Agentic generative AI assistants represent a significant advancement in artificial intelligence, featuring dynamic systems powered by large language models (LLMs) that engage in open-ended dialogue and tackle complex tasks. Unlike basic chatbots, these implementations possess broad intelligence, maintaining multi-step conversations while adapting to user needs and executing necessary backend tasks.
These systems retrieve business-specific data in real-time through API calls and database lookups, incorporating this information into LLM-generated responses or providing it alongside them using predefined standards. This combination of LLM capabilities with dynamic data retrieval is known as Retrieval-Augmented Generation (RAG).
For example, an agentic assistant handling hotel booking would first query a database to find properties that match the guest’s specific requirements. The assistant would then make API calls to retrieve real-time information about room availability and current rates. This retrieved data can be handled in two ways: either the LLM can process it to generate a comprehensive response, or it can be displayed alongside an LLM-generated summary. Both approaches allow guests receive precise, current information that’s integrated into their ongoing conversation with the assistant.
In this post, we show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.
Information retrieval approaches in RAG systems
Generally speaking, information retrieval supporting RAG capabilities in agentic generative AI implementations revolves around real-time querying of the backend data sources or communicating with an API. The responses are then factored into the subsequent steps performed by the implementation. From a high-level system design and implementation perspective, this step is not specific to generative AI-based solutions: Databases, APIs, and systems relying on integration with them have been around for a long time. There are certain information retrieval approaches that have emerged alongside agentic AI implementations, most notably, semantic search-based data lookups. They retrieve data based on the meaning of the search phrase as opposed to keyword or pattern lexical similarity. Vector embeddings are precomputed and stored in vector databases, enabling efficient similarity calculations at query time. The core principle of Vector Similarity Search (VSS) involves finding the closest matches between these numerical representations using mathematical distance metrics such as cosine similarity or Euclidean distance. These mathematical functions are particularly efficient when searching through large corpora of data because the vector representations are precomputed. Bi-encoder models are commonly used in this process. They separately encode the query and documents into vectors, enabling efficient similarity comparisons at scale without requiring the model to process query-document pairs together. When a user submits a query, the system converts it into a vector and searches for content vectors positioned closest to it in the high-dimensional space. This means that even if exact keywords don’t match, the search can find relevant results based on conceptual semantic similarity. Moreover, in situations where search terms are lexically but not semantically close to entries in the dataset, semantic similarity search will “prefer” semantically similar entries.
For example, given the vectorized dataset: [“building materials”, “plumbing supplies”, “2×2 multiplication result”], the search string “2×4 lumber board” will most likely produce “building materials” as the top matching candidate. Combining semantic search with LLM-driven agents supports natural language alignment across the user-facing and backend data retrieval components of the solution. LLMs process natural language Input provided by the user while semantic search capabilities allow for data retrieval based on the natural language Input formulated by LLMs depending on the end user – agent communication cadence.
The challenge: When semantic search alone isn’t enough
