Let’s learn about Statistics via these 118 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the Learn Repo or LearnRepo.com to find the most read blog posts about any technology.
The science of collecting, analyzing, interpreting, presenting, and organizing data, fundamental for making informed decisions and understanding complex phenomena in various fields.
1. Crossentropy, Logloss, and Perplexity: Different Facets of Likelihood

We explore the link between three popular loss functions: crossentropy, logloss and perplexity
2. Outlier Detection: What You Need to Know
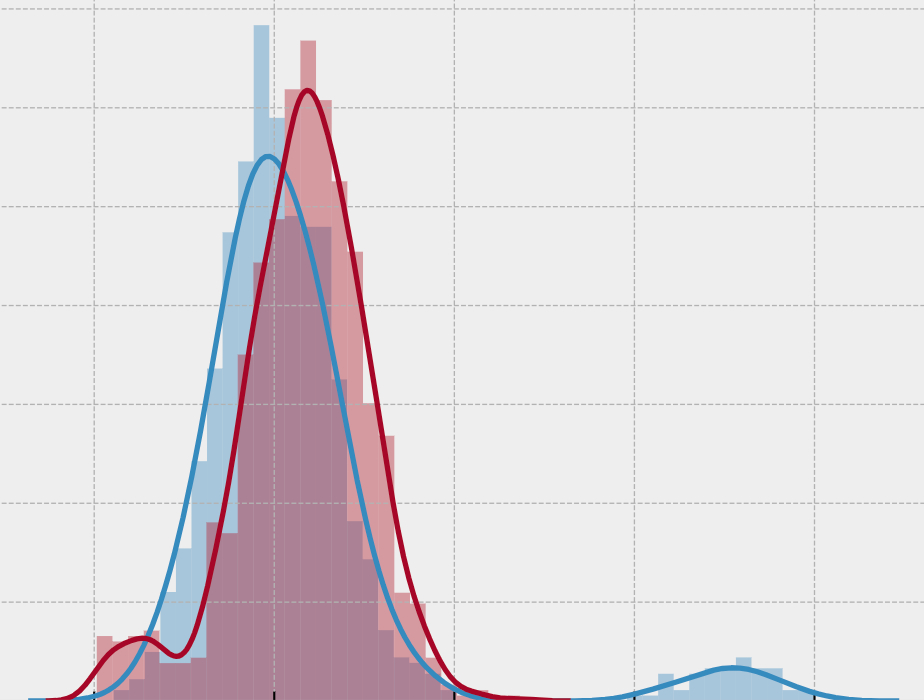
Decisions are usually based on the sample mean, which is very sensitive to outliers and can dramatically change the value. So, it is crucial to manage outliers
3. Radial Basis Functions: Types, Advantages, and Use Cases

An introductory article explaining the basic intuition, mathematical idea & scope of radial basis function in the development of predictive machine learning.
4. 12 Best Pre-Installed R Datasets Commonly Used for Statistical Analysis

R programming is mostly used in statistical analysis and ML.
This article looks at the Best Pre-Installed R Datasets Commonly Used for Statistical Analysis.
5. How to Retrieve Player Stats from the NHL’s undocumented REST API

It’s that time of year again. Summer is coming to an end, Autumn is around the corner, and the NHL season is about to begin.
6. Advanced Techniques for Time Series Data Feature Engineering

Discover advanced feature engineering techniques for time series data, including Fourier transform, wavelet transformation, derivatives, and autocorrelation.
7. How to Implement Gaussian Blurs

A Gaussian blur is applied by convolving the image with a Gaussian function. We’ll take the Gaussian function and we’ll generate an n x m matrix.
8. Calculate Required Rate of Return With the Fama-French Three-Factor Model

Investors are always evaluating the amount of risk they are willing to take for a certain expected return. Intuitively, the best investment maximizes the return
9. How to Install RStudio on the WSL System

If you are using Windows and don’t want to use the RStudio client on the Windows side, this method will work perfectly.
10. Size Does Matter: Global Control Group for a Bank

Learn how to approach data-driven measurement properly. See what unexpected results we got in a bank and get insights for your own data analytics journey.
11. Neural Network Layers: All You Need Is Inside Comprehensive Overview

Explore an in-depth overview of various neural network layers, their history, mathematical formulations, and code implementations. The publication covers common
12. The Importance of Hypothesis Testing

Hypothesis tests are significant for evaluating answers to questions concerning samples of data.
13. 3 Data Distributions for Counts in Layman’s Terms

Counts are everywhere, so no matter your background, these data distributions will come in handy.
14. Crunch the Lottery Numbers

