Text-to-SQL generation remains a persistent challenge in enterprise AI applications, particularly when working with custom SQL dialects or domain-specific database schemas. While foundation models (FMs) demonstrate strong performance on standard SQL, achieving production-grade accuracy for specialized dialects requires fine-tuning. However, fine-tuning introduces an operational trade-off: hosting custom models on persistent infrastructure incurs continuous costs, even during periods of zero utilization.
The on-demand inference of Amazon Bedrock with fine-tuned Amazon Nova Micro models offers an alternative. By combining the efficiency of LoRA (Low-Rank Adaptation) fine-tuning with serverless and pay-per-token inference, organizations can achieve custom text-to-SQL capabilities without the overhead cost incurred by persistent model hosting. Despite the additional inference time overhead of applying LoRA adapters, testing demonstrated latency suitable for interactive text-to-SQL applications, with costs scaling by usage rather than provisioned capacity.
In this post, we demonstrate two approaches to fine-tune Amazon Nova Micro for custom SQL dialect generation to deliver both cost efficiency and production ready performance. Our example workload maintained a cost of $0.80 monthly with a sample traffic of 22,000 queries per month, which resulted in costs savings compared to a persistently hosted model infrastructure.
Prerequisites
To deploy these solutions, you will need the following:
- An AWS account with billing enabled
- Standard IAM permissions and role configured to access:
- Amazon Bedrock Nova Micro model
- Amazon SageMaker AI
- Amazon Bedrock Model customization
- Quota for ml.g5.48xl instance for Amazon SageMaker AI training.
Solution overview
The solution consists of the following high-level steps:
- Prepare your custom SQL training dataset with I/O pairs specific to your organization’s SQL dialect and business requirements.
- Start the fine-tuning process on Amazon Nova Micro model using your prepared dataset and selected fine-tuning approach.
- Amazon Bedrock model customization for streamlined deployment
- Amazon SageMaker AI for fine-grained training customization and control
- Deploy the custom model on Amazon Bedrock to use on-demand inference, removing infrastructure management while paying only for token usage.
- Validate model performance with test queries specific to your custom SQL dialect and business use cases.
To demonstrate this approach in practice, we provide two complete implementation paths that address different organizational needs. The first uses the managed model customization of Amazon Bedrock for teams prioritizing simplicity and rapid deployment. The second uses Amazon SageMaker AI training jobs for organizations requiring more granular control over hyperparameters and training infrastructure. Both implementations share the same data preparation pipeline and deploy to Amazon Bedrock for on-demand inference. The following are links to each GitHub code sample:
The following architecture diagram illustrates the end-to-end workflow, which encompasses data preparation, both fine-tuning approaches, and the Bedrock deployment path that enables serverless inference.
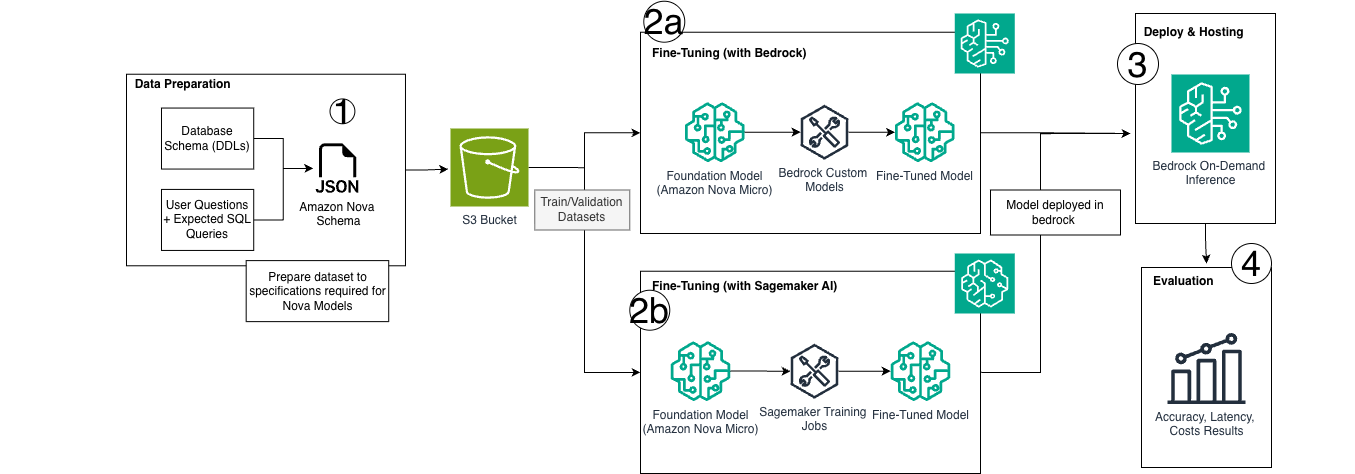
1. Dataset preparation
Our demonstration uses the sql-create-context dataset. This dataset is a curated combination of WikiSQL and Spider datasets containing over 78,000 examples of natural language questions paired with SQL queries across diverse database schemas. This dataset provides an ideal foundation for text-to-SQL fine-tuning due to its variety in query complexity, from simple SELECT statements to complex multi-table joins with aggregations.