Consider a real-world scenario: A customer is searching for a hotel property and wants to find “a luxury hotel with ocean views in Miami, Florida.” Semantic search excels at understanding concepts like “luxury” and “ocean views,” it may struggle with precise location matching. The search might return highly relevant luxury oceanfront properties based on semantic similarity, but these could be in California, the Caribbean, or anywhere else with ocean access, not specifically in Miami as requested. This limitation arises because semantic search prioritizes conceptual similarity over exact attribute matching. In cases where users need both semantic understanding (luxury, ocean views) and precise filtering (Miami, Florida), relying solely on semantic search produces suboptimal results. This is where hybrid search becomes essential. It combines the semantic understanding of natural language descriptions with the precision of text-based filtering on structured attributes like location, dates, or specific metadata. To address this, we introduce a hybrid search approach that performs both:
- Semantic search to understand natural language descriptions and find semantically similar content
- Text-based search to facilitate precise matching on structured attributes like locations, dates, or identifiers
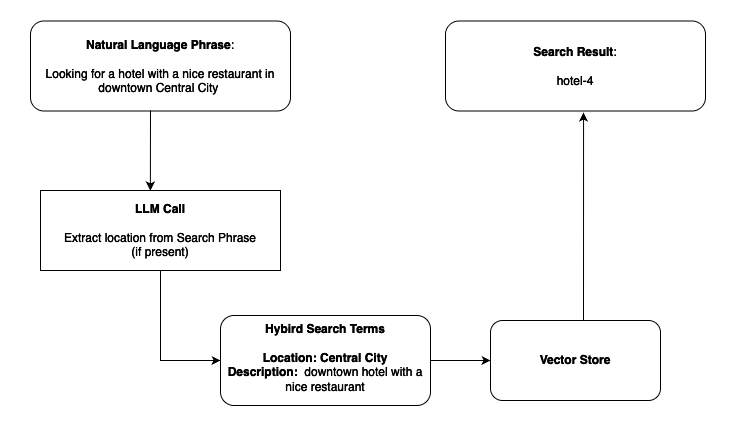
When a user provides a search phrase, an LLM first analyzes the query to identify specific attributes (such as location) and maps them to searchable values (for example, “Northern Michigan” → “MI”). These extracted attributes are then used as filters in conjunction with semantic similarity scoring, making sure that results are both conceptually relevant and precisely matched to the user’s requirements. The following tables provide a simplified view of the semantic search flow with clear text hotel descriptions provided for context:
Vector store data:
| hotel-1 |
Description: The Artisan Loft hotel anchors the corner of Green and Randolph Streets in Big City’s bustling Southwest Loop, occupying a thoughtfully renovated 1920s brick warehouse that celebrates the neighborhood’s industrial heritage. Guests find themselves mere steps from the famed Restaurant Row, with acclaimed dining spots and trendy boutiques dotting the surrounding blocks. Description Vector: […] Location: Big City, USA |
| hotel-2 |
Description: Perched on a rugged cliff overlooking the dramatic coastline of Big Sur, The Cypress Haven emerges from the landscape as if it were carved from the earth itself. This intimate 42-room sanctuary seamlessly integrates into its surroundings with living roof gardens, floor-to-ceiling windows, and natural materials including local stone and reclaimed redwood. Each spacious suite features a private terrace suspended over the Pacific, where guests can spot migrating whales while soaking in Japanese cedar ofuro tubs. Description Vector: […] Location: Beach City, USA |
| hotel-3 |
Description: Nestled in a centuries-old maple forest just outside the Berkshires, Woodland Haven Lodge offers an intimate escape where luxury meets mindful simplicity. This converted 19th-century estate features 28 thoughtfully appointed rooms spread across the main house and four separate cottages, each with wraparound porches and floor-to-ceiling windows that frame the surrounding woodlands. Description Vector: […] Location: Quiet City, USA |
| hotel-4 |
Description: Nestled in the heart of Central City’s bustling downtown district, the Skyline Oasis hotel stands as a beacon of luxury and modernity. This 45-story glass and steel tower offers breathtaking panoramic views of the city’s iconic skyline and the nearby Central River. With 500 elegantly appointed rooms and suites, the Skyline Oasis caters to both business travelers and tourists seeking a premium urban experience. The hotel boasts a rooftop infinity pool, a Michelin-starred restaurant, and a state-of-the-art fitness center. Its prime location puts guests within walking distance of Central City’s major attractions, including the Museum of Modern Art, the Central City Opera House, and the vibrant Riverfront District. Description Vector: […] Location: Central City, USA |
| Search Phrase | Looking for a hotel by the ocean |
| Search Results | hotel-2 |
Search example:
- Search phrase: “Looking for a hotel by the ocean”
- Semantic search result: hotel-2 (The Cypress Haven)
Hybrid search example:
- Search phrase: “Looking for a hotel with a nice restaurant in downtown Central City”
- Hybrid search result: hotel-4 (best match considering both semantic relevance and precise location)
For more details on hybrid search implementations, refer to the Amazon Bedrock Knowledge Bases hybrid search blog post.