As we wrap up our journey into the world of lottery data, it’s been a wild ride through numbers and probabilities.
15. You Could Be Wrong About Probability

A quick walkthrough of the three frameworks in probability viz. classical, frequentist and Bayesian through an example.
16. Hinge Loss – A Steadfast Loss Evaluation Function for the SVM Classification Models in AI & ML

Researchers use an algebraic acme called “Losses” in order to optimise the machine learning space defined by a specific use case.
17. How to Use Approximate Leave-one-out Cross-validation to Build Better Models

How to use Approximate leave-one-out cross-validation for hyperparameter optimization and outlier detection for logistic regression and ridge regression
18. Random: Meaning in Everyday Life and in Science

“That’s so random!” Common phrase used to express something is unexpected or without a pattern. Does random mean something different in science?
19. How to Run Impact Analysis Without an A/B Test?

A practical guide to Propensity Score Matching — learn how to estimate treatment effects without running a traditional A/B test.
20. How to Use Propensity Score Matching to Measure Down Stream Causal Impact of an Event

How can we know ours ads are making impact that we aim for? What if targeted ads are not working the way we want them to?
21. Everything you need to know about YCombinator S19 startups

It is not a secret to anyone that YCombinator is the most successful accelerator in the world. They have made well over 2,538 investments.
22. The Concept Behind “Mean Target Encoding” in AI & ML

An introductory article describing the concept & intuition behind “Mean Target Encoding” in AI&ML, its pros, cons and implementation with a real-time example.
23. Over 60% of Writers Already Use AI in Their Writing Workflow

Hackernoon polled readers on whether they would use AI tools for their writing/copywriting workflow. Nearly 70% are open to the idea.
24. The State of Vue 2022: What Has Changed In The Last 12 Months

Check the latest statistics on the usage of Vue and learn why this framework is growing in popularity.
25. Quantitative ROI Modeling for Tech Product Investments

How tech executives can harness advanced econometric and AI-driven simulation techniques to make informed investment decisions under uncertainty?
26. Outlier Detection with Chi Square

This is a simple method for outlier detection, the procedure basically is a Quantile of weibull distribution of the chi square test in python.
27. How Bayesian Tail-Risk Modeling can save your Retail Business Marketing Budget

Why average ROI fails. Learn how distributional and tail-risk modeling protects marketing campaigns from catastrophic losses using Bayesian methods.
28. Statistics Cheat Sheet: A Beginner’s Guide to Probability and Random Events

A beginner’s guide to Probability and Random Events. Understand the key statistics concepts and areas to focus on to ace your next data science interview.
29. Navigating the Maze of Multiple Hypotheses Testing—Part 2: Practical Implementation

In this article, we will explore practical implementation with Python code and interpretation of the results.
30. A Programmer’s Guide to Crack ‘Twice the Work, Half the Time’ Code

Modern methods of software measurement do not provide a strong base for continuous improvement. This article tries to fill this gap.
31. The Evolution of Decision Trees: From Shannon Entropy to Modern Applications and Specialties

