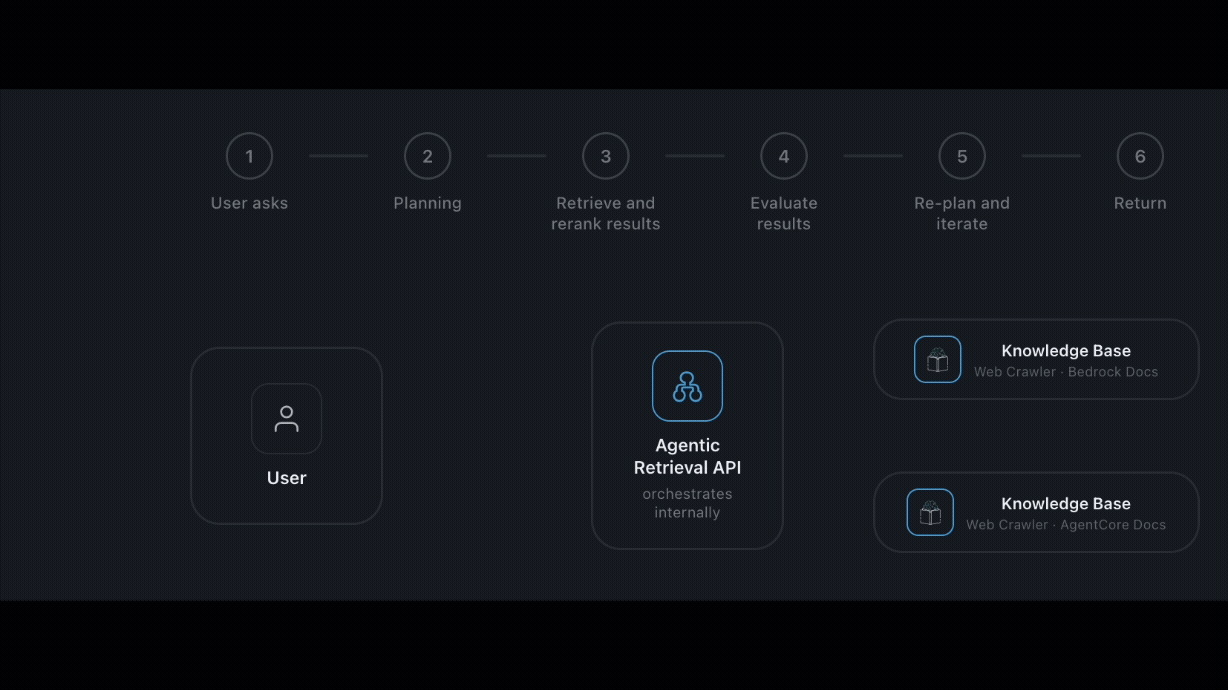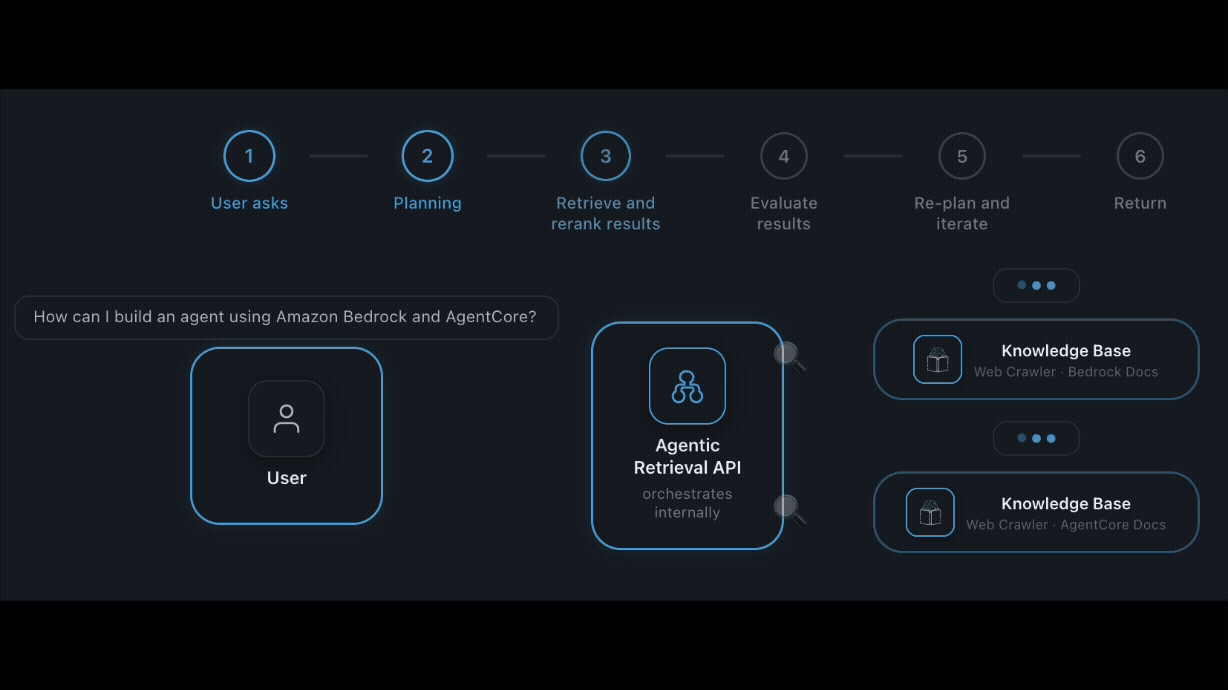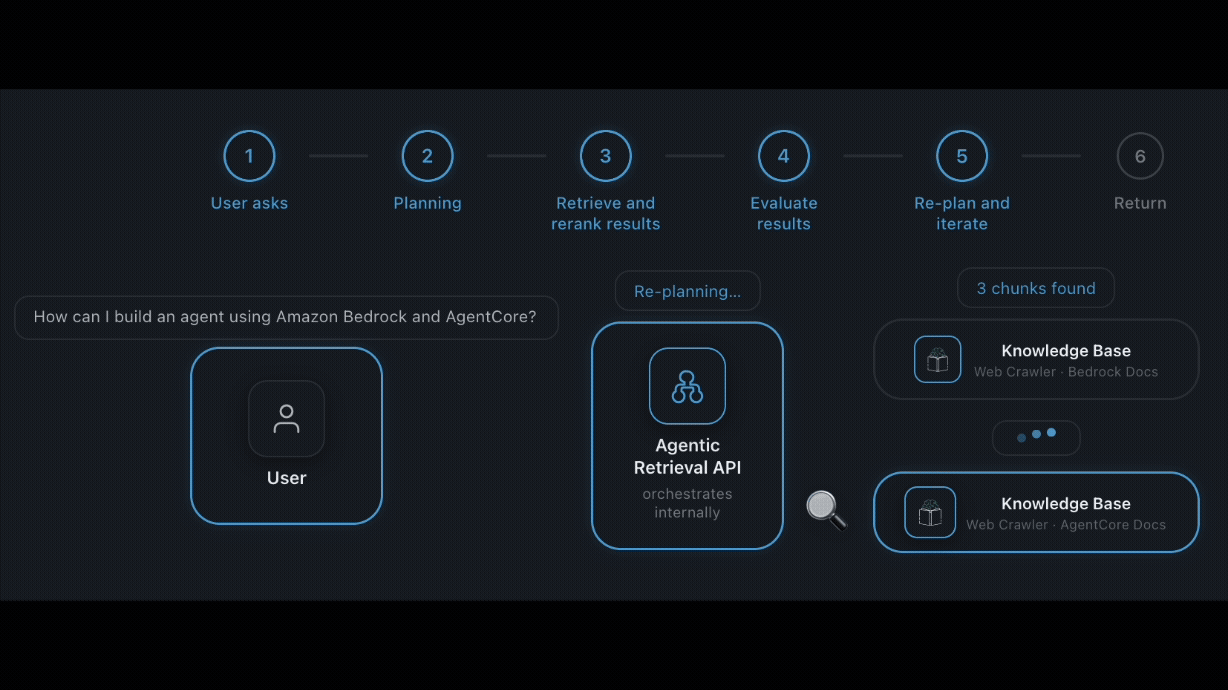