Data formatting and structure
The Training data is structured as outlined in the documentation. This involves creating JSONL files that contain system prompt instructions paired with user queries and corresponding SQL responses of varying complexity. The formatted training dataset is then split into training and validation sets, stored as JSONL files, and uploaded to Amazon Simple Storage Service (Amazon S3) for the fine-tuning process.
Sample Converted Record
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "You are a powerful text-to-SQL model. Your job is to answer questions about a database. You can use the following table schema for context: CREATE TABLE head (age INTEGER)"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "Return the SQL query that answers the following question: How many heads of the departments are older than 56 ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
]
}Amazon Bedrock fine-tuning approach
The model customization of Amazon Bedrock provides a streamlined, fully managed approach to fine-tuning Amazon Nova models without the need to provision or manage training infrastructure. This method is ideal for teams seeking rapid iteration and minimal operational overhead while achieving custom model performance tailored to their text-to-SQL use case.
Using the customization capabilities of Amazon Bedrock, training data is uploaded to Amazon S3, and fine-tuning jobs are configured through the AWS console or API. AWS then handles the underlying training infrastructure. The resulting custom model can be deployed using on-demand inference, maintaining the same token-based pricing as the base Nova Micro model with no additional markup making it a cost-effective solution for variable workloads.This approach is well-suited when you need to quickly customize a model for custom SQL dialects without managing ML infrastructure, want to minimal operational complexity, or need serverless inference with automatic scaling.
2a. Creating a Fine-tuning Job Using Amazon Bedrock
Amazon Bedrock supports fine-tuning using both the AWS Console and AWS SDK for Python (Boto3). The AWS documentation contains general guidance on how to submit a training job with both approaches. In our implementation, we used the AWS SDK for Python (Boto3). Refer to the sample notebook in our GitHub samples repository to view our step-by-step implementation.
Configure hyperparameters
After selecting the model to fine-tune, we then configure our hyperparameters for our use case. For Amazon Nova Micro fine-tuning on Amazon Bedrock, the following hyperparameters can be customized to optimize our text-to-SQL model:
| Parameter | Range/Constraints | Purpose | What we used |
| Epochs | 1–5 | Number of complete passes through the training dataset | 5 epochs |
| Batch Size | Fixed at 1 | Number of samples processed before updating model weights | 1 (fixed for Nova Micro) |
| Learning Rate | 0.000001–0.0001 | Step size for gradient descent optimization | 0.00001 for stable convergence |
| Learning Rate Warmup Steps | 0–100 | Number of steps to gradually increase learning rate | 10 |
Note: These hyperparameters were optimized for our specific dataset and use case. Optimal values may vary based on dataset size and complexity. In the sample dataset, this configuration provided improved balance between model accuracy and training time, completing in approximately 2-3 hours.