Discover the evolution and importance of decision trees in machine learning, from their early beginnings in the 1960s to their widespread use in modern ensemble
32. Applying Statistical Analysis to Intraday Forex Trading Using SQL
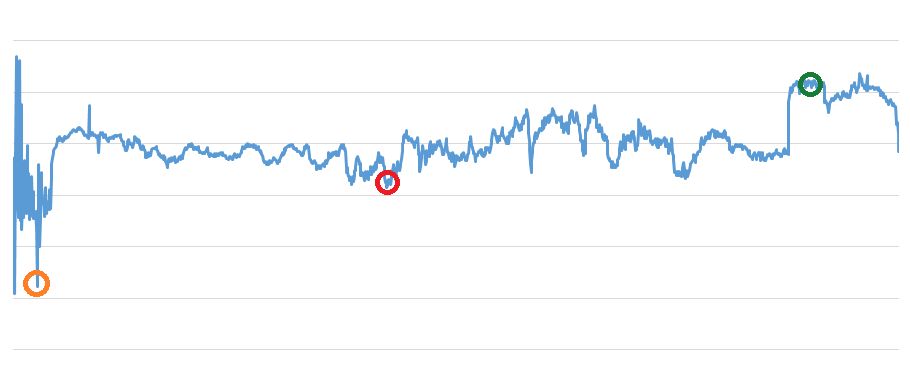
Statistical Analysis, Intraday Forex Trading, Using SQL
33. Beyond A/B Testing — Switchbacks and Synthetic Control Group
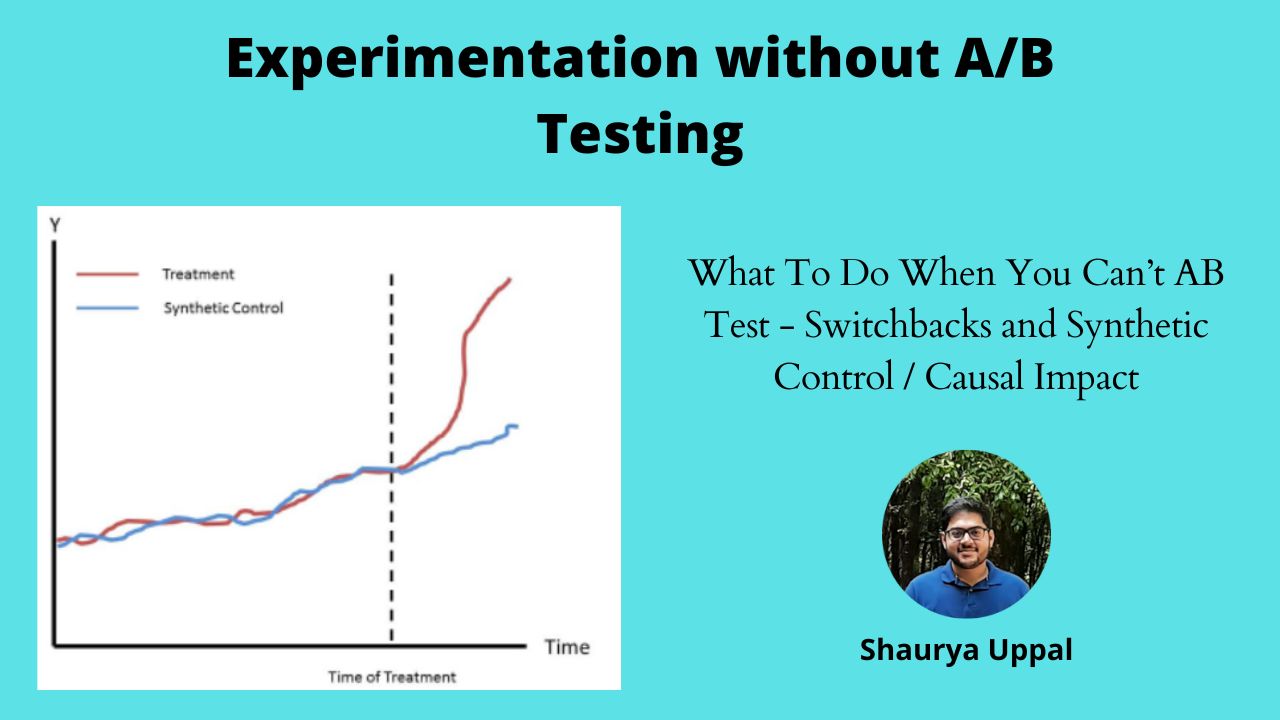
Experimentation designing in the marketplace without AB-Testing using Synthetic Control Groups and Switchbacks.
34. Model Calibration in Machine Learning: An Important but Inconspicuous Concept

A prelusive article comprehending the concept behind model calibration, its importance and usage in machine learning model development.
35. Waiting for your A/B Testing Results — Guide for Easy Acceleration

Explore techniques for accelerating A/B testing, including paired testing, covariance adjustment, stratification, CUPED, CUPAC, and Bayesian approaches.
36. AB Testing For Digital Products

An overview of AB testing during the design of digital products like UX, digital marketing advertisements and software development.
37. 👨🔬️ Top 10 Data Scientist Skills to Develop to Get Yourself Hired

List of Top 10 Data Scientist skills that guaranteed employment. As well as a selection of helpful resources to master these skills
38. How I Broke Into Data Science

A software engineer’s journey into data science at Yelp and Uber
39. The Notions behind “Model-Based” and “Instance-Based” Learning in AI & ML

A prelude article elucidating the fundamental principles and differences between “Model-based” & “Instance-based” learning in the branches of Artificial Intelligence & Machine learning.
40. TikTok’s Engagement Rate is an Average of 5.96% in 2022

Boost your social media strategies for 2022 by knowing the most important up-and-coming TikTok marketing trends and engagement stats.
41. From Time Series to Causal Scenarios: A Statistical Guide to Counterfactual Forecasting

Learn how counterfactual forecasting helps data scientists measure true revenue impact by simulating causal scenarios beyond traditional time series models.
42. How Many Days of Your Life Have You Spent in an Uber?

