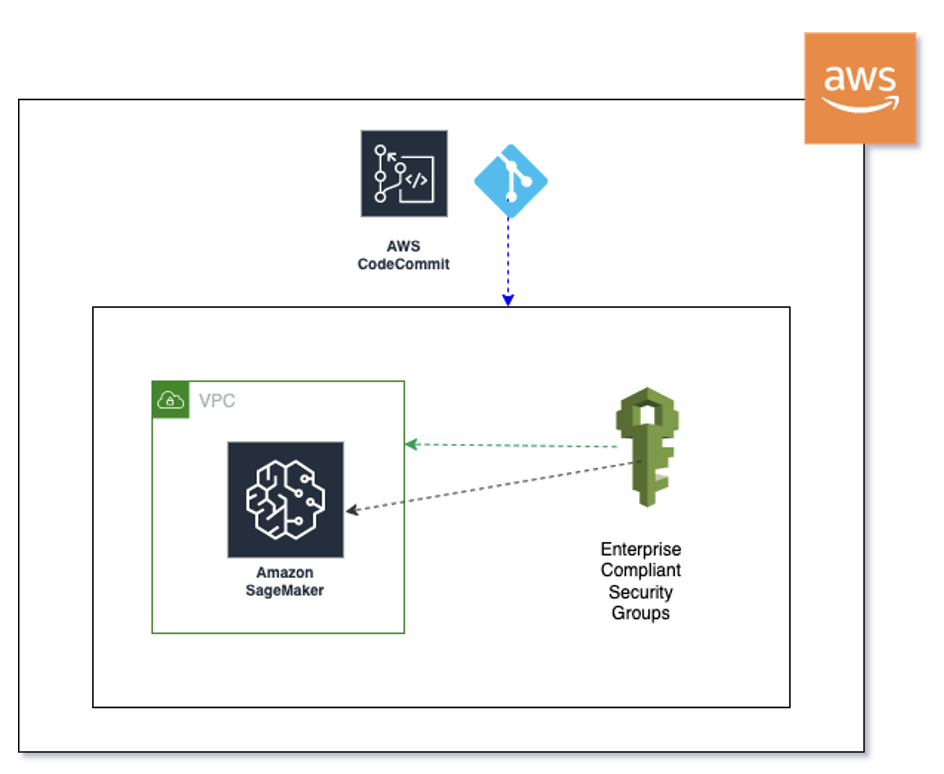
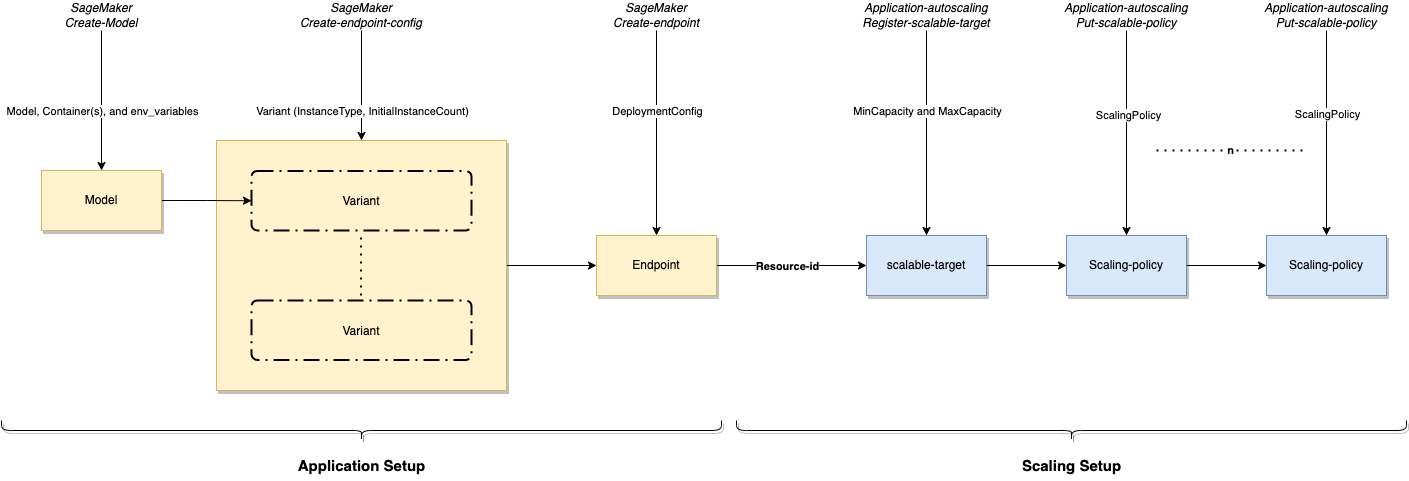
MLOps deployment best practices for real-time inference model serving endpoints with Amazon SageMaker
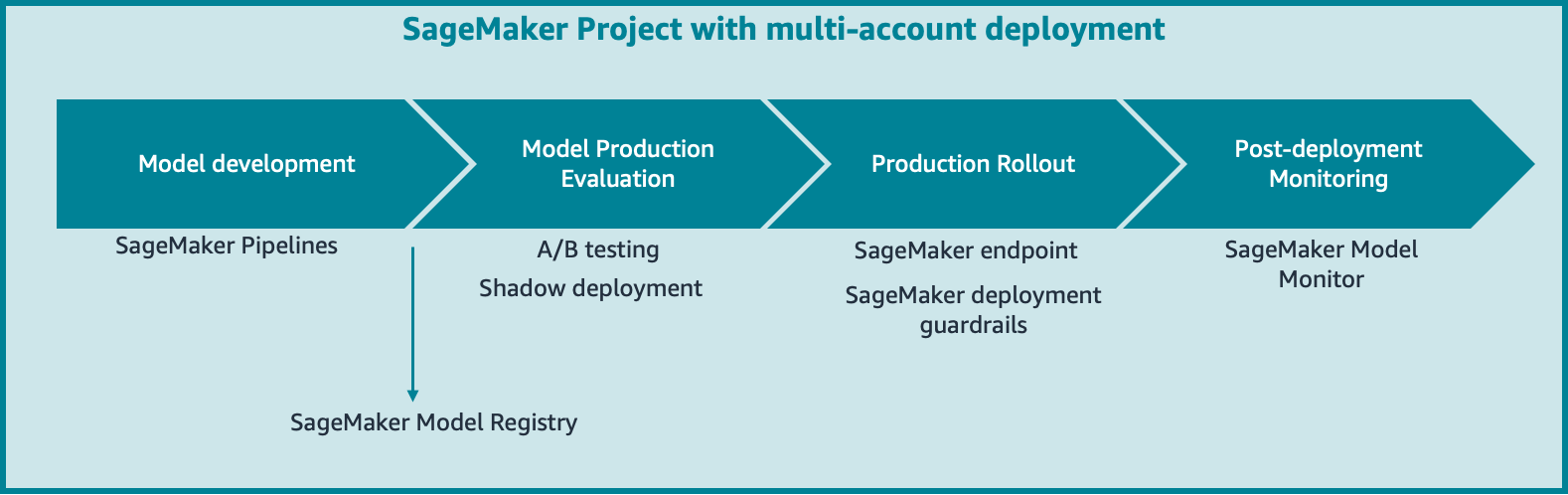
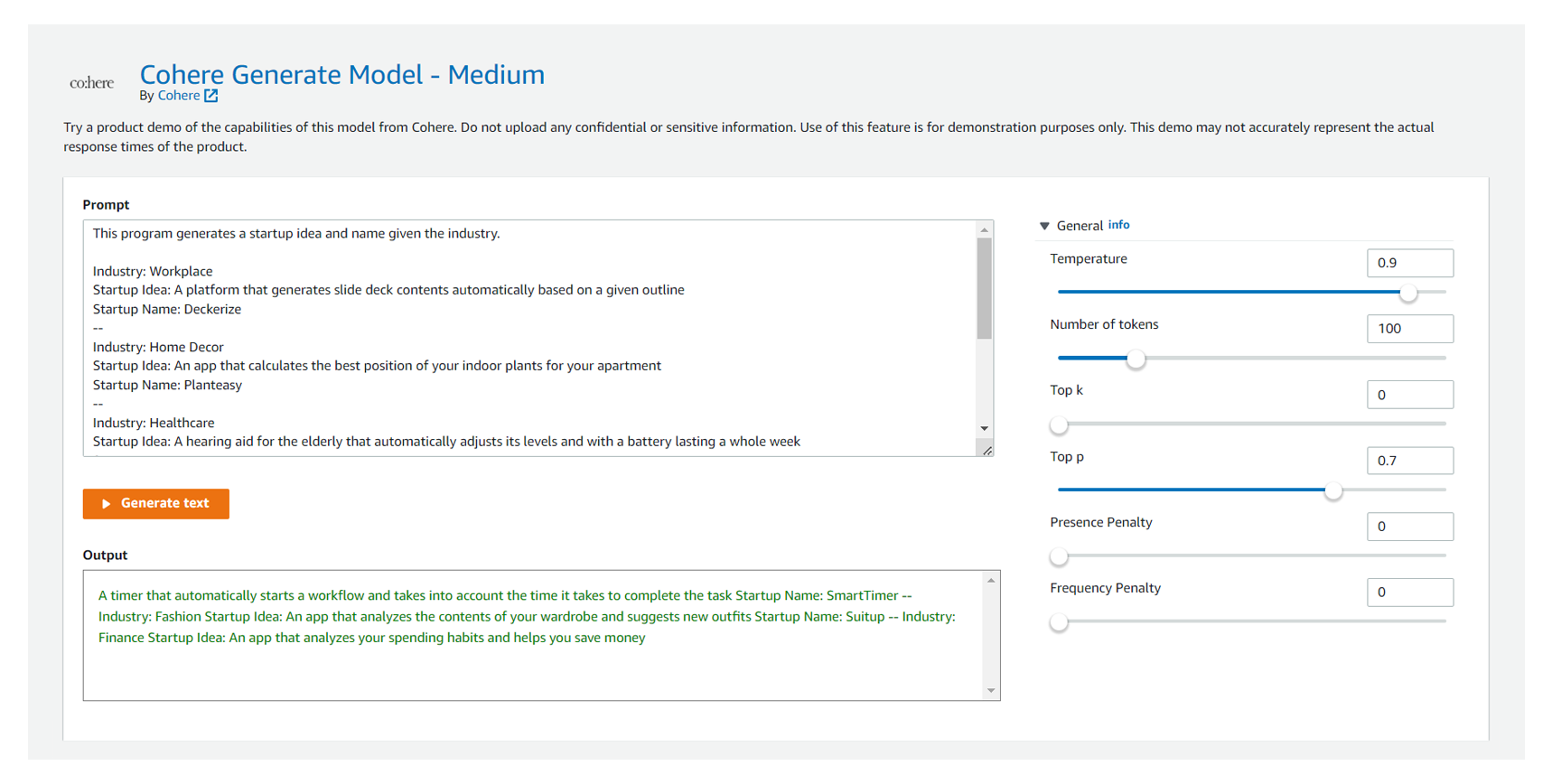
After you build, train, and evaluate your machine learning (ML) model to ensure it’s solving the intended business problem proposed, you want to deploy that model to enable decision-making in business operations. Models that support business-critical functions are deployed to a production environment where a model release strategy is put in place. Given the nature … Read more