Introducing an agent-based solution
Consider a hotel search scenario where users have diverse needs. One user might ask “find me a cozy hotel,” requiring semantic understanding of “cozy.” Another might request “find hotels in Miami,” needing precise location filtering. A third might want “a luxury beachfront hotel in Miami,” requiring both approaches simultaneously. Traditional RAG implementations with fixed workflows cannot adapt dynamically to these varying requirements. Our scenario demands custom search logic that can combine multiple data sources and dynamically adapt retrieval strategies based on query characteristics. An agent-based approach provides this flexibility. The LLM itself determines the optimal search strategy by analyzing each query and selecting the appropriate tools.
Why agents?
Agent-based systems offer superior adaptability because the LLM determines the sequence of actions needed to solve problems, enabling dynamic decision routing, intelligent tool selection, and quality control through self-evaluation. The following sections show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.
Architecture overview
Figure 1 shows a modern, serverless architecture that you can use for an intelligent search assistant. It combines the foundation models in Amazon Bedrock, Amazon Bedrock AgentCore (for agent orchestration), and Amazon OpenSearch Serverless (for hybrid search capabilities).
Client interaction layer
Client applications interact with the system through Amazon API Gateway, which provides a secure, scalable entry point for user requests. When a user asks a question like “Find me a beachfront hotel in Northern Michigan,” the request flows through API Gateway to Amazon Bedrock AgentCore.
Agent orchestration with Amazon Bedrock AgentCore
Amazon Bedrock AgentCore serves as the orchestration engine, managing the complete agent lifecycle and coordinating interactions between the user, the LLM, and available tools. AgentCore implements the agentic loop—a continuous cycle of reasoning, action, and observation—where the agent:
- Analyzes the user’s query using Bedrock’s foundation models
- Decides which tools to invoke based on the query requirements
- Executes the appropriate hybrid search tool with extracted parameters
- Evaluates the results and determines if additional actions are needed
- Responds to the user with synthesized information
Throughout this process, Amazon Bedrock Guardrails enforce content safety and policy adherence, maintaining appropriate responses.
Hybrid search with OpenSearch Serverless
The architecture integrates Amazon OpenSearch Serverless as the vector store and search engine. OpenSearch stores both vectorized embeddings (for semantic understanding) and structured text fields (for precise filtering). This approach supporting our hybrid search approach. When the agent invokes the hybrid search tool, OpenSearch executes queries that combine:
- Semantic matching using vector similarity for conceptual understanding
- Text-based filtering for precise constraints like location or amenities
Monitoring and security
The architecture includes Amazon CloudWatch for monitoring system performance and usage patterns. AWS IAM manages access control and security policies across components.
Why this architecture?
This serverless design provides several key advantages:
- Low-latency responses for real-time conversational interactions
- Auto-scaling to handle varying workloads without manual intervention
- Cost-effectiveness through pay-as-you-go pricing with no idle infrastructure
- Production-ready with built-in monitoring, logging, and security features
