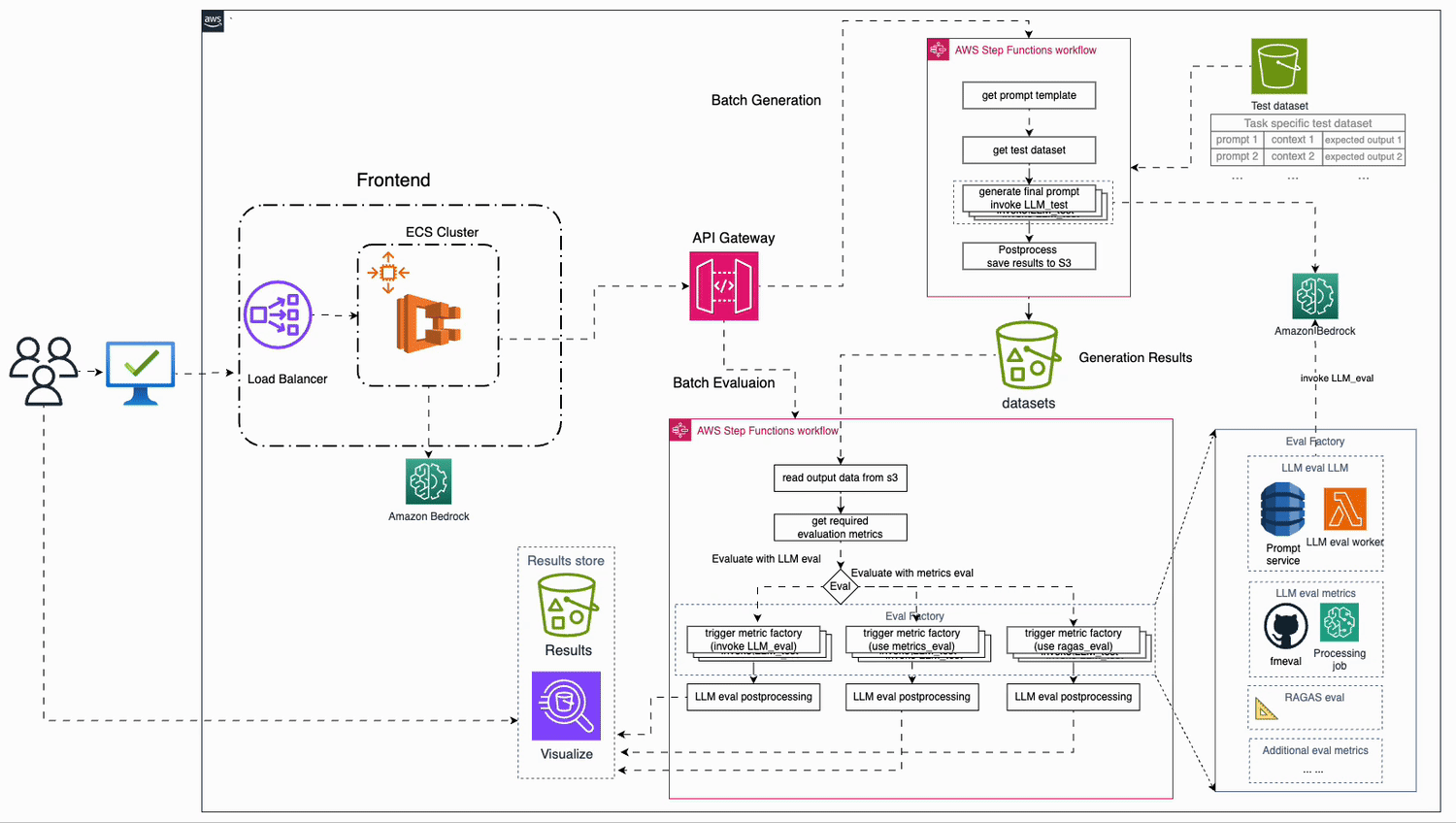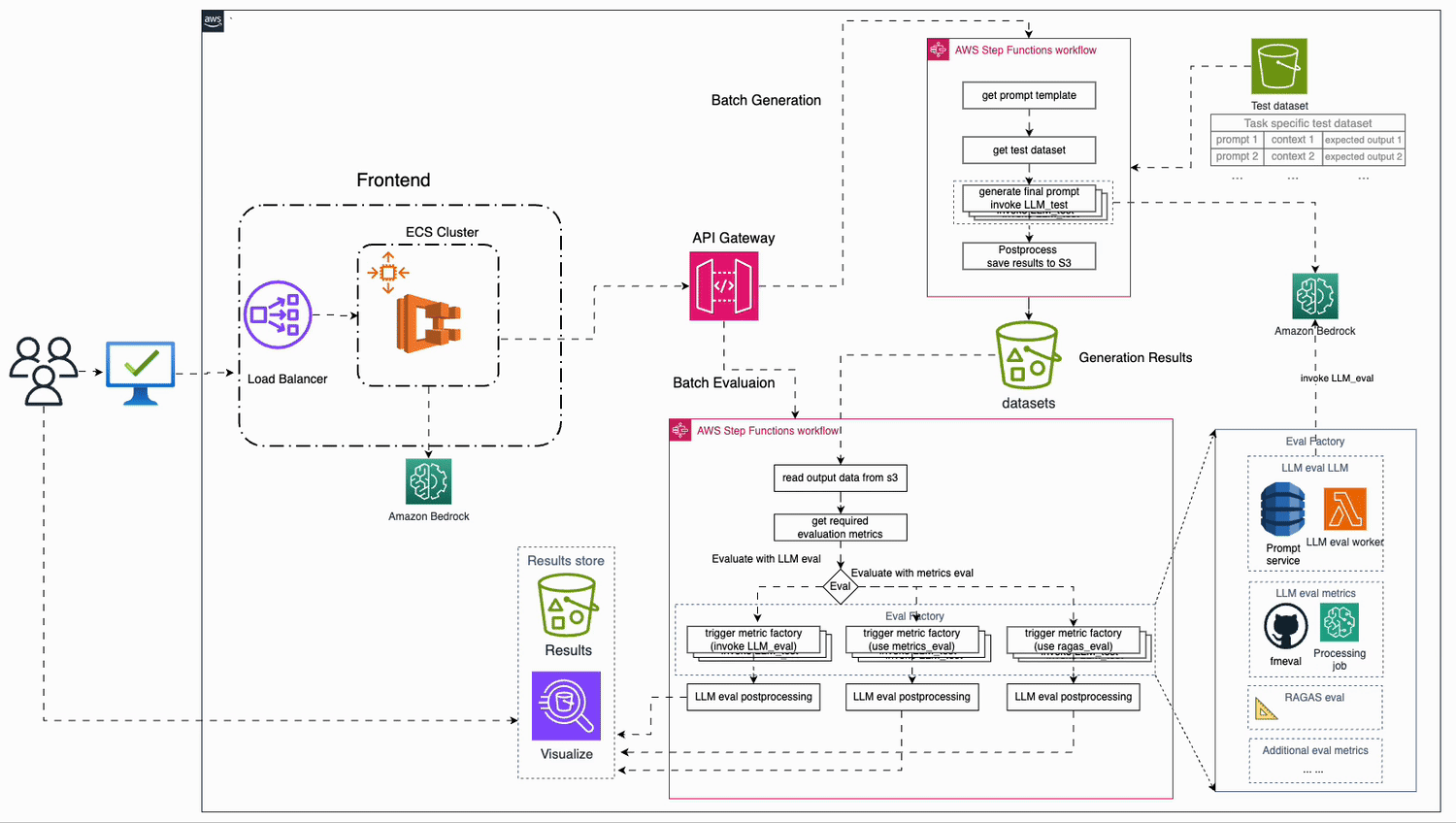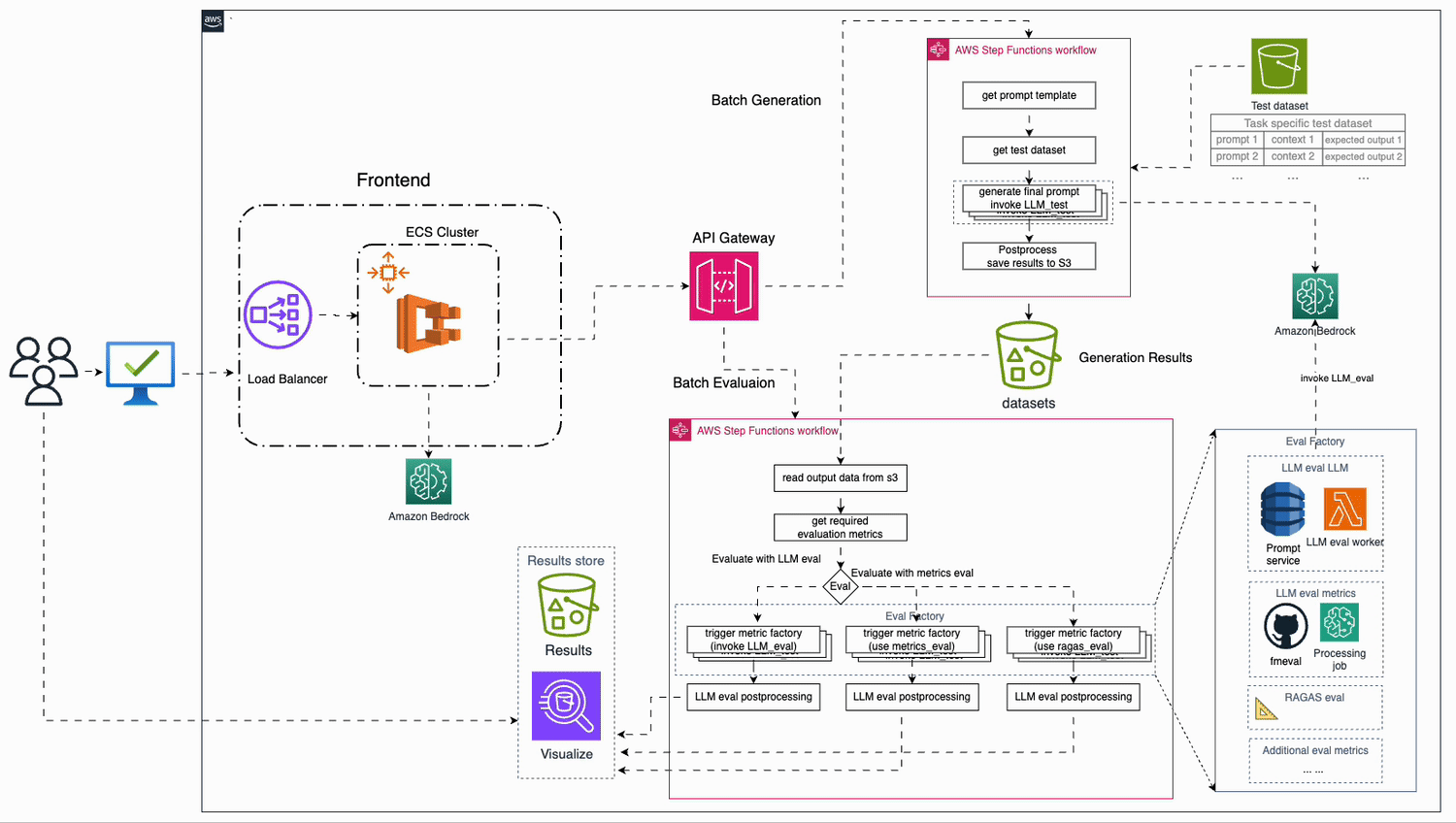