
Implementing resilience patterns for large language model (LLM) inference is critical as generative AI workloads move from experimentation to production at scale. With LLM powered apps now in production, organizations need ways to keep LLM inference highly available, responsive, and cost-effective at scale. Existing resilience best practices like static stability and implementing backoffs and retries still apply. However, generative AI introduces new considerations including model availability, rapidly changing quotas, token limits across multiple providers, and maintaining consistency with newly released models. Amazon Bedrock provides fully managed foundation models with built-in resilience features like cross-Region inference.
When designing inference for production, four dimensions typically guide architectural decisions: availability, response time, cost, and throughput. Availability refers to sustaining inference during model, Region, or provider disruptions. Response time covers how quickly the user receives output, often measured as Time to First Token (TTFT) and Time to Last Token (TTLT). Cost captures per-token and per-request spend and how routing decisions affect it. Throughput reflects how many concurrent requests and tokens per second the system can sustain under load.
These dimensions are interconnected. For example, cross-Region routing improves availability and throughput but may increase response time. The patterns in this post focus primarily on availability: keeping inference operational through failover, geographic distribution, and quota isolation. Future posts will explore response time optimization and cost-aware routing in depth.
In this post, you will learn five practical patterns for building resilient generative AI applications on AWS, progressing from native Amazon Bedrock features to multi-model orchestration using an LLM gateway. These patterns address real-world challenges such as quota exhaustion during unexpected traffic surges, maximizing availability through geographic distribution of inference, and helping prevent noisy neighbor problems in multi-tenant environments. They also support cost optimization through intelligent request routing and give you the flexibility to use multiple models and providers based on your specific requirements.
This crawl, walk, run approach lets you adopt the patterns incrementally based on your application’s maturity and requirements. The accompanying GitHub repository provides code samples demonstrating each pattern.
An incremental approach to inference resilience patterns
You can test out each of the following patterns in your own environment by using the code samples and instructions from this section of the GitHub repository.
Prerequisites