I’ve spent 12 days in Ubers over the last 3 years. Read this to find your own lifetime Uber stats.
43. Why Algorithmic Fairness is Elusive

In 2016, Google photos classified a picture of two African-Americans as “gorillas.” Two years later, Google had yet to do more than remove the word “gorillas” from its database of classifications. In 2016, it was shown that Amazon was disproportionately offering one-day shipping to European-American consumers. In Florida, algorithms used to recommend detention and parole decisions on the basis of risk of recidivism were shown to have a higher error rate among African-Americans, such that African-Americans were more likely to be incorrectly recommended for detention who would not go on to re-offend. When translating out of a language with gender-neutral pronouns, and into languages with gendered pronouns, Google’s word2vec neural network injects gender stereotypes into translations, such that pronouns become “he” when in conjunction with “doctor” (or “boss,” “financier,” etc.) but become “she” when translated in conjunction with “nurse” (or “homemaker,” or “nanny,” etc.).
44. Use the 80/20 Rule with Moderation
The 80/20 rule, a.k.a. Pareto principle, has been perpetuated along the lines: “80% of the effects come from 20% of the causes.” Different cases where the rule emerges have been studied, in the last century, by great personalities such as Vilfredo Pareto (land ownership in Italy), George Kingsley Zipf (word frequency in Languages), and Joseph M. Juran (quality management in industries). Working as a Data Scientist, I have seen enough of the 80/20 rule being invoked in business meetings followed by a round of applause 👏👏👏. Also, I have read numerous LinkedIn posts alike. Most times, it is just a reckless stretch of the rule. But what is the danger here, if any? After all, profits matter more than mathematical and statistical rigor.

45. Top 5 Tech Startup Trends in 2020

According to Statista, the global startup economy generates nearly $3 trillion. Startups have always been the driving force behind the world market, bringing new ideas, and transforming familiar business systems. Unfortunately, the economic crisis associated with Covid-19 has not spared this area.
46. How to Create A Funnel Chart In R

Funnel Chart in R, A funnel chart is mainly used for demonstrates the flow of users through a business or sales process.
47. How to Predict News: Message Sequence Analysis & Digital Intuition
We can be warned about upcoming events predominantly occurring under similar circumstances.
48. How a Data Scientist Sees a Deck of Cards
The Data Scientist Creativity Paradox

49. Tales of the Undead Salmon: Exploring Bonferroni Correction in Multiple Hypothesis Testing

Bonferroni correction as a solution for multiple comparisons problem in A/B tests. Here is an explanation of how it works with a simulation written in Python.
50. What LinkedIn Tells Us About Developer Population in the World

There are tons of articles about the number of developers in the world. But most of them either lack good methodology or simply borrow statistics from other resources.
51. Top 7 Most Used Web Frameworks Among Developers Worldwide 2021 [Statistics]

Top 7 Most Used Web Frameworks Among Developers Worldwide 2021 [Statistics]
52. Use Up-Sampling and Weights to Address Imbalance Data Problem