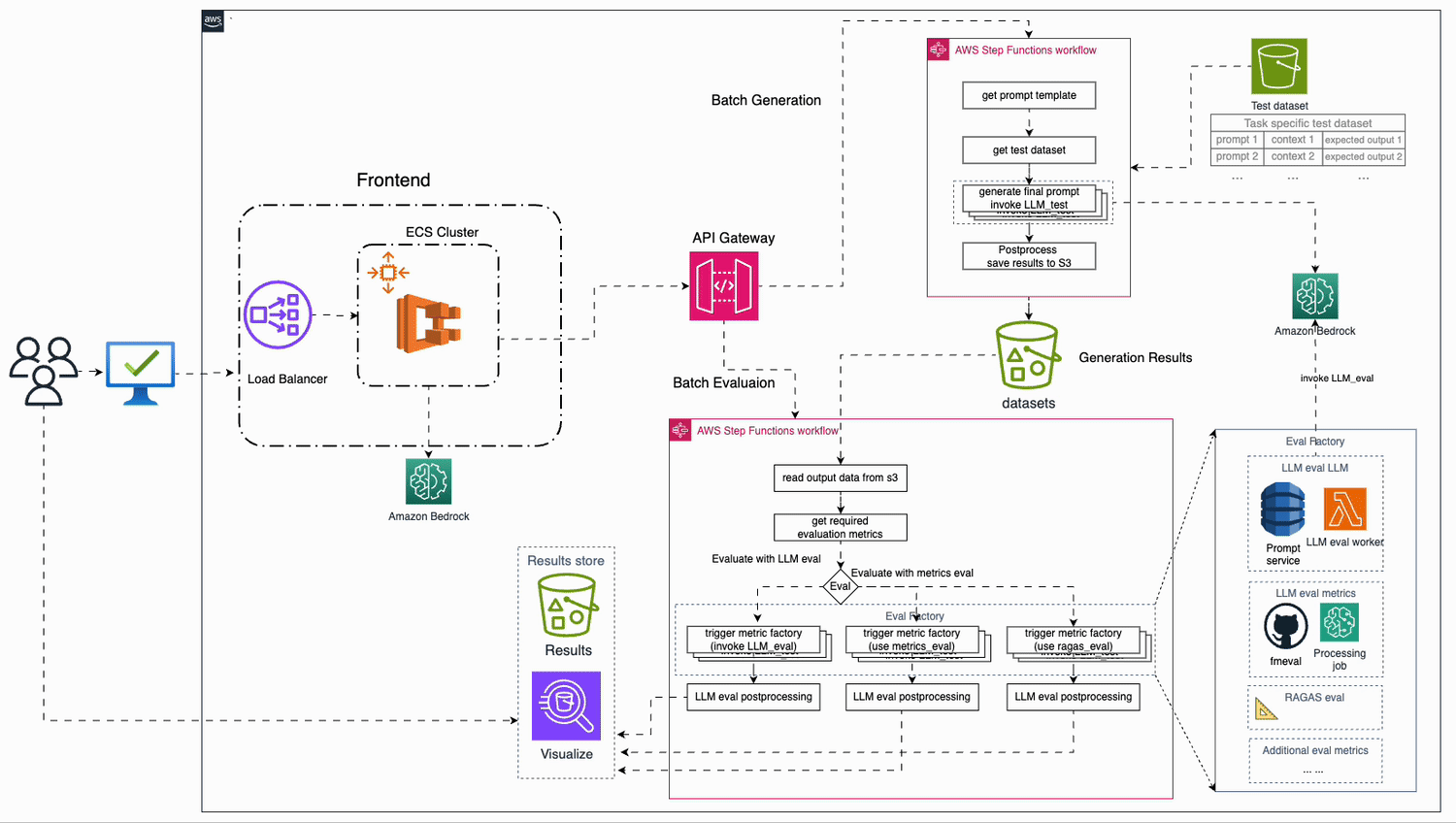
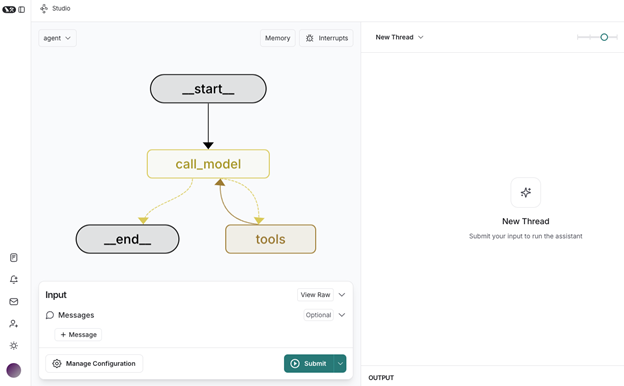
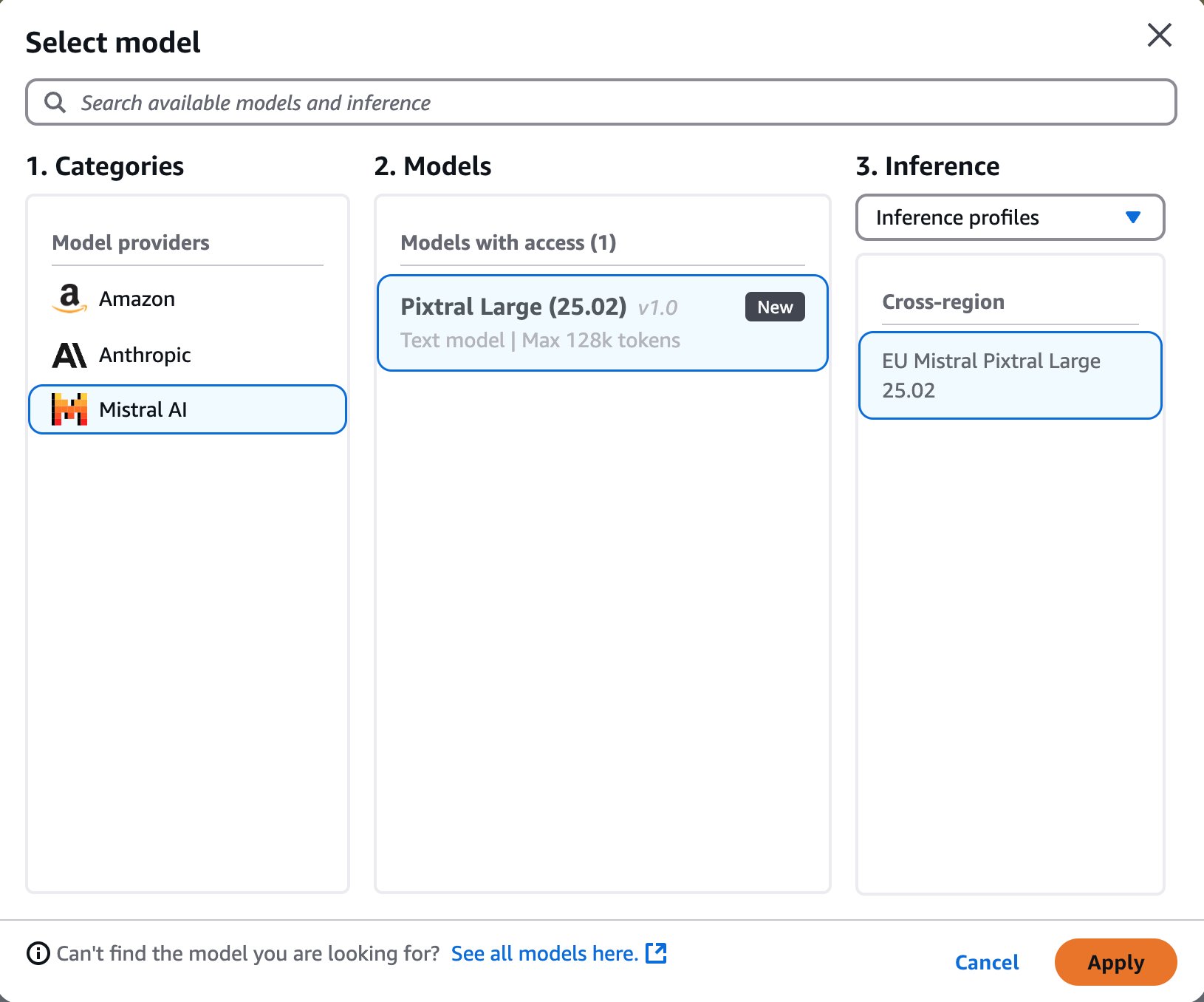
