Table of Links
6 Phi-3-Vision
A Example prompt for benchmarks
4 Safety
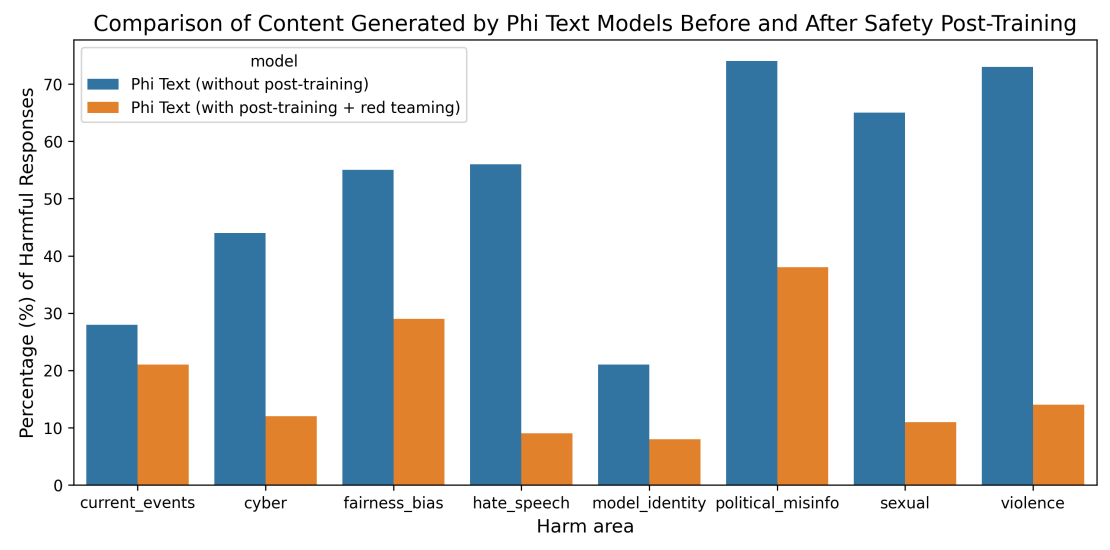
Phi-3-mini was developed in accordance with Microsoft’s responsible AI principles. The overall approach consisted of safety alignment in post-training, red-teaming, automated testing and evaluations across dozens of RAI harm categories. Helpfulness and harmlessness preference datasets [BJN+ 22, JLD+ 23] with modifications inspired by [BSA+ 24] and multiple in-house generated datasets were leveraged to address the RAI harm categories in safety post-training. An independent red team at Microsoft iteratively examined phi-3-mini to further identify areas of improvement during the post-training process. Based on their feedback, we curated additional datasets tailored to address their insights, thereby refining the post-training dataset. This process resulted in significant decrease of harmful response rates, as shown in Figure 4.
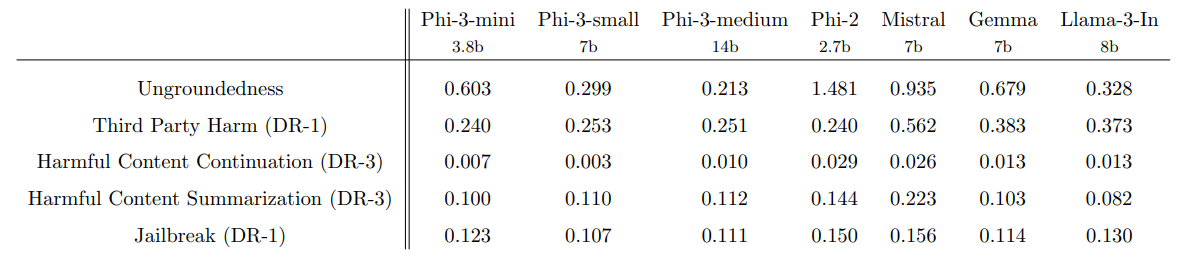
The safety alignment of phi-3-small and phi-3-medium was conducted by undergoing the same red-teaming process, utilizing identical datasets, and incorporating a slightly larger number of samples. Table 1 shows the results of in-house RAI benchmarks [MHJ+ 23] for phi-3 models compared to phi-2 [JBA+ 23], Mistral-7b-v0.1 [JSM+ 23], Gemma 7b [TMH+ 24], and Llama-3-instruct-8b [AI]. This benchmark utilized GPT-4 to simulate multi-turn conversations in five different categories and to evaluate the model responses. Ungroundedness between 0 (fully grounded) and 4 (not grounded) measures if the information in a response is based on a given prompt. In other categories, responses were evaluated in terms of the severity of harmfulness from 0 (no harm) to 7 (extreme harm) and the defect rates (DR-x) were computed as the percentage of samples with the severity score being greater than or equal to x.
