Table of Links
-
4.1 Multi-hop Reasoning Performance
4.2 Reasoning with Distractors
A. Dataset
B. In-context Reasoning with Distractors
E. Experiments with Large Language Models
2 Background
Notation We use f : X × θ → Y to refer to parameterised functions in which X is the set of possible inputs and θ are their possible weights (parameters). We use fθ : x 7→ f(x, θ) to easily refer to any f with a given set of parameters θ. We describe reasoning problems using tuples (K, x, y∗ , Y ) such that y ∈ Y is the correct answer for the question x given facts K, and use D to refer to sets of such problems. When it is clear from context, we drop Y and use only (K, x, y∗ ).
Language Modeling and Memorization In the causal language modeling (CLM) objective, a parameterized model fθ is trained to estimate the conditional probabilities of each token in a sequence given its predecessors: p(xt|x) Specifically, we train fθ to approximate p using the CLM loss:
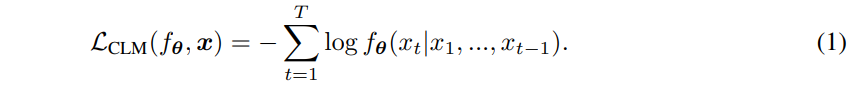
This training objective allows language models to memorize individual training examples [10, 11], and we will exploit this ability to memorize and draw on contextual knowledge in our work.

:::info
Authors:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)’;
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::