistently outperformed baseline approaches like VALL-E across multiple quality metrics. The evaluation revealed several important findings:
- HummingLM demonstrates significant improvements over baseline approaches in signal fidelity (57.93% better SI-SDR)
- The model maintains robust performance across diverse musical conditions, with particular strength in the Aeolian mode
- Zero-shot performance on unseen instrument presets is comparable to seen presets, confirming strong generalization capabilities
- Data augmentation strategies provide substantial benefits (27.70% improvement in SI-SDR)
Overall, HummingLM achieves state-of-the-art controllable music generation by significantly improving signal fidelity, generalizing well to unseen instruments, and delivering strong performance across diverse musical styles, boosted further by effective data augmentation strategies.
Efficient distributed training through parallelism, memory, and AWS Neuron optimization
Splash Music compiled and optimized its model for AWS Neuron, accelerating its model development lifecycle and deployment on AWS Trainium chips. The team considered scalability, parallelization, and memory efficiency and designed a system for supporting models scaling from 2B to over 10B parameters. This includes:
- Enable distributed training with sequence parallelism (SP), tensor parallelism (TP), and data parallelism (DP), scaling up to 64 trn1.32xlarge instances
- Implement ZeRO-1 memory optimization with selective checkpoint re-computation
- Integrate Neuron Kernel Interface (NKI) to deploy Flash Attention, accelerating dense attention layers and streamlining causal mask management
- Decompose the model into core subcomponents (token processors, transformer layers, MLPs) and optimize each for Neuron execution
- Implement mixed-precision training (bfloat16 and float32)
When optimizations at the Neuron level were complete, optimizing the orchestration layer was important as well. Orchestrated by SageMaker HyperPod, Splash Music developed a robust, Slurm-integrated pipeline that streamlines multi-node training, balances parallelism, and uses activation checkpointing for superior memory efficiency. The pipeline processes data through several critical stages:
- Tokenization – Audio inputs are processed through a Descript Audio Codec (DAC) encoder to generate multiple codebook representations
- Conditional generation – The model learns to predict codebooks given hummed melodies and timbre control signals
- Loss functions – The solution uses a specialized cross-entropy loss function to optimize both token prediction and audio reconstruction quality
Model Inference on AWS Inferentia on Amazon Elastic Container Service (ECS)
After training, the model is deployed on an Amazon Elastic Container Service (Amazon ECS) cluster with AWS Inferentia instances. The audio is uploaded to Amazon Simple Storage Service (Amazon S3) to handle large volumes of user-submitted recordings, which often vary in quality. Each upload triggers an AWS Lambda function, which queues the file in Amazon Simple Queue Service (Amazon SQS) for delivery to the ECS cluster where inference runs. On the cluster, HummingLM performs two key steps: stem separation to isolate and clean vocals, and audio-to-melody conversion to extract musical structure. Finally, the pipeline recombines the cleaned vocals through a post-processing step with backing tracks, producing the fully processed remixed audio.
Results and impact
Splash Music’s research and development teams now rely on a unified infrastructure built on Amazon SageMaker HyperPod and AWS Trainium chips. The solution has yielded the following benefits:
- Automated, resilient and scalable training – SageMaker HyperPod provisions clusters of AWS Trainium EC2 instances at scale, managing orchestration, resource allocation, and fault recovery automatically. This removes weeks of manual setup and facilitates reliable, repeatable training runs. SageMaker HyperPod continuously monitors cluster health, automatically rerouting jobs and repairing failed nodes, minimizing downtime and maximizing resource utilization. With SageMaker HyperPod, Splash Music cut operational downtime to near zero, enabling weekly model refreshes and faster deployment of new features.
- AWS Trainium reduced Splash’s training costs by over 54% – Splash Music realized over twofold gains in training speed and cut training costs by 54% using AWS Trainium based instances over traditional GPU-based solutions used with their previous cloud provider. With this leap in efficiency, Splash Music can train larger models, release updates more frequently, and accelerate innovation across their generative music service. The acceleration also delivers faster model iteration, with 8% improvement in throughput, and increased its maximum batch size from 70 to 512 for a more efficient use of compute resources and higher throughput per training run.
Splash achieved significant throughput improvements over conventional architectures, to process expansive datasets, supporting the model’s complex multimodal nature. The solution provides a robust foundation for future growth as data and models continue to scale.