The combination of the AgentCore orchestration capabilities with hybrid search functionality of OpenSearch allows our assistant to dynamically adapt its search strategy based on user intent, something that rigid RAG pipelines cannot achieve.
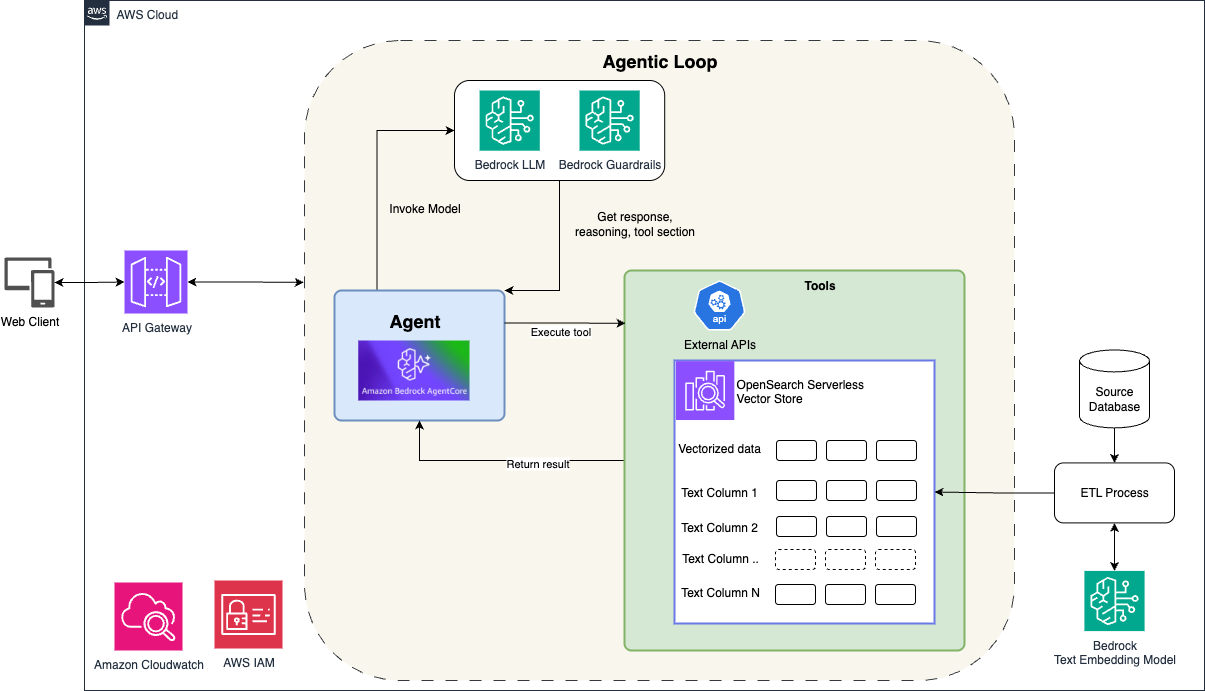
Figure 1
Figure Note: The code samples and architecture artifacts provided in this document are intended for demonstration and reference purposes only and are not production-ready.
Implementation with Strands and Amazon Bedrock AgentCore
To build our hybrid search agent, we use Strands, an open-source AI agent framework that simplifies developing LLM-powered applications with tool-calling capabilities. Strands allow us to define our hybrid search function as a “tool” that the agent can intelligently invoke based on user queries. For comprehensive details on Strands architecture and patterns, see the Strands documentation.
Here’s how we define our hybrid search tool:
from strands import tool
@tool
def hybrid_search(query_text: str, country: str = None, city: str = None):
"""
Performs hybrid search combining semantic understanding with location filtering.
The agent calls this when users provide both descriptive preferences and location.
Args:
query_text: Natural language description of what to search for
country: Optional country filter
city: Optional city filter
"""
# Generate embeddings for semantic search
vector = generate_embeddings(query_text)
# Build hybrid query combining vector similarity and text filters
query = {
"bool": {
"must": [
{"knn": {"embedding_field": {"vector": vector, "k": 10}}}
],
"filter": []
}
}
# Add location filters if provided
if country:
query["bool"]["filter"].append({"term": {"country": country}})
if city:
query["bool"]["filter"].append({"term": {"city": city}})
# Execute search in OpenSearch
response = opensearch_client.search(index="hotels", body=query)
return format_results(response)
Once we’ve defined our tools, we integrate them with Amazon Bedrock AgentCore for deployment and runtime orchestration. Amazon Bedrock AgentCore enables you to deploy and operate highly effective agents securely at scale using any framework and model. It provides purpose-built infrastructure to securely scale agents and controls to operate trustworthy agents.
For detailed information about integrating Strands with Amazon Bedrock AgentCore, see the AgentCore-Strands integration tutorial.
Hybrid search implementation deep dive
A key differentiator of our AI assistant solution is its advanced hybrid search capability. While many RAG implementations rely solely on semantic search, our architecture extends beyond this. We’ve used the full potential of OpenSearch, enabling semantic, text-based, and hybrid searches, all within a single, efficient query. The following sections explore the technical details of this implementation.
The two-pronged implementation
Our hybrid search implementation is built on two fundamental components: optimized data storage and versatile query handling.
1. Optimized data storage
The approach to data storage is important for efficient hybrid search.
- Data categorization: We systematically categorize our data into two main types:
- Semantic search candidates: This includes detailed descriptions, contexts, and explanations – content that benefits from understanding meaning beyond keywords.
- Text search candidates: This encompasses metadata, product identifiers, dates, and other structured fields.
- Vector embedding: For our semantic data, we use AWS Bedrock’s embedding models. These transform text into high-dimensional vectors that capture semantic meaning effectively.