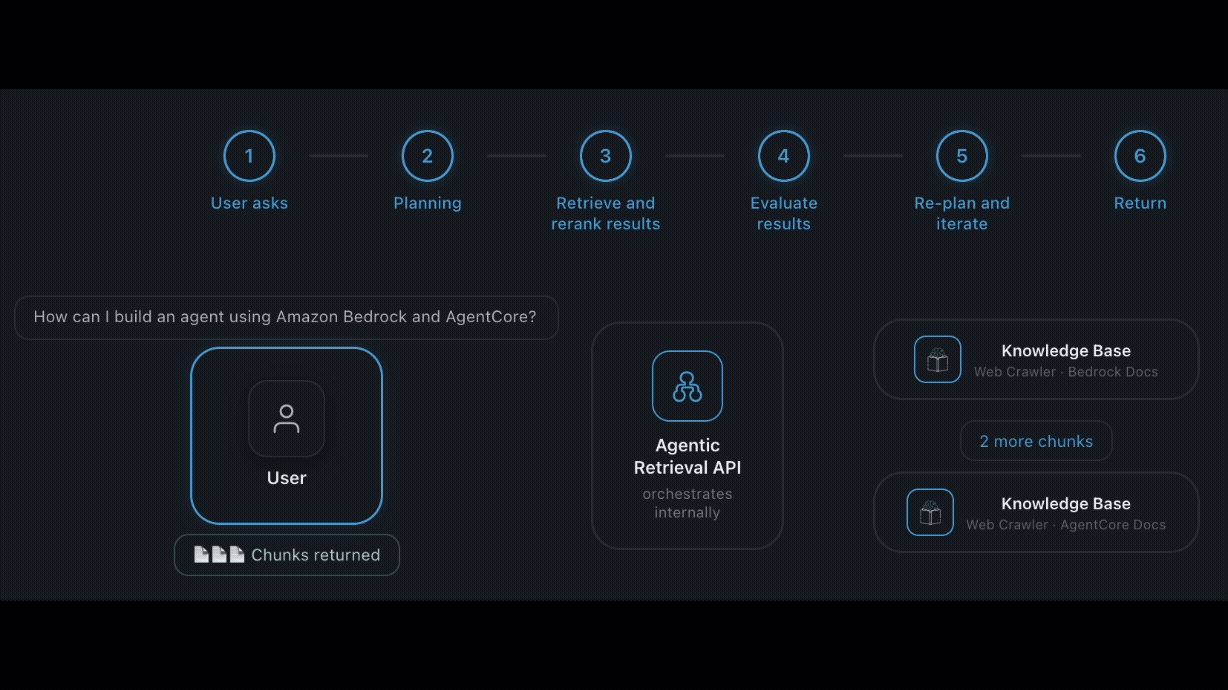
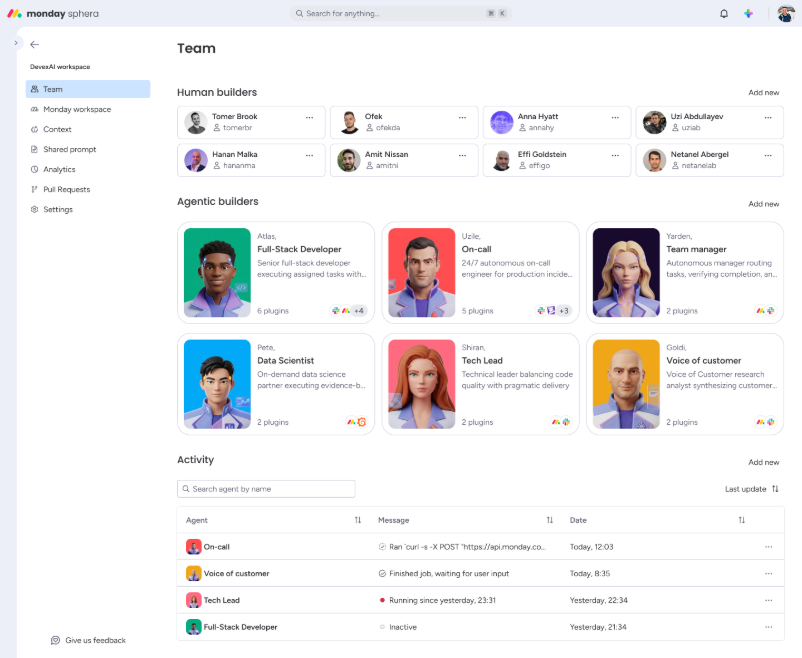
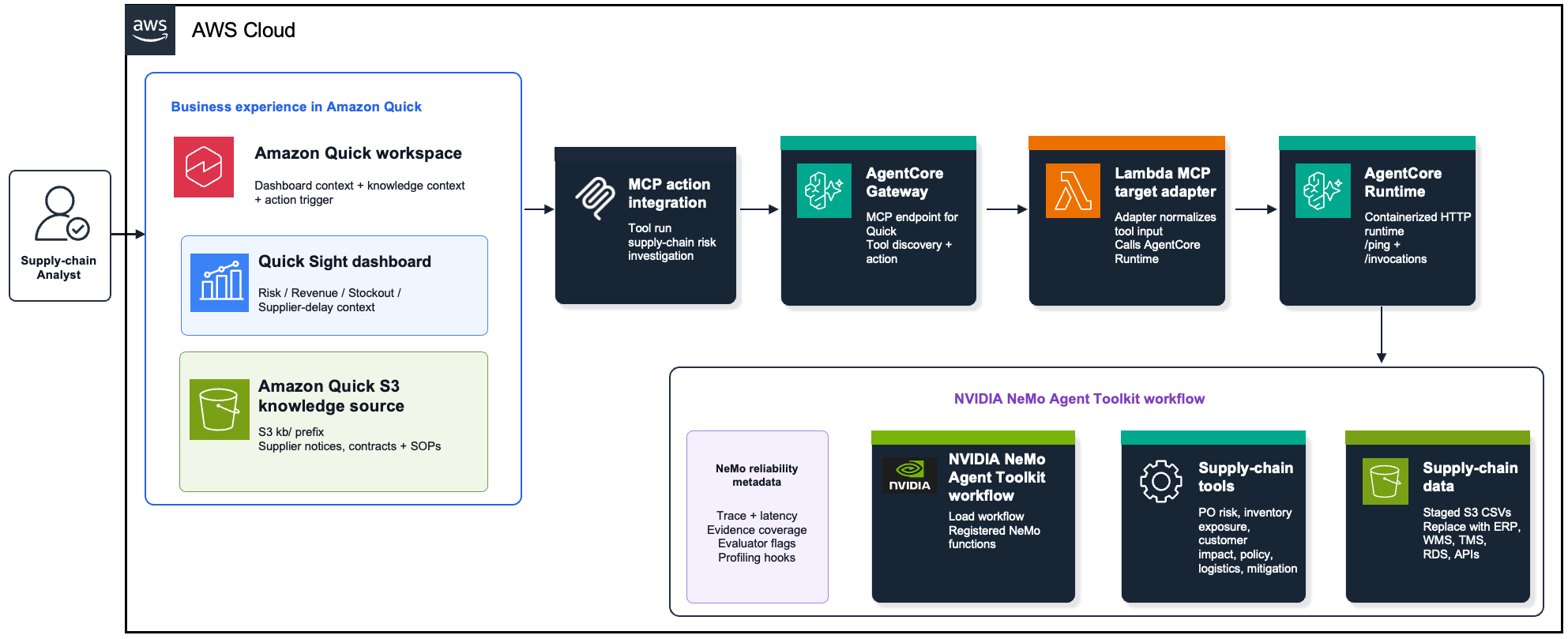
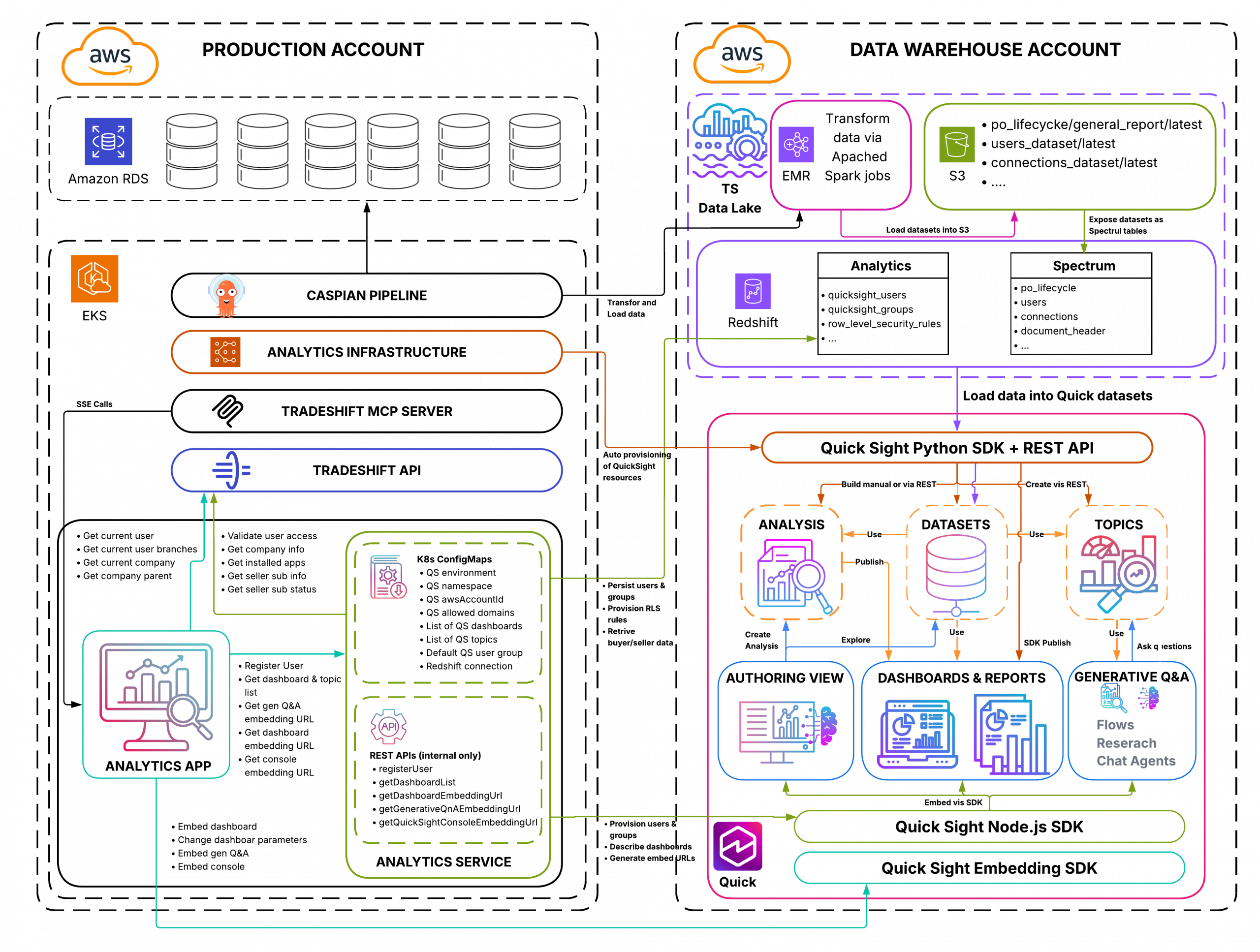