Have you worked on machine learning classification problem in the real world? If so, you probably have some experience with imbalance data problem. Imbalance data means the classes we want to predict are disproportional. Classes that make up a large proportion of the data are called majority classes. Those that make up a smaller portion are minority classes. For example, we want to use machine learning models to capture credit card fraud, and fraudulent activities happens approximately 0.1% out of millions of transactions. The majority of regular transactions will impede the machine learning algorithm to identify patterns for the fraudulent activities.
53. Detecting Changes in COVID-19 Cases with Bayesian Models
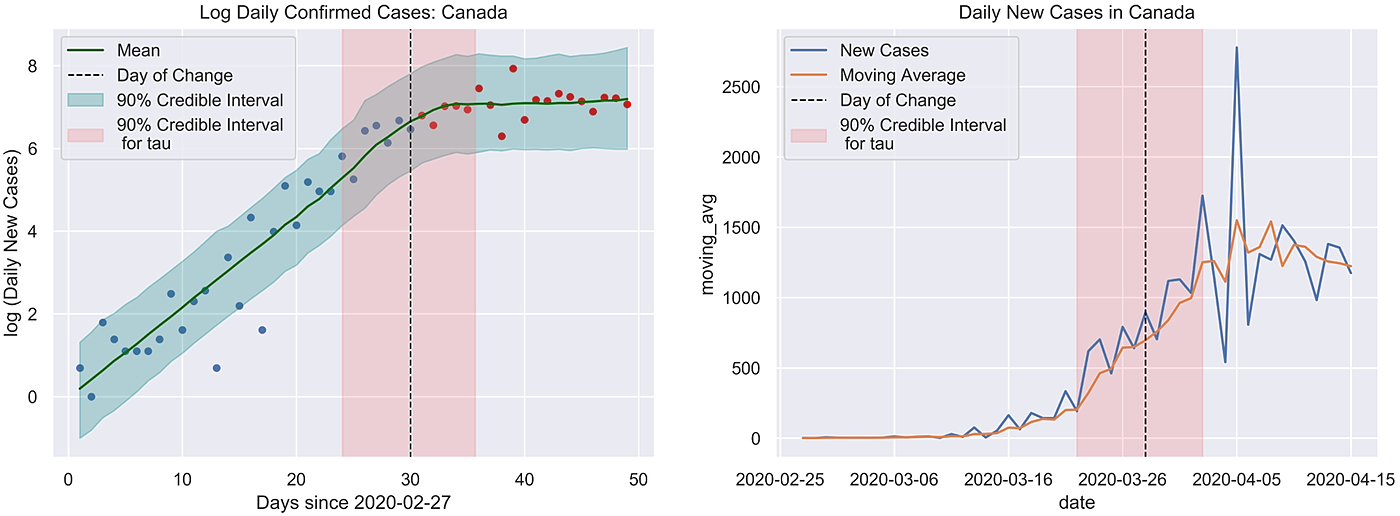
Bayesian change point model to estimate the date that the number of new COVID-19 cases starts to flatten in different countries.
54. 70 Stories To Learn About Statistics

Learn everything you need to know about Statistics via these 70 free HackerNoon stories.
55. Making Sense of Bitcoin’s Volatility Clustering and How To Take Advantage of it

In 2019, Bitcoin’s (BTC) volatility was erratic. On one day alone, the price of bitcoin changed by over 40%. However, for most days, the change in price hovers around 1%-2%. The purpose of this article is to investigate the nature of BTC’s volatility and see what kind of strategies are suited best to take advantage of it.
56. The Intuition Behind the “LIME” Concept in AI & ML

A preambular article describing the fundamental principles & intuition behind the “LIME” concept in Artificial Intelligence & Machine learning.
57. Equivalence Testing: An O(log log n)-query Fully Adaptive Algorithm

Our algorithm can also be modified slightly to obtain a fully adaptive algorithm with sample complexity O˜(log log n).
58. Correlation vs. Causation: Why Correlation Does Not Imply Causation

The terms correlation and causation are quite often confused, however, they are not synonyms and this article specifies the main reasons why.
59. Understanding Principal Component Analysis
Principal Component Analysis (PCA) is a statistical technique used for dimensionality reduction in data analysis and machine learning.
60. Statistics Show AI Adoption and Investment has Risen Rapidly in the Past 2 Years

The concept of artificial intelligence as a non-human intelligence originated in the 1950s, but no one then could have imagined what success AI would achieve in the 2020s. In just 70 years, we have had bots that can learn, solve complex computational problems, write related texts, generate images and music, and analyze tons of information in seconds.
61. The Polls Are Looking Good for Harris. With the 2016/20 Polling Error, She’s in Trouble as of Now

I’ve started playing around with publicly available polling data for the 2024 U.S. presidential election.
62. [Dev Update] Hacker Noon + Google Analytics = Happy Authors

Austin here, your friendly neighborhood software engineer from Hacker Noon, with some exciting news! We are pleased as punch to announce that contributing writers can now see pageviews and total time reading for all stories published with Hacker Noon since we began in 2016. How cool is that? Previously our stats page was only accessible for recent story performance.
63. Why AI is a Fear-Driven Discipline

People are scared of AI. According to Genpact research:
64. CLIP: An Innovative Aqueduct Between Computer Vision and NLP

A rudimentary article describing the concept behind the “CLIP” algorithm in deep learning, its approach, implementation, scope & limitations.
65. 3 Interesting NFT Statistics: How NFTs are Being Adopted Globally

NFT ownership has increased throughout the globe, with Southeast Asian nations such as the Philippines, Thailand, and Malaysia leading the pack.
66. Granger Causality: Principle of Cause and Effect Explained

… in a world full of data, we can understand the impact with clever methods. Meet Granger causality.
67. Equivalence Testing: The Power of Bounded Adaptivity: Acknowledgements and References

Acknowledgments of the research in Equivalence Testing.
68. The Hundred-Page Machine Learning Book [Review]