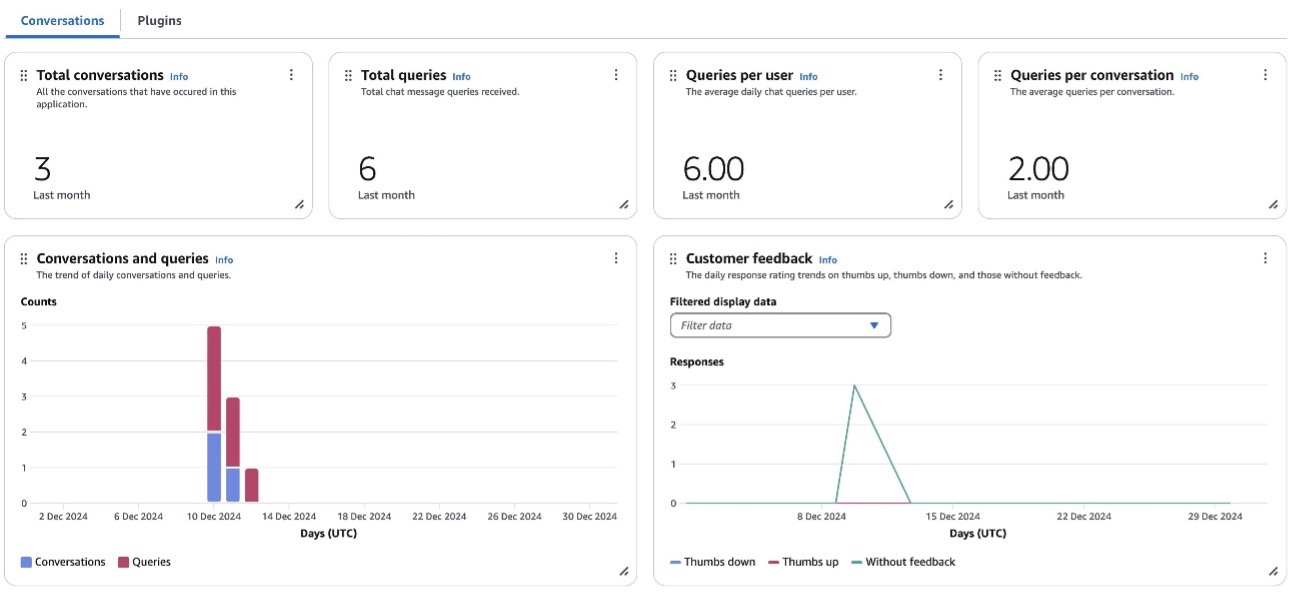
Build a location-aware agent using Amazon Bedrock Agents and Foursquare APIs
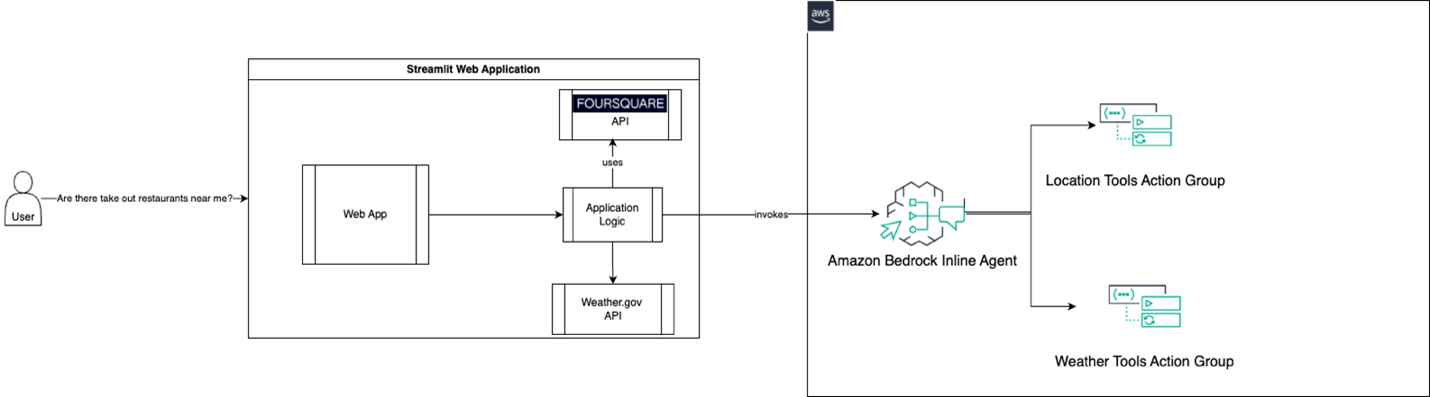
This post is co-written with Vikram Gundeti and Nate Folkert from Foursquare. Personalization is key to creating memorable experiences. Whether it’s recommending the perfect movie or suggesting a new restaurant, tailoring suggestions to individual preferences can make all the difference. But when it comes to food and activities, there’s more to consider than just personal … Read more