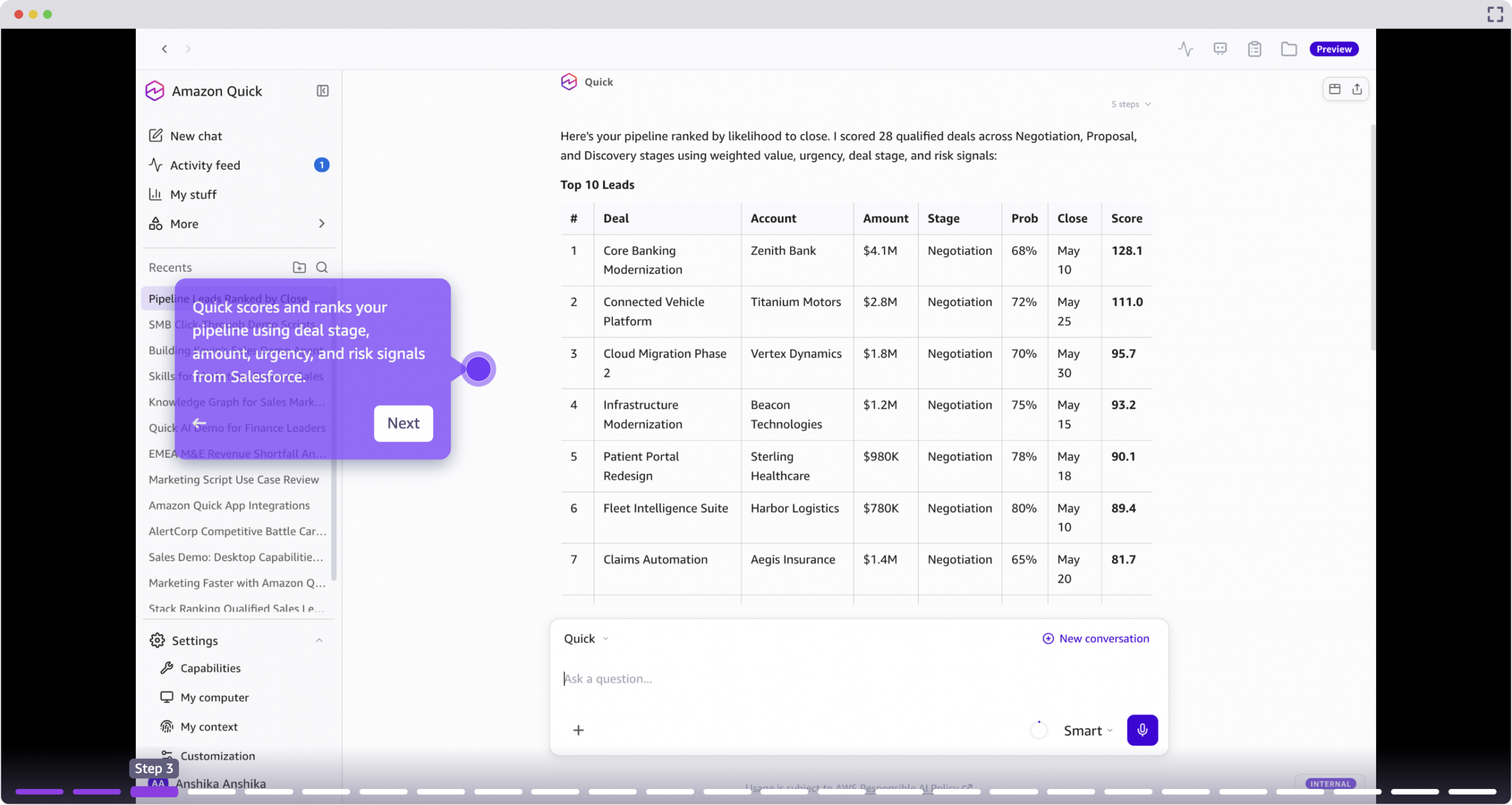
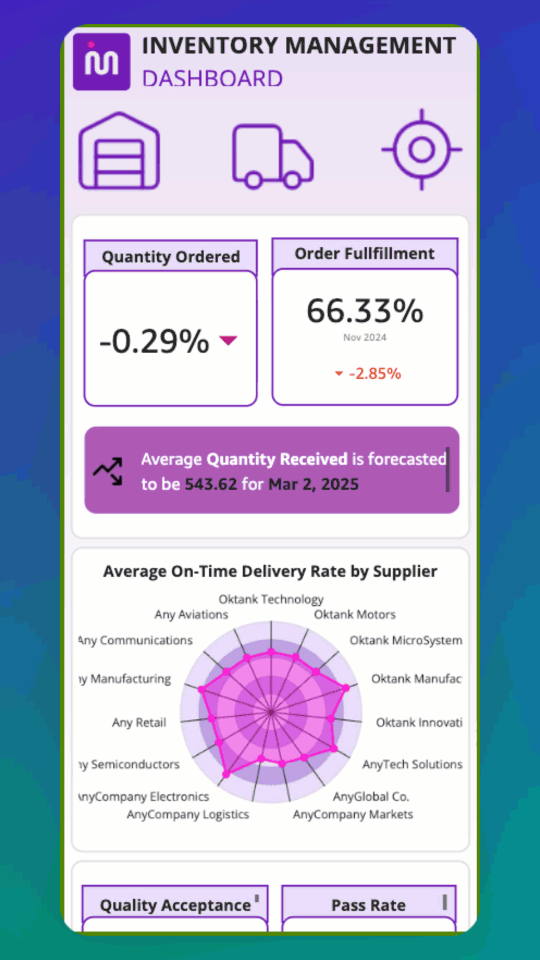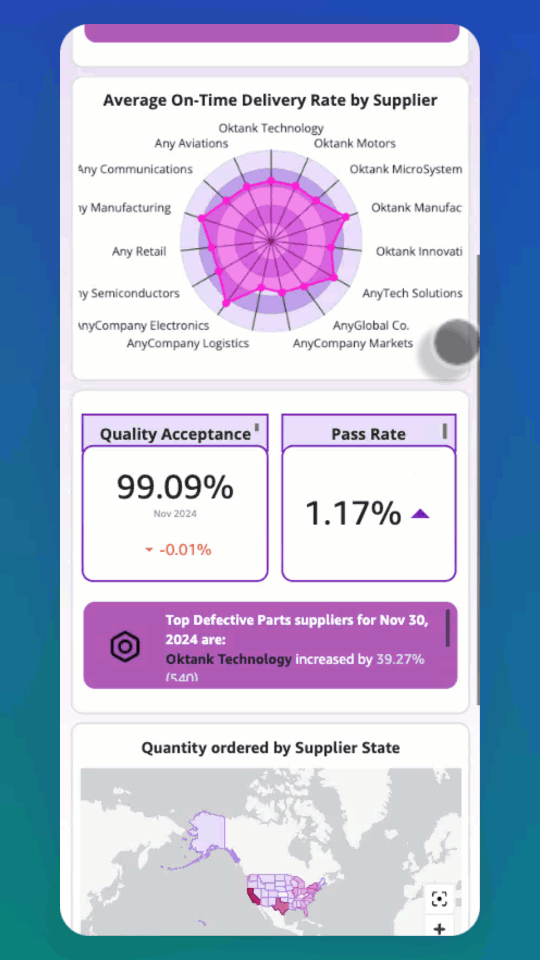