Table of Links
- Abstract and Introduction
- Related Work
- Problem Definition
- Method
- Experiments
- Conclusion and References
A. Appendix
A.1. Full Prompts and A.2 ICPL Details
A.6 Human-in-the-Loop Preference
A APPENDIX
We would suggest visiting https://sites.google.com/view/few-shot-icpl/home for more information and videos.
A.1 FULL PROMPTS

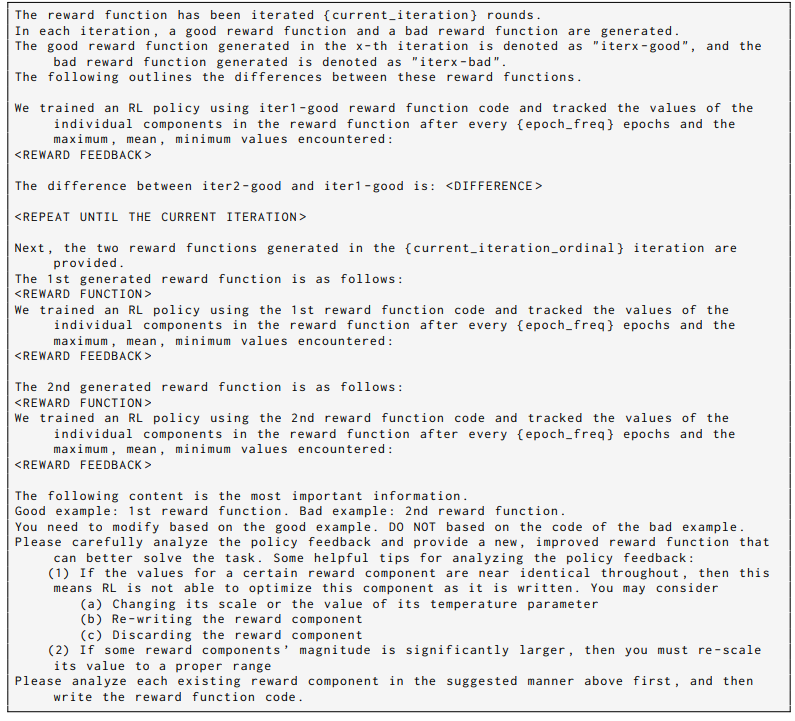


A.2 ICPL DETAILS
The full pseudocode of ICPL is listed in Algo. 2.
:::info
Authors:
(1) Chao Yu, Tsinghua University;
(2) Hong Lu, Tsinghua University;
(3) Jiaxuan Gao, Tsinghua University;
(4) Qixin Tan, Tsinghua University;
(5) Xinting Yang, Tsinghua University;
(6) Yu Wang, with equal advising from Tsinghua University;
(7) Yi Wu, with equal advising from Tsinghua University and the Shanghai Qi Zhi Institute;
(8) Eugene Vinitsky, with equal advising from New York University (zoeyuchao@gmail.com).
:::
:::info
This paper is available on arxiv under CC 4.0 license.
:::