Analyzing training metrics
Amazon Bedrock automatically generates training and validation metrics, which are stored in your specified S3 output location. These metrics include:
- Training loss: Measures how well the model fits the training data
- Validation loss: Indicates generalization performance on unseen data
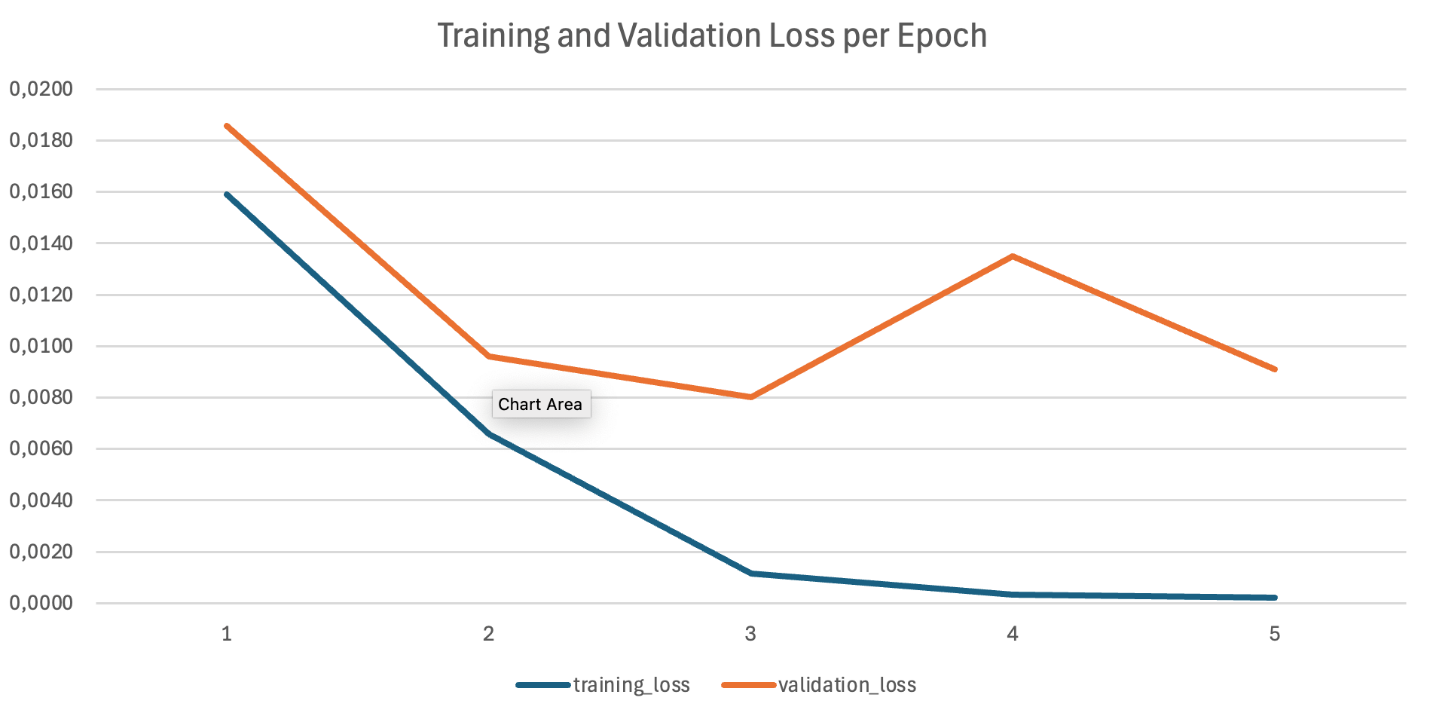
The training and validation loss curves show successful training: both decrease consistently, follow similar patterns, and converge to comparable final values.
3a. Deploy with on-demand inference
After your fine-tuning job completes successfully, you can deploy your custom Nova Micro model using on-demand inference. This deployment option provides automatic scaling and pay-per-token pricing, making it ideal for variable workloads without the need to provision dedicated compute resources.
Invoking the custom Nova Micro model
After deployment, you can invoke your custom text-to-SQL model by using the deployment ARN as the model ID in the Amazon Bedrock Converse API.
# Use the deployment ARN as the model ID
deployment_arn = "arn:aws:bedrock:us-east-1:<account-id>:deployment/<deployment-id>"
# Prepare the inference request
response = bedrock_runtime.converse(
modelId=deployment_arn,
messages=[
{
"role": "user",
"content": [
{
"text": """Database schema:
CREATE TABLE sales (
id INT,
product_name VARCHAR(100),
category VARCHAR(50),
revenue DECIMAL(10,2),
sale_date DATE
);
Question: What are the top 5 products by revenue in the Electronics category?"""