- Text data optimization: Text data is stored in its original format, optimized for rapid traditional queries.
- Unified index structure: Our OpenSearch index is designed to accommodate both vector embeddings and text fields concurrently, enabling flexible querying capabilities.
2. Versatile search functionality
Building on our optimized data storage, we’ve developed a comprehensive search function that our AI agent can utilize effectively:
- Adaptive search types: Our search function is designed to perform semantic, text, or hybrid searches as required by the agent.
- Semantic search implementation: For meaning-focused queries, we generate query embeddings using Amazon Bedrock and perform a k-NN (k-Nearest Neighbors) search in the vector space.
- Text search capabilities: When precise matching is necessary, we use OpenSearch’s robust text query functionalities, including exact and fuzzy matching options.
- Hybrid search execution: This is where we combine vector similarity with text matching in a unified query. Using OpenSearch’s bool query, we can adjust the balance between semantic and text relevance as needed.
- Result integration: Regardless of the search type, our system consolidates and ranks results based on overall relevance, combining semantic understanding with precise text matching.
Reference pseudo code for hybrid search implementation:
def hybrid_search(query_text, country, city, search_type="hybrid"):
"""
Hybrid search combining semantic and text-based search with location filtering
"""
# 1. Generate embeddings for semantic search
if search_type in ["semantic", "hybrid"]:
vector = generate_embeddings(query_text)
# 2. Build search query based on type
if search_type == "semantic":
query = build_semantic_query(vector)
elif search_type == "text":
query = build_text_query(country, city)
else: # hybrid search
query = build_hybrid_query(vector, country, city)
# 3. Execute search
response = search_opensearch(query)
# 4. Process and return results
return format_results(response)
# Example usage:
results = hybrid_search(
query_text="luxury hotel",
country="USA",
city="Miami"
)
OpenSearch supports multiple query types including text-based search, vector search (knn), and hybrid approaches that combine both methods. For detailed information about available query types and their implementations, refer to the OpenSearch query documentation.
Significance of the hybrid approach
The hybrid approach significantly enhances our AI assistant’s capabilities:
- It supports highly accurate information retrieval, considering both context and content.
- It adapts to various query types, maintaining consistent performance.
- It provides more relevant and comprehensive responses to user inquiries.
In the domain of AI-powered search, our hybrid approach represents a significant advancement. It offers a level of flexibility and accuracy that substantially improves our assistant’s ability to retrieve and process information effectively.
Real-life use cases
Some of the use cases where hybrid search can be applicable include things like:
- Real estate and property: Property search combining lifestyle preference understanding (“family-friendly”) with exact location and amenity filtering.
- Legal and professional services: Case law research combining conceptual legal similarity with precise jurisdiction and date filtering for comprehensive legal research.
- Healthcare and medical: Care teams ask “patients with chronic conditions requiring similar treatment protocols as John Doe” – combines semantic understanding of treatment complexity with exact medical record matching.
- Media and entertainment: Content discovery system combining exact genre filtering with semantic plot understanding
- E-commerce and retail: Natural language product discovery with filter precision – “comfortable winter shoes” finds semantic matches while applying exact size or price or brand filters.
These use cases demonstrate how hybrid search bridges the gap between natural language understanding and precise data filtering, enabling more intuitive and accurate information retrieval.
Conclusion
The integration of Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents, and Amazon OpenSearch Serverless represents a significant advancement in building intelligent search applications that combine the power of LLMs with sophisticated information retrieval techniques. This architecture blends semantic, text-based, and hybrid search capabilities to deliver more accurate and contextually relevant results than traditional approaches. By implementing an agent-based system using Amazon Bedrock AgentCore, state management and Strands tool abstractions, developers can create dynamic, conversational AI assistants that intelligently determine the most appropriate search strategies based on user queries. The hybrid search approach, which combines vector similarity with precise text matching, offers flexibility and accuracy in information retrieval, enabling AI systems to better understand user intent and deliver more comprehensive responses. As organizations continue to build AI solutions, this architecture provides a scalable, secure foundation that uses the full potential of AWS services while maintaining the adaptability needed for complex, real-world applications.