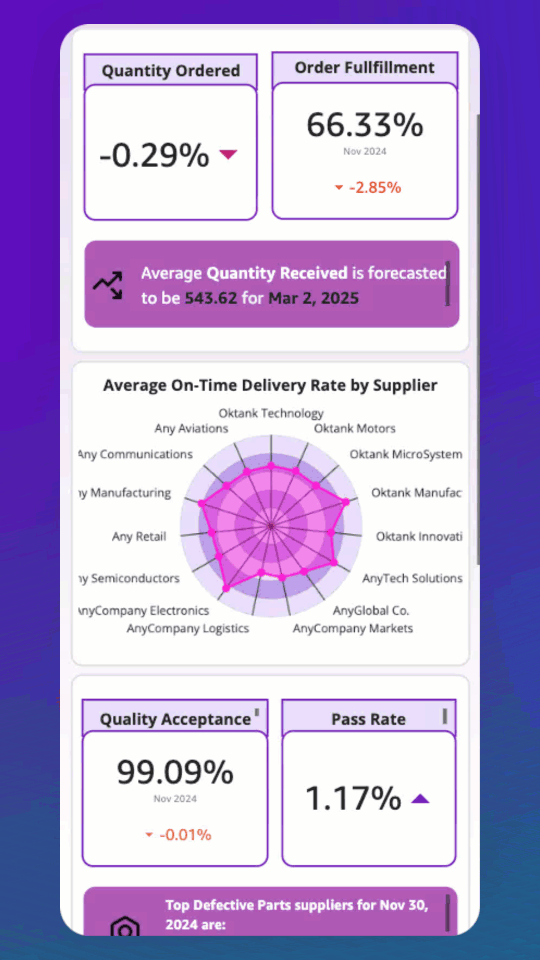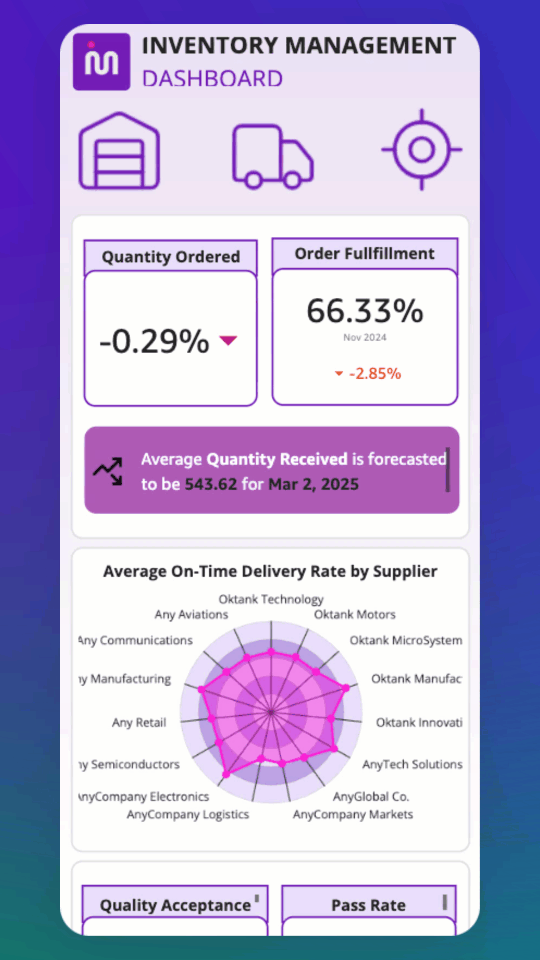
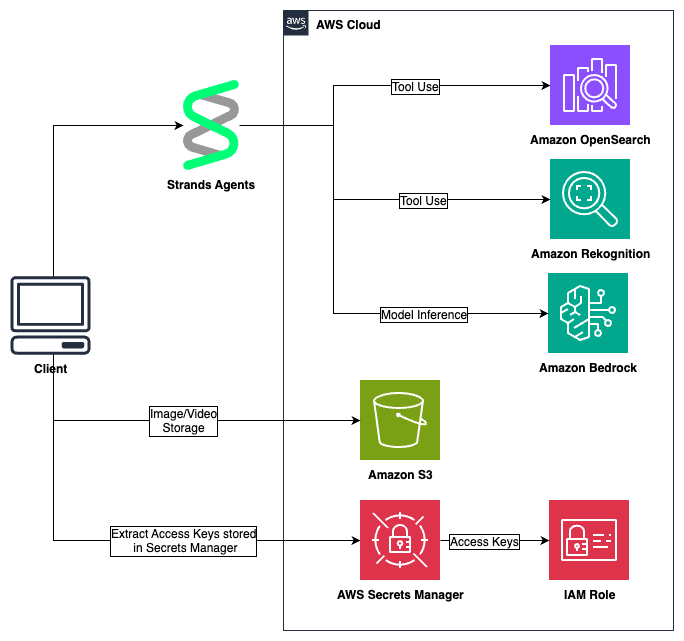
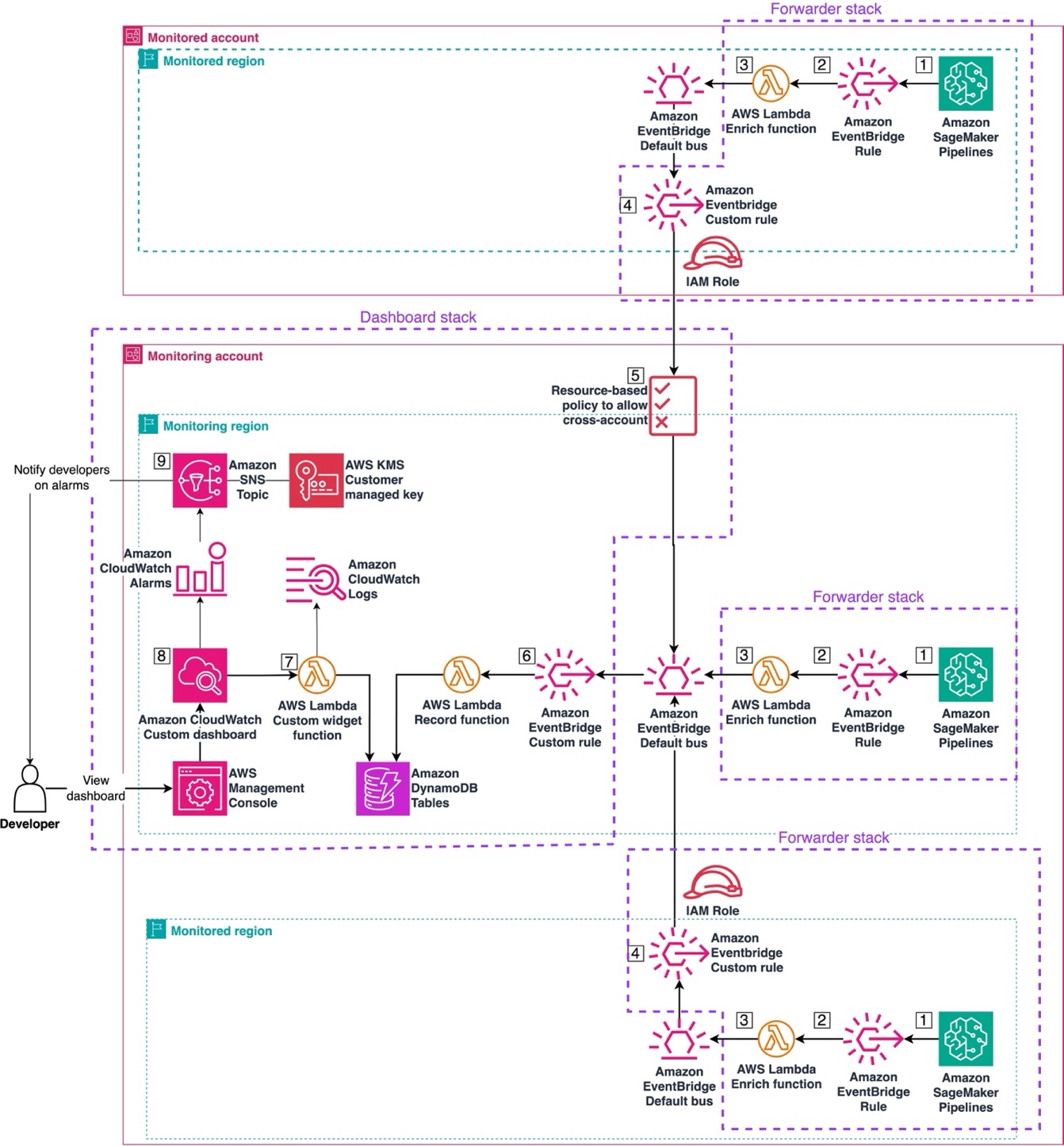