}
]
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1, # Low temperature for deterministic SQL generation
"topP": 0.9
}
)
# Extract the generated SQL query
sql_query = response['output']['message']['content']['text']
print(f"Generated SQL:
{sql_query}")Amazon SageMaker AI fine-tuning approach
While the Amazon Bedrock approach streamlines model customization through a managed training experience, organizations seeking deeper optimization control might benefit from the SageMaker AI approach. SageMaker AI provides extensive control over training parameters that can significantly impact efficiency and model performance. You can adjust batch size for speed and memory optimzation, fine-tune dropout settings across layers to prevent overfitting, and configure learning rate schedules for training stability. For LoRA fine-tuning specifically, You can use SageMaker AI to customize scaling factors and regularization parameters with different settings optimized for multimodal versus text-only datasets. Additionally, you can adjust the context window size and optimizer settings to match your specific use case requirements. See the following notebook for the complete code sample.
1b. Data preparation and upload
The data preparation and upload process for the SageMaker AI fine-tuning approach is identical to the Amazon Bedrock implementation. Both approaches convert the SQL dataset to the bedrock-conversation-2024 schema format, split the data into training and test sets, and upload the JSONL files directly to S3.
# S3 prefix for training data
training_input_path = f's3://{sess.default_bucket()}/datasets/nova-sql-context'
# Upload datasets to S3
train_s3_path = sess.upload_data(
path='data/train_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
test_s3_path = sess.upload_data(
path='data/test_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
print(f'Training data uploaded to: {train_s3_path}')
print(f'Test data uploaded to: {test_s3_path}')2b. Creating a fine-tuning job using Amazon SageMaker AI
Select the model ID, recipe, and image URI:
# Nova configuration
model_id = "nova-micro/prod"
recipe = "https://raw.githubusercontent.com/aws/sagemaker-hyperpod-recipes/refs/heads/main/recipes_collection/recipes/fine-tuning/nova/nova_1_0/nova_micro/SFT/nova_micro_1_0_g5_g6_48x_gpu_lora_sft.yaml"
instance_type = "ml.g5.48xlarge"
instance_count = 1
# Nova-specific image URI
image_uri = f"708977205387.dkr.ecr.{sess.boto_region_name}.amazonaws.com/nova-fine-tune-repo:SM-TJ-SFT-latest"
print(f'Model ID: {model_id}')
print(f'Recipe: {recipe}')
print(f'Instance type: {instance_type}')
print(f'Instance count: {instance_count}')
print(f'Image URI: {image_uri}')Configuring custom training recipes
A key differentiator when using Amazon SageMaker AI for Nova model fine-tuning is the ability to customize a training recipe. Recipes are pre-configured training stacks provided by AWS to help you quickly start training and fine-tuning. While maintaining compatibility with the standard hyperparameter set (epochs, batch size, learning rate, and warmup steps) of Amazon Bedrock, the recipes extend hyperparameter options through:
- Regularization parameters: hidden_dropout, attention_dropout, and ffn_dropout to prevent overfitting.
- Optimizer settings: Customizable beta coefficients and weight decay settings.
- Architecture controls: Adapter rank and scaling factors for LoRA training.
- Advanced scheduling: Custom learning rate schedules and warmup strategies.
The recommended approach is to start with the default settings to create a baseline, then optimize based on your specific needs. Here’s a list of some of the additional parameters that you can optimize for.
| Parameter | Range/Constraints | Purpose |
max_length |
1024–8192 | Control the maximum context window size for input sequences |
global_batch_size |
16,32,64 | Number of samples processed before updating model weights |
hidden_dropout |
0.0–1.0 | Regularization for hidden layer states to prevent overfitting |
attention_dropout |
0.0–1.0 | Regularization for attention mechanism weights |
ffn_dropout |
0.0–1.0 | Regularization for feed forward network layers |
weight_decay |
0.0–1.0 | L2 Regularization strength for model weights |
Adapter_dropout |
0.0–1.0 | Regularization for LoRA adapter parameters |
The complete recipe that we used can be found here.