I first ordered The Hundred-Page Machine Learning book back in May and am only just now finishing it up. In COVID-time, that was about 10 years ago. As you might have inferred, this book is NOT a quick read. What it lacks in easy reading, it makes up for in efficiency. This book swallows up the heavyweight mathematics textbooks and spits out a slim product no thicker than the width of my smartphone. From page one all the way to page 136, Andriy Burkov, the author, does not waste a single word in distilling the most practical concepts in machine learning. You read that right. It is MORE than 100 pages! Sounds like the book has some bias. Get it? Now get ready for my hundred-page book review. Just kidding.
69. Logarithmic Scaling: Handling Extreme Data Variability

Learn how logarithmic scaling helps analyse datasets with extreme variability.
70. Key 2022 Statistics in the No-Code/Low-Code Market

We explore a low-code/no-code market poised for exponential growth in the coming years.
71. Who even reads HackerNoon?

You, obviously. And millions of people from around the world. What audience are you advertising to? Who are you writing for? Learn more about our readers here.
72. Digital Workspaces: Hacking the Future of Work

A look at how to engage in the future of work through digital workspaces
73. A Single Speed Test is Fun — Hundreds of Them, May Actually be More Accurate

Releasing the first internal build of the NordVPN apps that included NordLynx – our brand new protocol built on the backbone of WireGuard® – was an exciting moment for the team. Everyone started posting their speed test results on Slack and discussing the variance. While most of the time NordLynx outperformed other protocols, there were some cases with slightly worse speed results.
74. Quantifying Variability: Variance, Standard Deviation, and Coefficient of Variation

There are many ways to quantify variability, however, here we will focus on the most common ones: variance, standard deviation, and coefficient of variation. In the field of statistics, we typically use different formulas when working with population data and sample data.
75. Kannada-MNIST:A new handwritten digits dataset in ML town

TLDR:
76. Causal Analysis – Experimentation (AB Testing) and Statistical Techniques

Causal analysis background and overview of different techniques to perform a causal analysis.
77. What if Street Crime Statistics Matched Those of Cybercrime?

If street crime statistics matched those of cybercrime, our world would resemble the Wild West.
78. How to Use Psychological Tricks to Bring Numbers to Life

It’s easy to visualize placing 10 chairs in a room, but it’s difficult to visualize 1,000 chairs. In order to acquire an accurate frame-of-reference, most of us would need to start by sketching out a diagram. Understanding this and applying it to business, the last thing you want is for your customer to have to hunt down a pen, paper and calculator in order to understand your numerically-based product features – don’t assign homework. Captivate customer attention by applying these clever ways to convert numbers into things people care about.
79. Educational Byte: Checking Obyte Stats and Resources

From some general data to liquidity providers’ (LP) reward lists, let’s explore some handy Obyte-related portals.
80. [Infographic] The State of Conversational AI in 2020

Conversational AI was always poised to take off in 2020. In fact, Gartner predicted that 80% of businesses would implement some sort of conversational interface by the end of this year. With the emergence of COVID-19 came compounded growth for the category – and I wanted to capture just how far we’ve come. So for the conversationally curious out there, I created this infographic that offers a clear depiction of where conversational AI stands at this very moment in time.
81. Data-Driven Decisions at Scale: A/B Testing Best Practices for Engineering & Data Science Teams

Ship features like scientists: randomize, measure, and learn fast.
82. Why Data Lies (and Your Model Might Too): The Curious Case of Simpson’s Paradox

Simpson’s Paradox is a cognitive trap that traps data-crunchers and machine learning tinkerers.
83. Breaking Down Secretary Problem

What did you think of when you had a crush on someone? Did you fantasize about marriage with him/her? When you were in some serious relationship, did you plan marriage with your partner? How did the relationship turn out? Some relationships turn into a marriage, and some don’t. Hearing stories of many friends, I see extremely few people being in a relationship (and later marrying) with only one person whole over their life.
84. Calculating a Dynamic Truncated Mean in Power BI Using DAX: A Quick Guide
By implementing this DAX pattern, you create a robust, dynamic, and outlier-resistant KPI.
85. How to Obtain A Fully Adaptive Algorithm With Sample Complexity O˜(log log n)

The paper considered the problem of equivalence testing of two distributions (over [n]) in the conditional sampling model.
86. The Global Expansion of Cybercrime

In our digitally interconnected world, the issue of cybercrime stands as an ever-growing concern, casting a long, menacing shadow over the information age. With technological advancements and an increasing reliance on digital platforms in every facet of our lives, the virtual realm has become a complex, bustling ecosystem. However, along with these exciting opportunities, it has also given rise to a new class of criminals who exploit the vulnerabilities of this intricate digital landscape, threatening not only our personal data but also national security and the global economy.
87. How Popular is Right-Wing Content on Facebook?