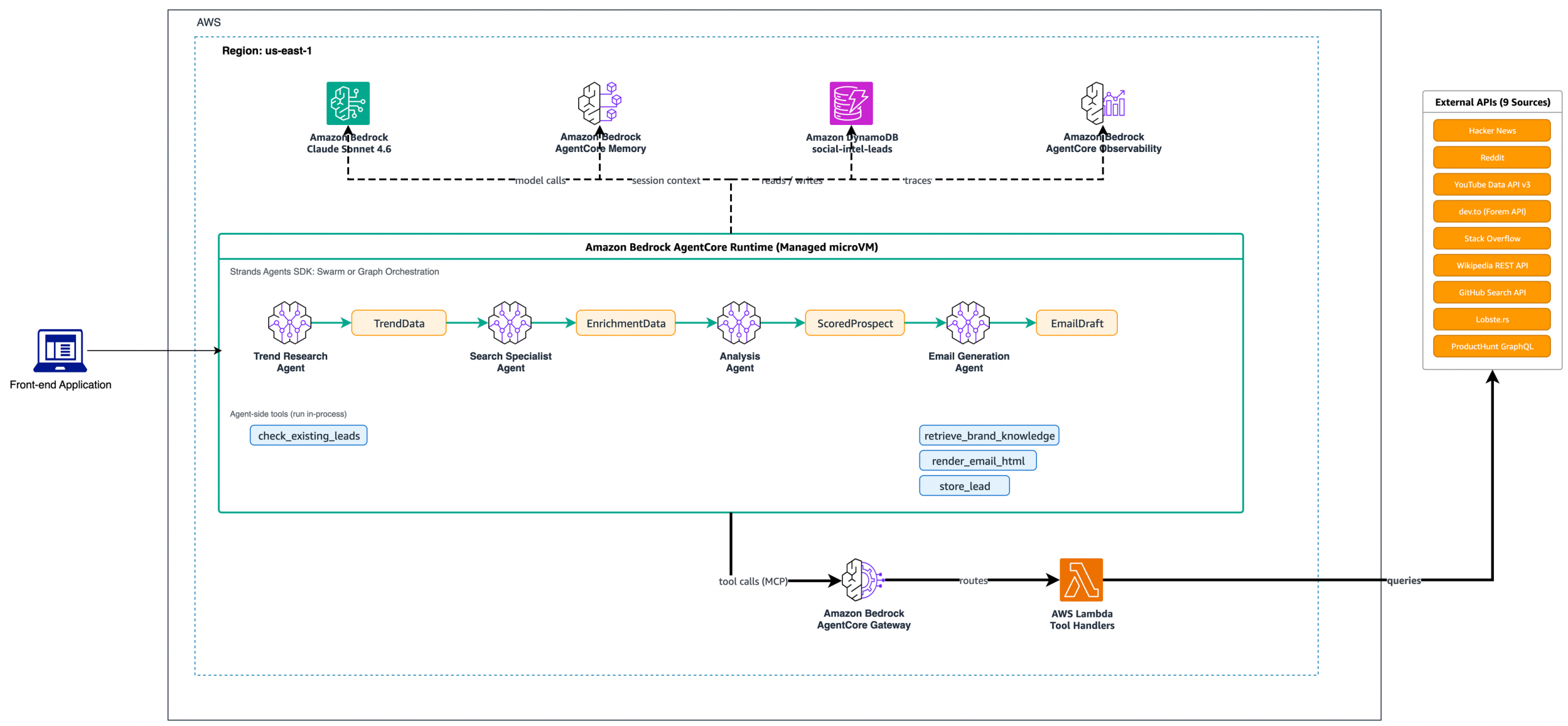
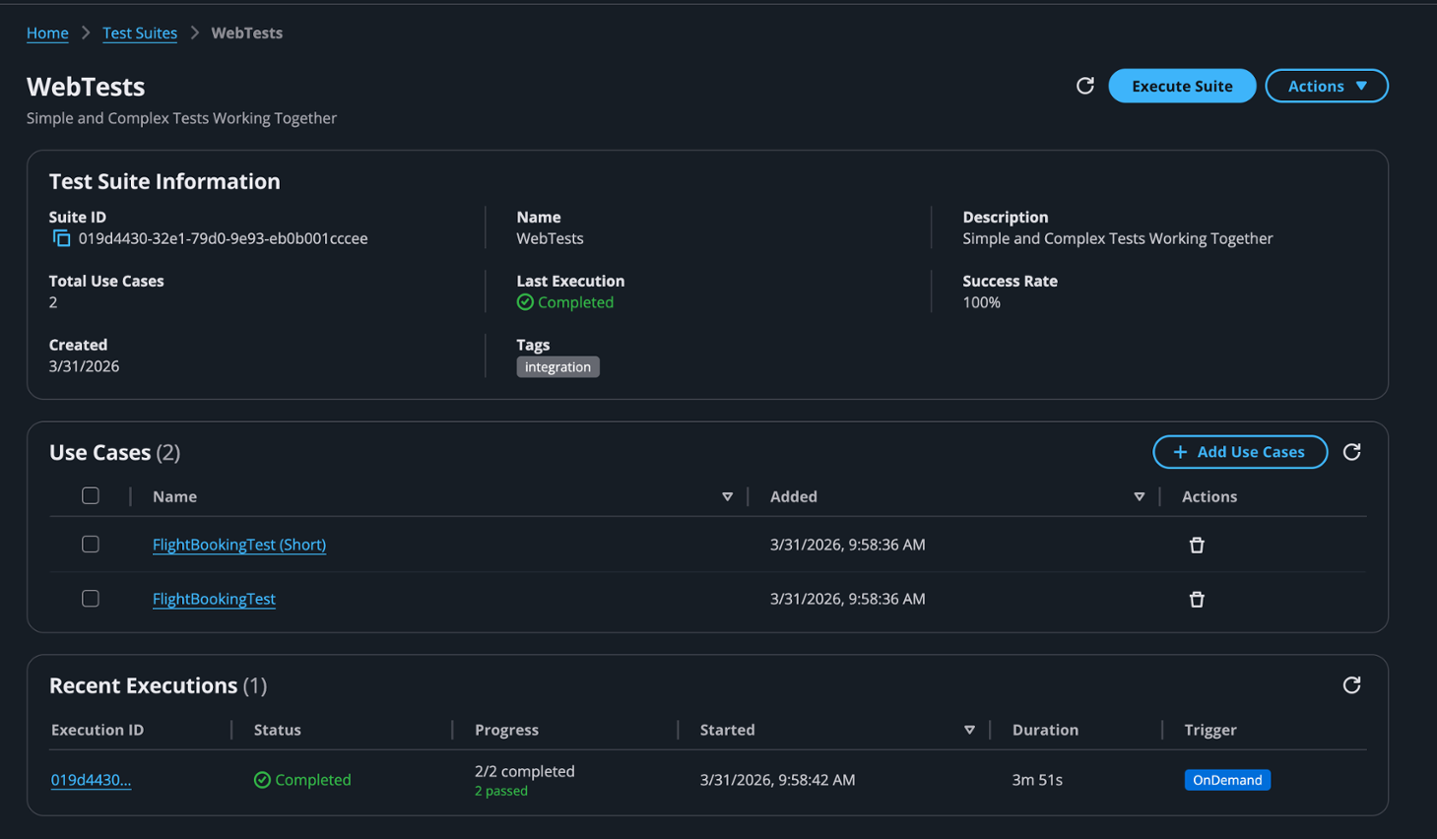
Introducing Claude Opus 5 on AWS: Anthropic’s