Before starting with the demo, verify that you have the appropriate software installed and your AWS account configured correctly by completing the prerequisites.
Note: Following the patterns in this post will create and use AWS resources that incur charges, including Amazon Bedrock inference requests and Amazon CloudWatch logs. See the Cleanup section to avoid ongoing charges after testing.
Pattern 1: Using Amazon Bedrock cross-Region inference
Amazon Bedrock cross-Region inference (CRIS) is a native feature that provides the foundation for resilient inference by default. You can use cross-Region inference profiles to improve throughput, reduce the likelihood of being throttled within an AWS Region, and distribute model traffic. CRIS removes the manual effort of managing traffic distribution and improves the availability of your application. It automatically routes requests from your source Region to the optimal destination Region based on real-time factors including availability, latency, and current demand. This accounts for unexpected bursts in traffic during peak usage times and reduces the likelihood of service quotas impacting inference.
CRIS profiles are typically tied to commercial Regions within a specific geography like the US or EU, providing the right balance of performance and latency for inference requests. This approach increases aggregate throughput beyond single-Region quotas while maintaining data residency within geographic boundaries.
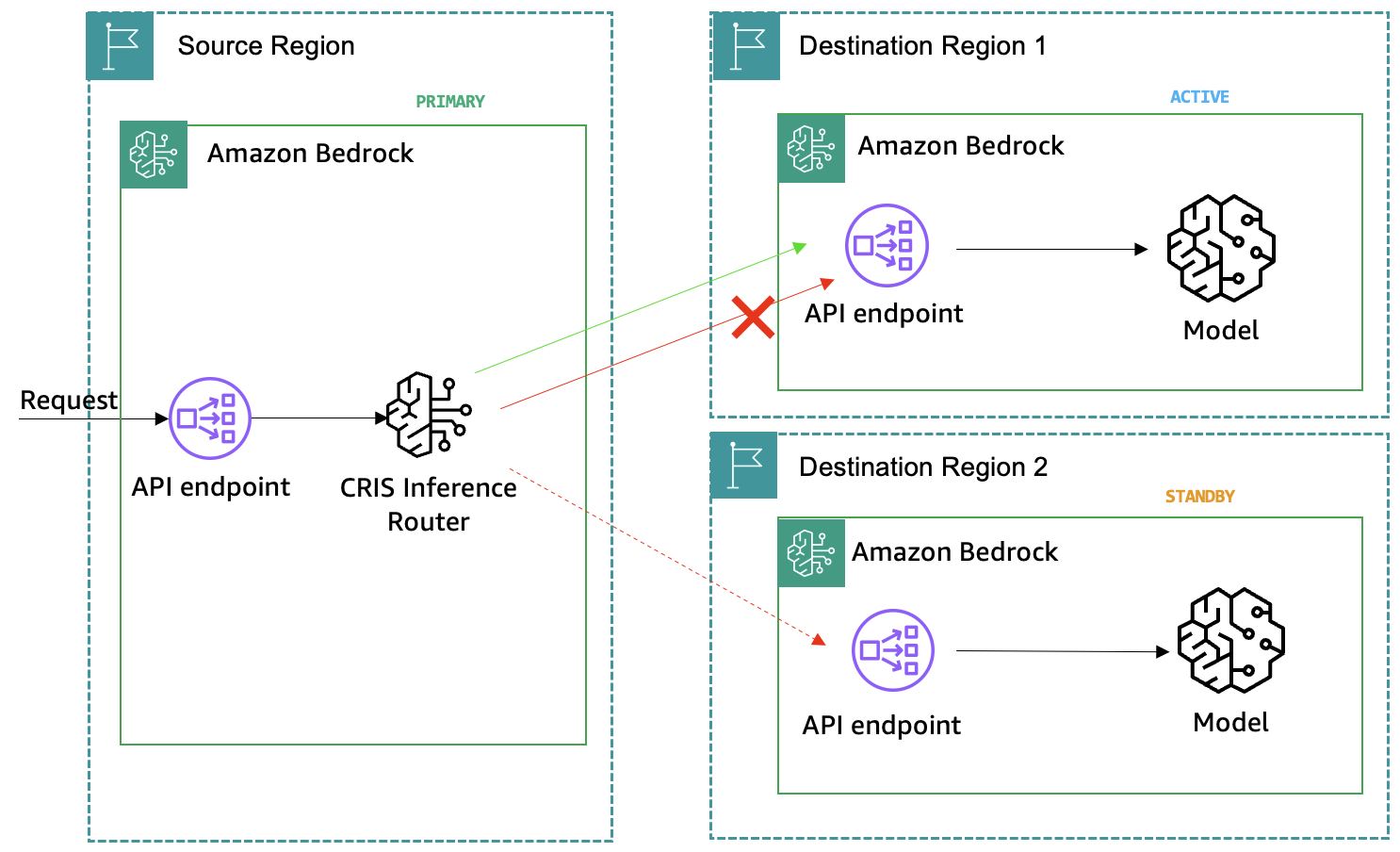
Amazon Bedrock cross-Region inference
For certain use cases that can handle higher latency in inference requests, there is the option to use Global Cross-Region Inference profiles. With a Global profile, requests can be routed across multiple commercial Regions where the model is available for global inference, providing an even greater throughput than with standard cross-Region inference profiles.
For example, in our demo when sending 10 requests to Amazon Bedrock using a cross-Region inference profile, the command output shows how CRIS automatically distributed the model inference across 3 AWS Regions:
| Region | Invocations | Percentage |
| us-east-1 | 1 | 10% |
| us-east-2 | 7 | 70% |
| us-west-2 | 2 | 20% |
Amazon Bedrock cross-Region inference distributes 10 requests across three AWS Regions
Pattern 2: Using multiple AWS accounts
While CRIS multiplies throughput within an AWS account, you can benefit from additional scale and isolation strategies. AWS account sharding distributes requests across multiple AWS accounts, each with independent quotas and CRIS profiles.
Account sharding creates natural fault isolation boundaries where issues in one account do not affect others, making it particularly valuable for multi-team and multi-tenant architectures requiring strict isolation between workloads.
