Table of Links
- Abstract
- Introduction
- Related work
- Problem statement
- [Methods]()
- Experiments
- Limitations
- [Conclusion]()
EXPERIMENTS
A. Physical Experiments
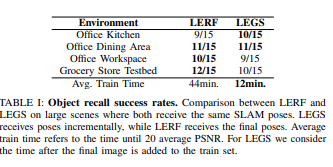
We evaluate LEGS through a series of open-vocabulary object recall tasks. These tasks are designed to measure the system’s competency in capturing and organizing information based on both location and semantic meaning. We evaluate LEGS on four large-scale indoor environments, two office kitchen scenes containing different objects, an office workspace, and a grocery store testbed [15] as seen in Figure 3. For the grocery store testbed, data is collected with the TTT robot [15]. The robot begins in a previously

Fig. 4: Single Camera Reconstruction Comparison Results. We compare the quality of Gaussian splats on an Intel Realsense D435, Intel Realsense D455, and Stereolabs Zed 2 with and without bundle adjustment. For each configuration we present two views: one of the Gaussian splat facing the kitchen island head-on and another view at an angle.
unseen environment and is manually pushed around a preplanned path (including straight lines, loops, figure-8, etc) while continuously registering new images until it finishes the path. The robot will actuate its torso height to obtain multiple azimuthal perspectives from the same position on subsequent passes. Every 150 keyframes, we perform global bundle adjustment on all previous poses in DROID-SLAM and update accordingly in our 3D Gaussian map. Our system uses 2 NVIDIA 4090s, one for training LEGS, which takes 15 GB of memory and the other for DROID-SLAM, which can take up to 18 GB of memory.
The evaluation approach was adopted from previous 3D language mapping works [1], [55]. We randomly sample images from our training set and query Chat-GPT 4V with: “name an object in this scene in 3 words or fewer”. This process is repeated until 15 unique queries are generated for each of the four scenes. We then choose a random novel view and manually annotate a 2D bounding box around each selected object of interest. Then, we query LEGS on each object and identify the highest activation energy point, and project that point in the novel 2D view. If the projected point is contained in the bounding box, we consider the query successful. Additionally, we directly baseline our approach by running LERF [1] to compare the object recall capabilities for a large-scale scene in radiance field methods.
The results in Table 1 suggest that LERF and LEGS have similar language capabilities, recalling roughly the same number of objects per scene. However, to achieve the same visual quality, LERF takes an average time of 44 minutes to train while LEGS only takes 12 minutes. Figure
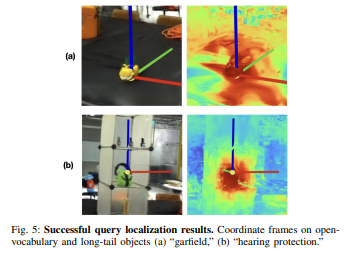
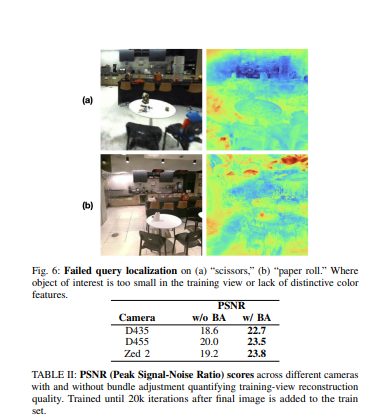
shows examples of successful object localization queries. Localization may fail when objects are not seen well in the training views or have similar color to their background, as shown in Figure
B. Reconstruction quality comparison
We study how camera configuration and bundle adjustment (BA) affect the quality of the LEGS Gaussian splat as summarized in Figure 4 and Table 2. With respect to the camera configuration ablation, we evaluated different depth and stereo cameras including the Realsense D435, Realsense D455, and Zed 2. For each camera configuration, we also run a BA ablation where we either run bundle adjustment at the end of the traversal or not at all.
Global Bundle Adjustment: Table II suggests bundle adjustment improves Gaussian Splat quality for all camera configurations, removing ghostly duplicate artifacts. This is especially true for the Realsense D455 and Zed 2 cameras where the bundle adjustment configurations yielded nearphotorealistic views of the scene whereas without bundle adjustment, both configurations have significantly more Gaussian floaters and/or offset objects (i.e. the left image in Figure 4 part (e) has two volleyballs). The Realsense D435 performs slightly better with bundle adjustment, but neither D435 configuration yield high quality largely due to the camera’s low FOV resulting in worse localization. We also compared a single Zed 2 camera to a multi-camera setup where the D455 Realsense is front-facing and 2 Zed cameras face the left and right side. Both gaussian splats perform well and properly render objects that were well viewed in the traversal (“raccoon toy” and “first aid kit”) as seen in Figure 7. However, none of the cameras were pointing toward the ground leading to sparse views of objects near the floor. Because the multi-camera setup captures more views of the scene, it is able to construct a Gaussian splat that is better able to render these low-view objects such as the trash chutes and wet floor sign.

:::info
Authors:
- Justin Yu
- Kush Hari
- Kishore Srinivas
- Karim El-Refai
- Adam Rashid
- Chung Min Kim
- Justin Kerr
- Richard Cheng
- Muhammad Zubair Irshad
- Ashwin Balakrishna
- Thomas Kollar Ken Goldberg
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::