“AWS Trainium and SageMaker HyperPod took the friction out of our workflow at Splash Music.” says Daniel Hatadi, Software Engineer, Splash Music. “We replaced brittle GPU clusters with automated, self-healing distributed training that scales seamlessly. Training times are nearly 50% faster, and training costs have dropped by 54%. By relying on AWS AI chips and SageMaker HyperPod and collaborating with the AWS Generative AI Innovation Center, we were able to focus on model design and music-specific research, instead of cluster maintenance. This collaboration has made it easier for us to iterate quickly, run more experiments, train larger models, and keep shipping improvements without needing a bigger team.”
Splash Music also featured in the AWS Summit Sydney 2025 keynote:
Conclusion and Next Steps
Splash Music is redefining how creators bring their musical ideas to life, making it possible for anyone to generate fresh, personalized tracks that resonate with millions of listeners worldwide. To support this vision at scale, Splash built its HummingLM FM in close collaboration with AWS Startups and the GenAIIC, using services such as SageMaker HyperPod and AWS Trainium. These solutions provide the infrastructure and performance needed to keep pace, helping Splash to create even more intuitive and inspiring experiences for creators.
“With SageMaker HyperPod and Trainium, our researchers experiment as fast as our community creates.” says Randeep Bhatia, Chief Technology Officer, Splash Music. “We’re not just keeping up with music trends—we’re setting them.”
Looking forward, Splash Music plans to expand its training datasets tenfold, explore multimodal audio/video generation, and additionally collaborate with the GenAIIC on additional R&D and its next version of HummingLM FM.
Try creating your own music using Splash Music, and learn more about Amazon SageMaker HyperPod and AWS Trainium.
About the authors
 Sheldon Liu is an Senior Applied Scientist, ANZ Tech Lead at the AWS Generative AI Innovation Center. He partners with AWS customers across diverse industries to develop and implement innovative generative AI solutions, accelerating their AI adoption journey while driving significant business outcomes.
Sheldon Liu is an Senior Applied Scientist, ANZ Tech Lead at the AWS Generative AI Innovation Center. He partners with AWS customers across diverse industries to develop and implement innovative generative AI solutions, accelerating their AI adoption journey while driving significant business outcomes.
 Mahsa Paknezhad is a Deep Learning Architect and a key member of the AWS Generative AI Innovation Center. She works closely with enterprise clients to design, implement, and optimize cutting-edge generative AI solutions. With a focus on scalability and production readiness, Mahsa helps organizations across diverse industries harness advanced Generative AI models to achieve meaningful business outcomes.
Mahsa Paknezhad is a Deep Learning Architect and a key member of the AWS Generative AI Innovation Center. She works closely with enterprise clients to design, implement, and optimize cutting-edge generative AI solutions. With a focus on scalability and production readiness, Mahsa helps organizations across diverse industries harness advanced Generative AI models to achieve meaningful business outcomes.
 Xiaoning Wang is a machine learning engineer at the AWS Generative AI Innovation Center. He specializes in large language model training and optimization on AWS Trainium and Inferentia, with experience in distributed training, RAG, and low-latency inference. He works with enterprise customers to build scalable generative AI solutions that drive real business impact.
Xiaoning Wang is a machine learning engineer at the AWS Generative AI Innovation Center. He specializes in large language model training and optimization on AWS Trainium and Inferentia, with experience in distributed training, RAG, and low-latency inference. He works with enterprise customers to build scalable generative AI solutions that drive real business impact.
 Tianyu Liu is an applied scientist at the AWS Generative AI Innovation Center. He partners with enterprise customers to design, implement, and optimize cutting-edge generative AI models, advancing innovation and helping organizations achieve transformative results with scalable, production-ready AI solutions.
Tianyu Liu is an applied scientist at the AWS Generative AI Innovation Center. He partners with enterprise customers to design, implement, and optimize cutting-edge generative AI models, advancing innovation and helping organizations achieve transformative results with scalable, production-ready AI solutions.
 Xuefeng Liu leads a science team at the AWS Generative AI Innovation Center in the Asia Pacific regions. His team partners with AWS customers on generative AI projects, with the goal of accelerating customers’ adoption of generative AI.
Xuefeng Liu leads a science team at the AWS Generative AI Innovation Center in the Asia Pacific regions. His team partners with AWS customers on generative AI projects, with the goal of accelerating customers’ adoption of generative AI.
 Daniel Wirjo is a Solutions Architect at AWS, focused on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS. Outside of work, Daniel enjoys taking walks with a coffee in hand, appreciating nature, and learning new ideas.
Daniel Wirjo is a Solutions Architect at AWS, focused on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS. Outside of work, Daniel enjoys taking walks with a coffee in hand, appreciating nature, and learning new ideas.