Facebook has been criticized in the past because many believe they are allowing right-wing content to run rampant on the site.
88. The Ouroboros Effect of Data Aggregation and Scraping

Learn how web scraping and data aggregation might feed of each other, unintentionally creating an effect of decision-making convergence.
89. How to Build Connections for A/B Testing and Linear Regression: An Essential Guide

In a world of LLM and cutting-edge architectures, linear regression quietly plays a crucial role, and it’s time we shine a light on how it can be beneficial.
90. These Are The Secret Weapons of Fake News

Modern fake news has evolved into a complex organism, carefully designed to hide its deceptive mechanisms from any potential victim. But although the fake news field has grown into every possible digital channel, the truth is that at its core, in order to be effective, it still relies on exploiting our most basic human characteristics.
91. Why I Spent Years Writing a Children’s Book on Data Science

I wrote a children’s book on data science to inform others who have a hard time understanding data science and machine learning concepts, especially kids!
92. The Base Rate Fallacy: Why Your Smartest Model Still Gets It Wrong

Are AI models as accurate as the validation test says?
93. Numbers Don’t Lie But They Are Easily Misinterpreted All The Time

therefore a working compromise between these 2 extremes should be found on a case-by-case basis
94. EquivTester Samples In Equivalence Testing Algorithm

The article takes an example of an EquivTester algorithm and how to convert it into a one-round algorithm, using the COND model.
95. Polling Error or No Polling Error? The Truth Will Probably Lie Somewhere in the Middle

It’s unlikely polling error in 2024 will be as big as in 2016/20. It’s just as unlikely there will be none. The truth will probably lie somewhere in the middle.
96. Variance Inflation Factor – A Pertinent Statistical Metric for the Discernment of Multicollinearity

97. Stop Deleting Outliers—Here’s What You Should Do Instead
Learn 3 simple, effective methods to detect and handle outliers in your data. Improve analysis accuracy and make smarter decisions with clean datasets.
98. How to Choose the Right Payment Gateway for the E-commerce Business

E-commerce is a promising business area that shows high growth rates each year.
99. An Efficient One-Round Adaptive Algorithm In Equivalence Testing

This part presents an O(log log n)-query fully adaptive algorithm. The algorithm is a one-round adaptive tester for the equivalence testing problem in the COND
100. Simple Tips For A Successful Application Performance Monitoring

You finally went live, congratulations! Now what?
101. E-Commerce as the Cake, Not the Cherry on the Cake

E-Commerce has spiraled due to the pandemic environment, leading to irreversibly enhanced online shopping.
102. SAMP Model Vs COND Model In Equivalence Testing

This article dives into the SAMP model and the COND model in equivalence testing to find out which is the most optimal for the problem.
103. Stop Torturing Your Data: How to Automate Rigor With AI

Why improvisation kills research, and how to use AI to enforce methodological discipline.
104. Technical Analysis Of The Correctness And Complexity Of EquivTester

The paper provides a technical analysis of the correctness and complexity of EquivTester using COND model and equivalent distributions.
105. Winning in Online Skilled Gaming… Err… Gambling! A Look at Optimistic+ and More

This series of articles covers the techniques and gyan on winning in skilled games which are variants of Roulette, Wheel of Fortune and Baccarat.
106. Understand The Distributions Used In Equivalence Testing

The research provides an affirmative answer to the challenge of equivalence testing.
107. From Correlation to Checkerboards: Model-Free Exploratory Data Analysis for Categorical Data Lands
Checkerboard copulas bring clarity to categorical Exploratory Data Analysis by revealing structure that traditional statistical methods and correlations miss.
108. #CorrelateThis – The Neural Activity of Mice Indicates Cryptocurrency Price Fluctuations

In his research, Gvido reported the discovery of neurons that showed a neural correlation to the price fluctuations of the main cryptocurrencies!
109. Explore The Power of Bounded Adaptivity Through Equivalence Testing

The research provides an affirmative answer to the challenge of equivalence testing.
110. Enhancing Experiment Sensitivity in B2C: A Robust Framework for Heavy-Tailed Metrics

Boost B2C experiment sensitivity with Cross-Fitted CUPED. Learn how to handle heavy-tailed metrics like ARPU without overfitting. Includes Python code.
111. 40% Americans Do Not Know What Affects Their Credit Score

