How Thomson Reuters delivers personalized content subscription plans at scale using Amazon Personalize
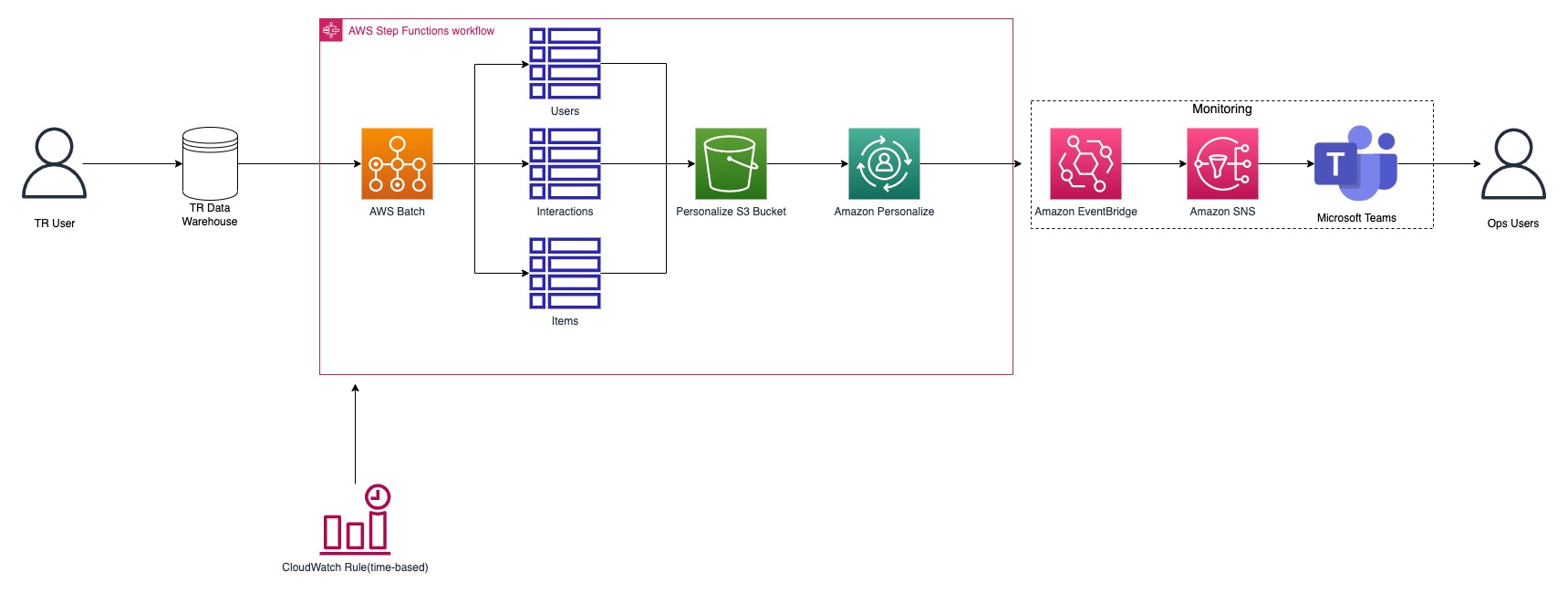
This post is co-written by Hesham Fahim from Thomson Reuters. Thomson Reuters (TR) is one of the world’s most trusted information organizations for businesses and professionals. It provides companies with the intelligence, technology, and human expertise they need to find trusted answers, enabling them to make better decisions more quickly. TR’s customers span across the … Read more




