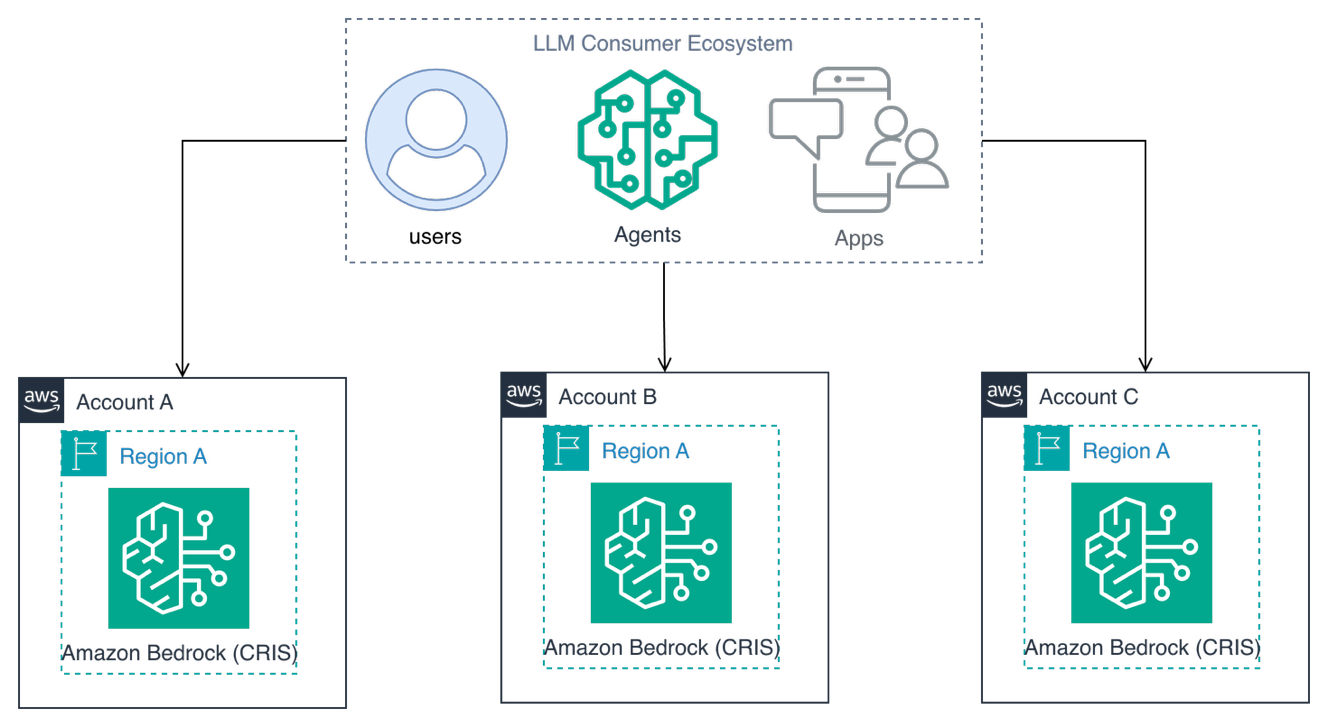
AWS account sharding with Amazon Bedrock cross-Region inference
When running the account sharding demo, we send 10 requests to each of the two configured AWS accounts using cross-Region inference profiles. The output shows how each account independently distributes inference across AWS Regions:
| Account 1 | ||
| Region | Invocations | Percentage |
| us-east-2 | 7 | 70% |
| us-west-2 | 3 | 30% |
| Account 2 | ||
| Region | Invocations | Percentage |
| us-east-1 | 2 | 20% |
| us-east-2 | 3 | 30% |
| us-west-2 | 5 | 50% |
Two AWS accounts independently distributing requests across Regions via CRIS
Using an LLM gateway
For complex production scenarios, an LLM gateway provides routing, failover, and governance capabilities beyond what is possible with direct API calls. A gateway acts as an intelligent proxy between your applications and LLM providers, offering a unified abstraction layer, so you can access multiple models across various vendors through a single API interface. This standardization simplifies integration while embedding capabilities such as responsible AI safeguards, audit logging, automatic retry and fallback logic, and quota management, among many other features, helping your applications remain resilient even when individual models become unavailable.
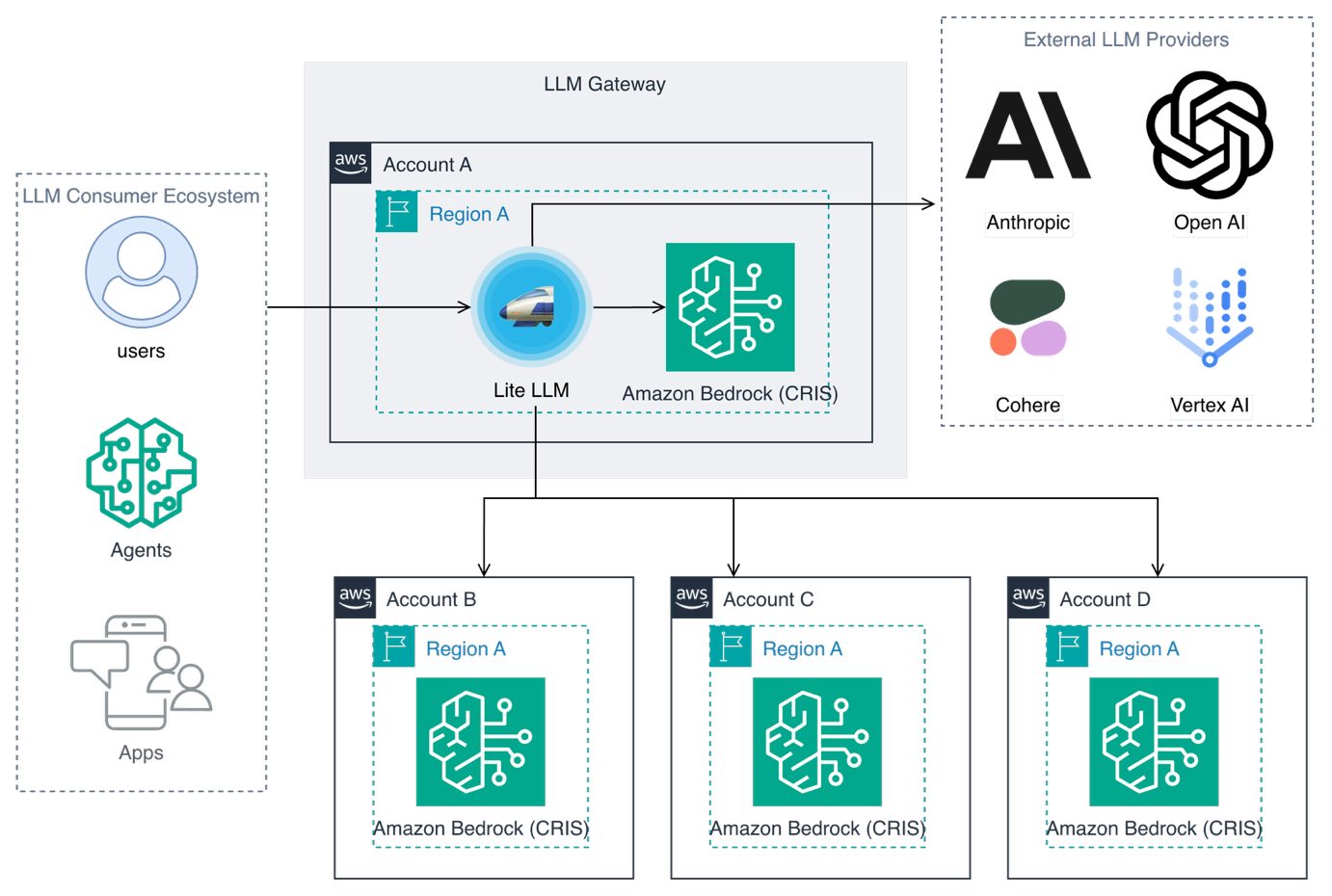
LLM gateway orchestrating requests across AWS accounts and external providers
The gateway supports intelligent request routing and load balancing across multiple models and accounts, maximizing throughput while implementing rate limiting and quota management with per-consumer isolation. This helps prevent noisy neighbor problems in multi-tenant environments while providing comprehensive cost tracking and optimization through usage analytics. Centralized observability and monitoring give you full visibility into your LLM usage patterns with granular per-application insights, helping identify optimization opportunities and troubleshoot issues quickly.
Many open source and commercial LLM gateways are available today. For our demos, we use LiteLLM as a lightweight, open source option running locally to demonstrate these patterns. When deploying at scale, the AWS Solution for Multi-Provider Generative AI Gateway provides a reference implementation and architecture that also uses LiteLLM but adds enterprise capabilities including containerized deployment on Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS), automatic scaling, AWS WAF protection, secrets management, and full observability through Amazon CloudWatch.
Pattern 3: Model fallback
Automatic failover between models supports higher availability even when primary models hit rate limits or experience service disruptions. This pattern is designed to automatically route requests between customer-defined primary and secondary models. If your fallback strategy focuses on optimizing quality and cost rather than quota exhaustion, Amazon Bedrock Intelligent Prompt Routing provides a native option. It dynamically selects the most appropriate model for each request without requiring an external gateway. If calls to the primary models fail, the gateway automatically retries requests using secondary models, supporting high availability even during unexpected spikes in traffic. The fallback strategy also incorporates cost optimization and performance considerations, for example, throttling higher-cost models and falling back to more cost-effective alternatives when appropriate.