Your customers’ credit score is one of the most important numbers of their financial lives. This three-digit number is the most used credit scoring model by lenders for evaluating a borrower’s creditworthiness or the likelihood that they’ll repay the money.
112. Turning Economic Uncertainty Into Strategic Advantage

Solving Economic Problems with Data
113. Console #17: Japanese Pizza Toast and Turtles
01/12/2019

114. Frequentist Stats Are Failing Your UX Decisions—Here’s a Better Way
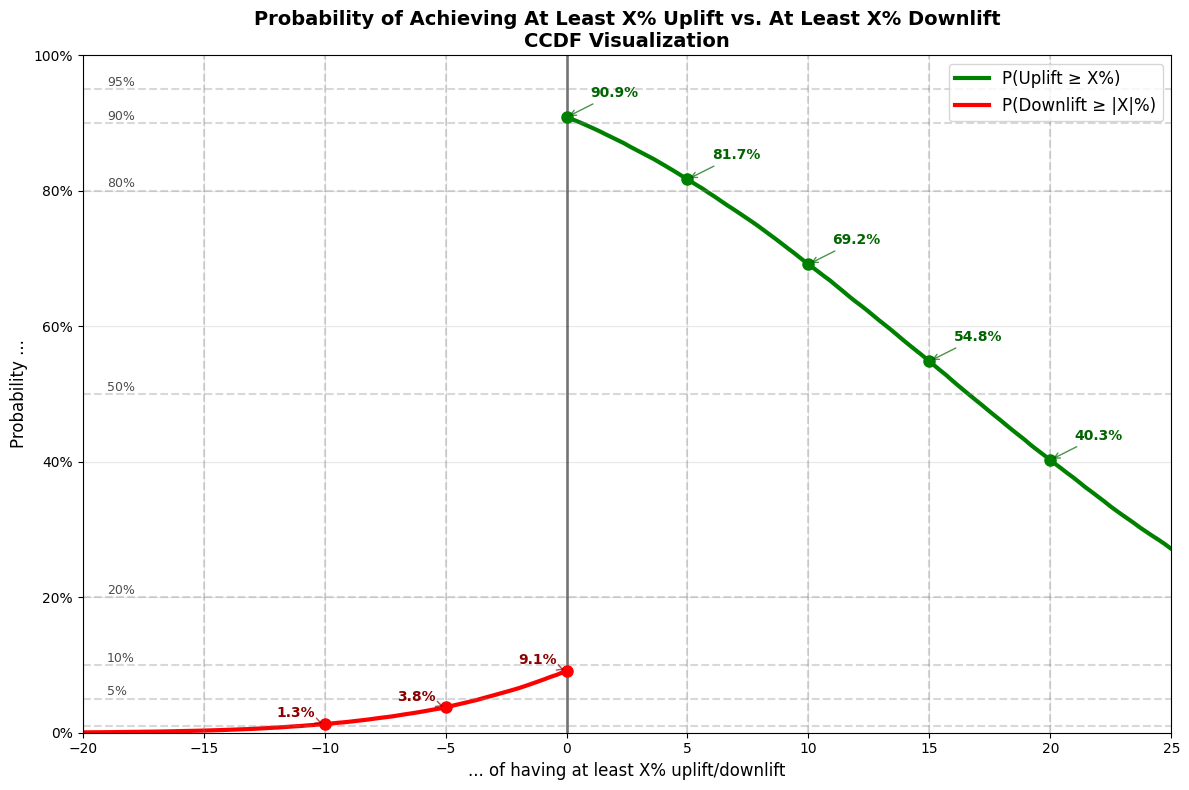
Learn why Bayesian A/B testing offers more intuitive insights than traditional stats, & get practical tips and tools for better UX decisions under uncertainty.
115. The Noonification: Crunch the Lottery Numbers (10/2/2023)

10/2/2023: Top 5 stories on the Hackernoon homepage!
116. Variance is More Than Just A Statistician’s Buzzword

Explaining real world applications and the philosophy of statistical variance through finance, investing, and gambling.
117. Key Application Performance Metrics From the Viewpoint of a Statistician-Turned-Developer
You’ve just released your new app into the wild, live in production. Success! Now what? Your job is done, right? Wrong. Now that you’ve deployed your code, it’s time to monitor it, collect data, and analyze your metrics.

118. Election Forecasts, Schmelection Forecasts

Will the 2024 US presidential election be more similar to 2016/20 or to 2012? What can forecasts actually tell us? Probably not a lot.
Thank you for checking out the 118 most read blog posts about Statistics on HackerNoon.
Visit the /Learn Repo to find the most read blog posts about any technology.