Table of Links
Supplementary Material
-
Image matting
-
Video matting
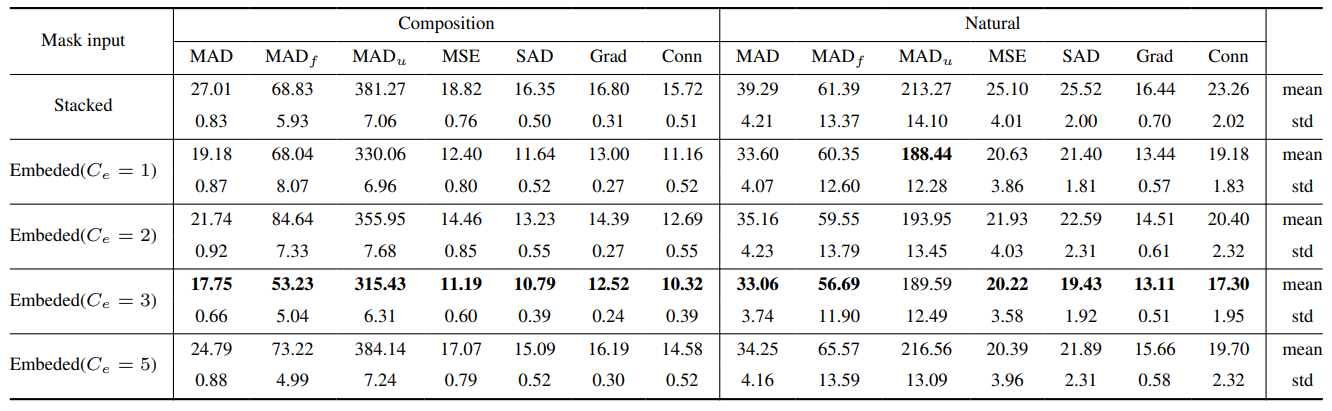
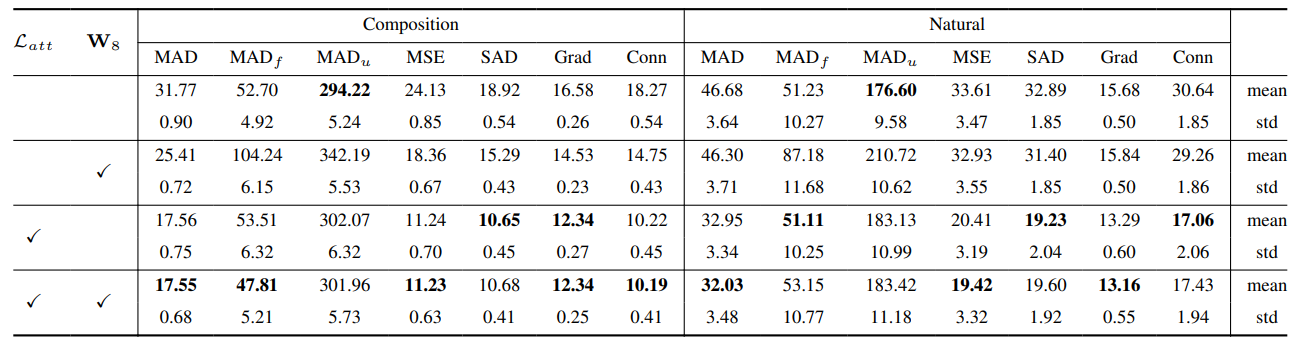
8.2. Training details


:::info
Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::