Creating and executing a SageMaker AI training job
After configuring your model and recipe, initialize the ModelTrainer object and begin training:
from sagemaker.train import ModelTrainer
trainer = ModelTrainer.from_recipe(
training_recipe=recipe,
recipe_overrides=recipe_overrides,
compute=compute_config,
stopping_condition=stopping_condition,
output_data_config=output_config,
role=role,
base_job_name=job_name,
sagemaker_session=sess,
training_image=image_uri
)
# Configure data channels
from sagemaker.train.configs import InputData, S3DataSource
train_input = InputData(
channel_name="train",
data_source=S3DataSource(
s3_uri=train_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
val_input = InputData(
channel_name="val",
data_source=S3DataSource(
s3_uri=test_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
# Begin training
training_job = trainer.train(
input_data_config=[train_input,val_input],
wait=False
)After training, we register the model with Amazon Bedrock through the create_custom_model_deployment Amazon Bedrock API, enabling on-demand inference through the converse API using the deployed model ARN, system prompts, and user messages.
In our SageMaker AI training job, we used default recipe parameters, including an epoch of 2 and batch size of 64, our data contained 20,000 lines thus the complete training job lasted for 4 hours. With our ml.g5.48xlarge instance, the total cost for fine-tuning our Nova Micro model was $65.
4. Testing and evaluation
For evaluating our model, we performed both operational and accuracy testing. To evaluate accuracy, we implemented an LLM-as-a-Judge approach where we collected questions and SQL responses from our fine-tuned model and used a judge model to score them against the ground truth responses.
def get_score(system, user, assistant, generated):
formatted_prompt = (
"You are a data science teacher that is introducing students to SQL. "
f"Consider the following question and schema:"
f"<question>{user}</question>"
f"<schema>{system}</schema>"
"Here is the correct answer:"
f"<correct_answer>{assistant}</correct_answer>"
f"Here is the student's answer:"
f"<student_answer>{generated}</student_answer>"
"Please provide a numeric score from 0 to 100 on how well the student's "
"answer matches the correct answer. Put the score in <SCORE> XML tags."
)
_, result = ask_claude(formatted_prompt)
pattern = r'<SCORE>(.*?)</SCORE>'
match = re.search(pattern, result)
return match.group(1) if match else "0"
For operational testing, we gathered metrics including TTFT (Time to First Token) and OTPS (Output Tokens Per Second). Compared to the base Nova Micro model, we experienced cold start time to first token averaging 639 ms across 5 runs (34% increase). This latency increase stems from applying LoRA adapters at inference time rather than baking them into model weights. However, this architectural choice delivers substantial cost benefits, as the fine-tuned Nova Micro model costs the same as the base model, enabling on-demand pricing with pay-per-use flexibility and no minimum commitments. During normal operation, our time to first token averages 380 ms across 50 calls (7% increase). End-to-end latency totals approximately 477 ms for complete response generation. Token generation maintains a rate of roughly 183 tokens per second, representing only a 27% decrease from the base model while remaining highly suitable for interactive applications.
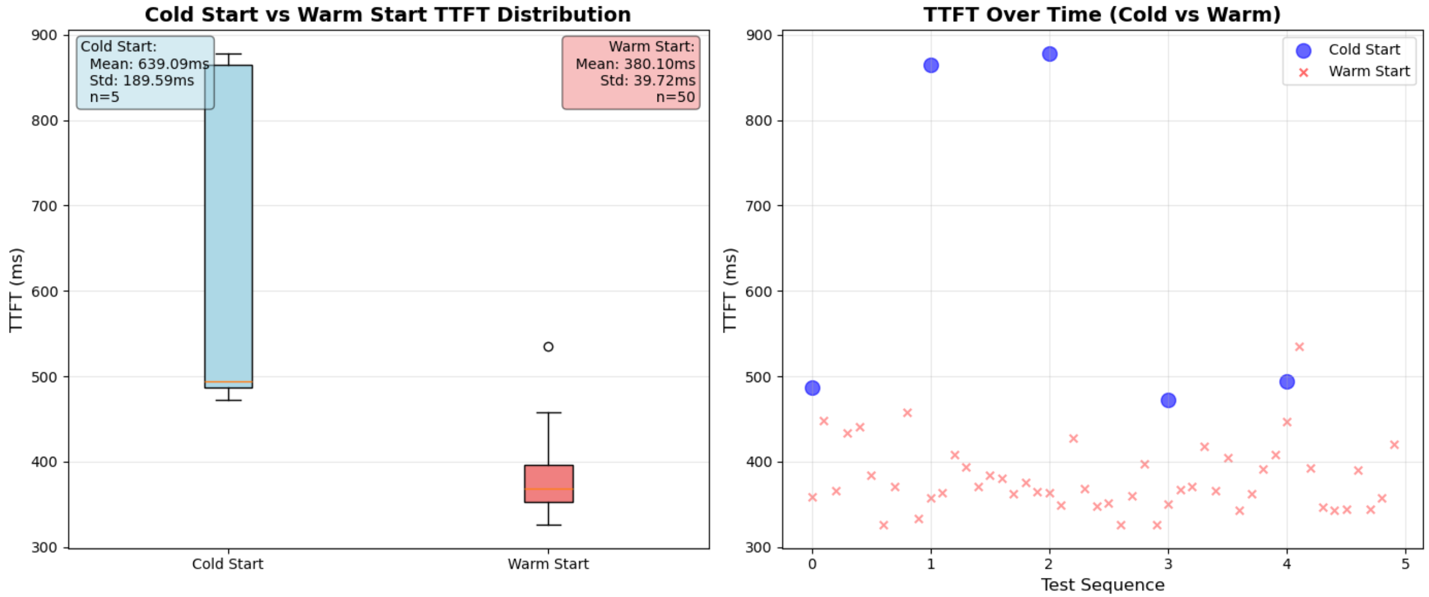
Cost summary
One-time costs:
- Amazon Bedrock model training cost: $0.001 per 1,000 tokens × number of epochs
- For 2,000 examples, 5 epochs and approximately 800 tokens each = $8.00
- SageMaker AI model training cost: We used the ml.g5.48xlarge instance, which costs $16.288/hour
- Training lasted 4 hours with a 20,000-line dataset = $65.15
- Ongoing costs
- Storage: $1.95 per month per custom model
- On-demand inference: Same per-token pricing as base Nova Micro
- Input tokens: $0.000035 per 1,000 tokens (Amazon Nova Micro)
- Output tokens: $0.00014 per 1,000 tokens (Amazon Nova Micro)
Example calculation for production workload:
For 22,000 queries per month (100 users × 10 queries/day × 22 business days):
- Average 800 input tokens + 60 output tokens per query
- Input cost: (22,000 × 800 / 1,000) × 0.000035 = 0.616
- Output cost: (22,000 × 60 / 1,000) × 0.00014 = 0.184
- Total monthly inference cost: 0.80 USD
This analysis validates that for custom dialect text-to-SQL use cases, fine-tuning a Nova model using PEFT LoRA on Amazon Bedrock is significantly more cost-effective than self-hosting custom models on persistent infrastructure. Self-hosted approaches might suite use cases requiring maximum control over infrastructure, security configurations, or integration requirements, but the Amazon Bedrock on-demand cost model offers significant cost savings for most production text-to-SQL workloads.
Conclusion
These implementation options demonstrate how Amazon Nova fine-tuning can be tailored to organizational needs and technical requirements. We explored two distinct approaches that serve different audiences and use cases. Whether you choose the managed simplicity of Amazon Bedrock or more control through SageMaker AI training, the serverless deployment model and on-demand pricing means that you only pay for what you use, while removing infrastructure management.
The Amazon Bedrock model customization approach provides a streamlined, managed solution that eliminates infrastructure complexity. Data scientists can focus on data preparation and model evaluation without managing training infrastructure, making it ideal for quick experimentation and development.
The SageMaker AI training approach offers increased control over every aspect of the fine-tuning process. Machine learning (ML) engineers gain granular control over training parameters, infrastructure selection, and integration with existing MLOps workflows, which enables optimization for required performance, cost, and operational requirements. For example, you can adjust batch sizes and instance types to optimize training speed, or modify learning rates and LoRA parameters to balance model quality with training time based on your specific operational needs
Choose Amazon Bedrock model customization when: You need rapid iteration, have limited ML infrastructure expertise, or want to minimize operational overhead while still achieving custom model performance.
Choose SageMaker AI training when: You require fine-grained parameter control, have specific infrastructure or compliance requirements, need integration with existing MLOps pipelines, or want to optimize every aspect of the training process.
Get started
Ready to build your own cost-effective text-to-SQL solution? Access our complete implementations:
- Bedrock Fine-Tuning Notebook: Managed, streamlined approach
- SageMaker AI Fine-Tuning Notebook: Advanced customization and control
Both approaches use the same cost-efficient deployment model, so you can choose based on your team’s expertise and requirements rather than cost constraints.