Table of Links
-
Related work
-
Our method
B. More ablations
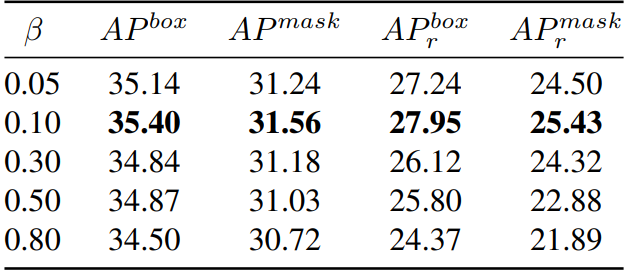
Momentum Coefficient β. In Algorithm 3, we introduce a momentum coefficient β to update the grad cache. Here we explore the effect of different β on the model performance. A larger beta signifies a greater focus on global information, while a smaller beta indicates a higher attention to the current test batch Ub. Detailed results are presented in Table 9. Observations suggest that when β is 0.1, the performance is the best, which is also the β we finally adopted.
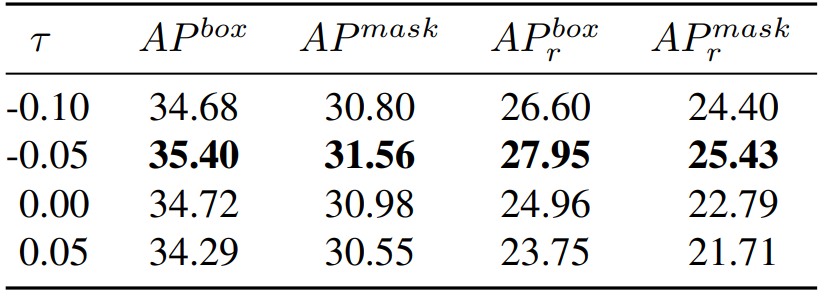
Contribution threshold τ. In Algorithm 3, we incorporate a contribution threshold τ , intended for filtering the produced data. Here we investigate the impact of varying values of τ on the model’s performance. The larger τ implies a stricter filtration of the generated data, while the smaller τ signifies a looser filtering of the generated data. The specific results are shown in Table 10. We can see the performance is optimal when τ equals -0.05, which is also the τ we eventually settle on for our final model.
Online learning vs. Offline learning We compare online learning and offline learning under different iterations. The result is shown in Figure 9.
:::info
Authors:
(1) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(2) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weian Mao, Zhejiang University, China and The University of Adelaide, Australia;
(6) Xiaogang Xu, Zhejiang University, China;
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
:::
:::info
This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::