most capable Opus model
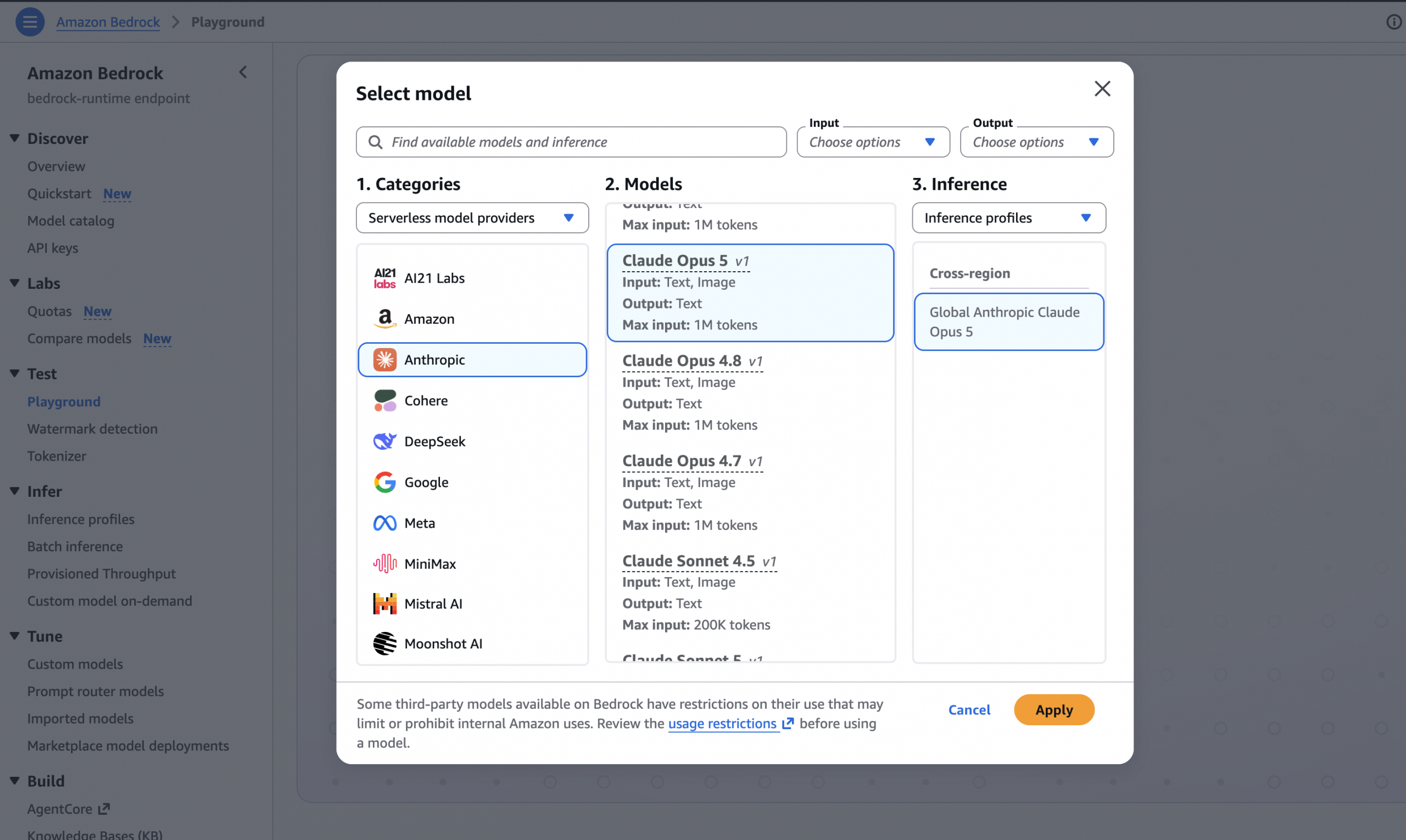
Today, we announce the availability of Claude Opus 5 on Amazon Bedrock and Claude Platform on AWS. Claude Opus 5 is Anthropic’s most advanced Opus model and the first in the fifth generation. It is a meaningful step forward, providing improvements across the workflows that teams run in production such as agentic coding, knowledge work, … Read more