:::info
Authors:
(1) Marah Abdin;
(2) Sam Ade Jacobs;
(3) Ammar Ahmad Awan;
(4) Jyoti Aneja;
(5) Ahmed Awadallah;
(6) Hany Awadalla;
(7) Nguyen Bach;
(8) Amit Bahree;
(9) Arash Bakhtiari;
(10) Jianmin Bao;
(11) Harkirat Behl;
(12) Alon Benhaim;
(13) Misha Bilenko;
(14) Johan Bjorck;
(15) Sébastien Bubeck;
(16) Qin Cai;
(17) Martin Cai;
(18) Caio César Teodoro Mendes;
(19) Weizhu Chen;
(20) Vishrav Chaudhary;
(21) Dong Chen;
(22) Dongdong Chen;
(23) Yen-Chun Chen;
(24) Yi-Ling Chen;
(25) Parul Chopra;
(26) Xiyang Dai;
(27) Allie Del Giorno;
(28) Gustavo de Rosa;
(29) Matthew Dixon;
(30) Ronen Eldan;
(31) Victor Fragoso;
(32) Dan Iter;
(33) Mei Gao;
(34) Min Gao;
(35) Jianfeng Gao;
(36) Amit Garg;
(37) Abhishek Goswami;
(38) Suriya Gunasekar;
(39) Emman Haider;
(40) Junheng Hao;
(41) Russell J. Hewett;
(42) Jamie Huynh;
(43) Mojan Javaheripi;
(44) Xin Jin;
(45) Piero Kauffmann;
(46) Nikos Karampatziakis;
(47) Dongwoo Kim;
(48) Mahoud Khademi;
(49) Lev Kurilenko;
(50) James R. Lee;
(51) Yin Tat Lee;
(52) Yuanzhi Li;
(53) Yunsheng Li;
(54) Chen Liang;
(55) Lars Liden;
(56) Ce Liu;
(57) Mengchen Liu;
(58) Weishung Liu;
(59) Eric Lin;
(60) Zeqi Lin;
(61) Chong Luo;
(62) Piyush Madan;
(63) Matt Mazzola;
(64) Arindam Mitra;
(65) Hardik Modi;
(66) Anh Nguyen;
(67) Brandon Norick;
(68) Barun Patra;
(69) Daniel Perez-Becker;
(70) Thomas Portet;
(71) Reid Pryzant;
(72) Heyang Qin;
(73) Marko Radmilac;
(74) Corby Rosset;
(75) Sambudha Roy;
(76) Olatunji Ruwase;
(77) Olli Saarikivi;
(78) Amin Saied;
(79) Adil Salim;
(80) Michael Santacroce;
(81) Shital Shah;
(82) Ning Shang;
(83) Hiteshi Sharma;
(84) Swadheen Shukla;
(85) Xia Song;
(86) Masahiro Tanaka;
(87) Andrea Tupini;
(88) Xin Wang;
(89) Lijuan Wang;
(90) Chunyu Wang;
(91) Yu Wang;
(92) Rachel Ward;
(93) Guanhua Wang;
(94) Philipp Witte;
(95) Haiping Wu;
(96) Michael Wyatt;
(97) Bin Xiao;
(98) Can Xu;
(99) Jiahang Xu;
(100) Weijian Xu;
(101) Sonali Yadav;
(102) Fan Yang;
(103) Jianwei Yang;
(104) Ziyi Yang;
(105) Yifan Yang;
(106) Donghan Yu;
(107) Lu Yuan;
(108) Chengruidong Zhang;
(109) Cyril Zhang;
(110) Jianwen Zhang;
(111) Li Lyna Zhang;
(112) Yi Zhang;
(113) Yue Zhang;
(114) Yunan Zhang;
(115) Xiren Zhou.
:::
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::