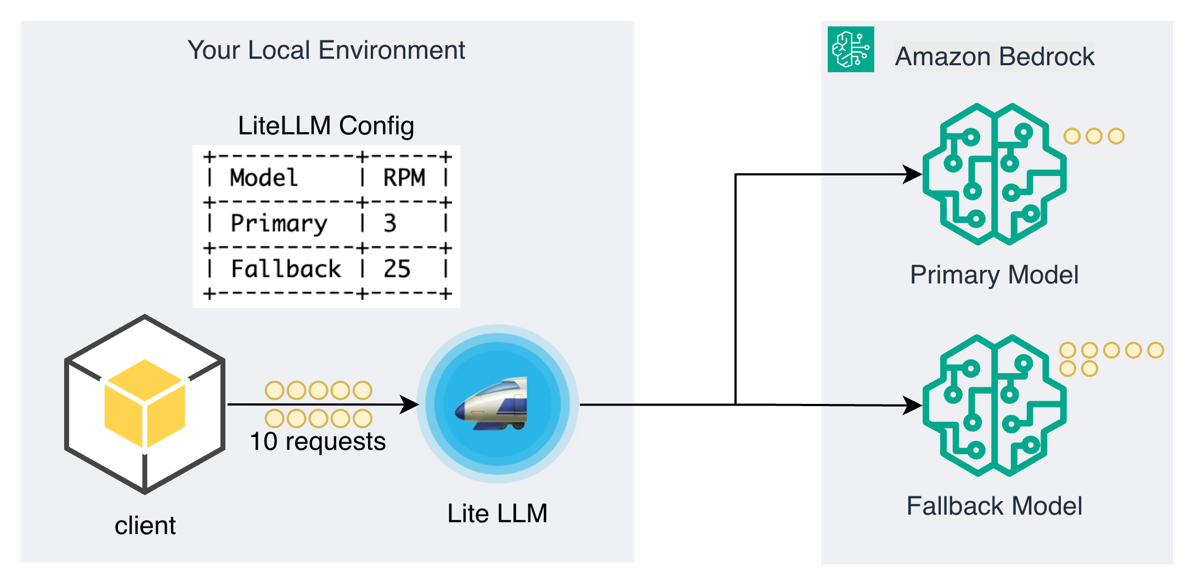
Fallback demonstration with rate-limited primary and higher-capacity fallback models
In our demonstration, the LiteLLM configuration defines a primary model with a restrictive rate limit of 3 requests per minute (RPM) and a fallback model with a higher capacity of 25 RPM. When the client sends 10 concurrent requests through the gateway, the first three requests route to the primary model in Amazon Bedrock. As the primary model reaches its rate limit, LiteLLM automatically diverts the remaining seven requests to the fallback model. The 10 requests complete successfully without manual intervention or application-level retry logic.
The demo output confirms the effectiveness of this pattern, showing high reliability with the 10 requests completing successfully despite the primary model’s rate limit. The distribution reveals that exactly 3 requests were handled by the primary model before reaching its quota. The remaining 7 requests failed over to the fallback model, demonstrating the gateway’s ability to maintain service availability through intelligent routing.
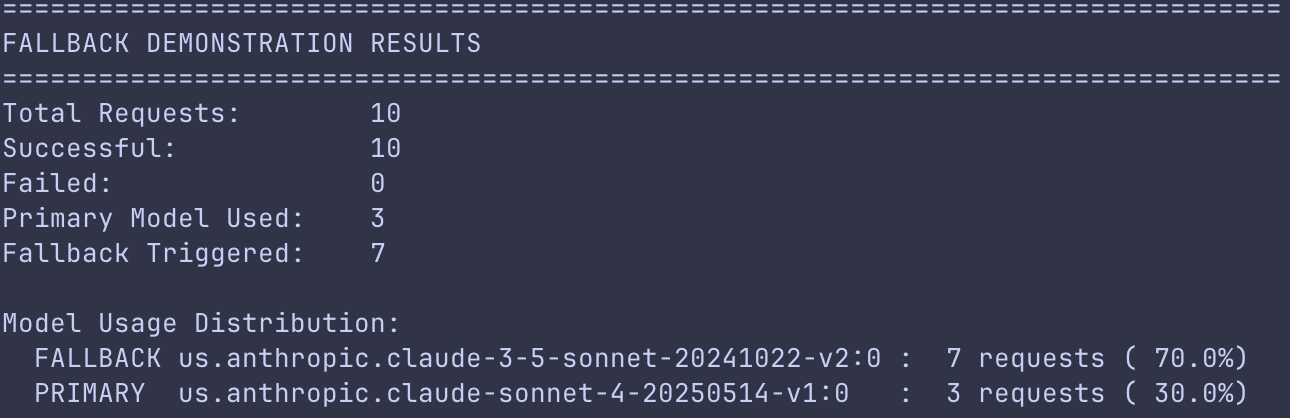
Fallback demo output showing model distribution
Pattern 4: Load balancing across models
The load balancing pattern distributes requests across multiple model instances to optimize resource utilization and helps prevent bottlenecks. This approach not only maximizes utilization but also allows you to quickly scale by adding or removing model instances as needed. For example, when evaluating new models before full deployment, you can implement weighted routing or A/B testing strategies to direct only a small percentage of requests to the new model while the majority continue to use proven models.
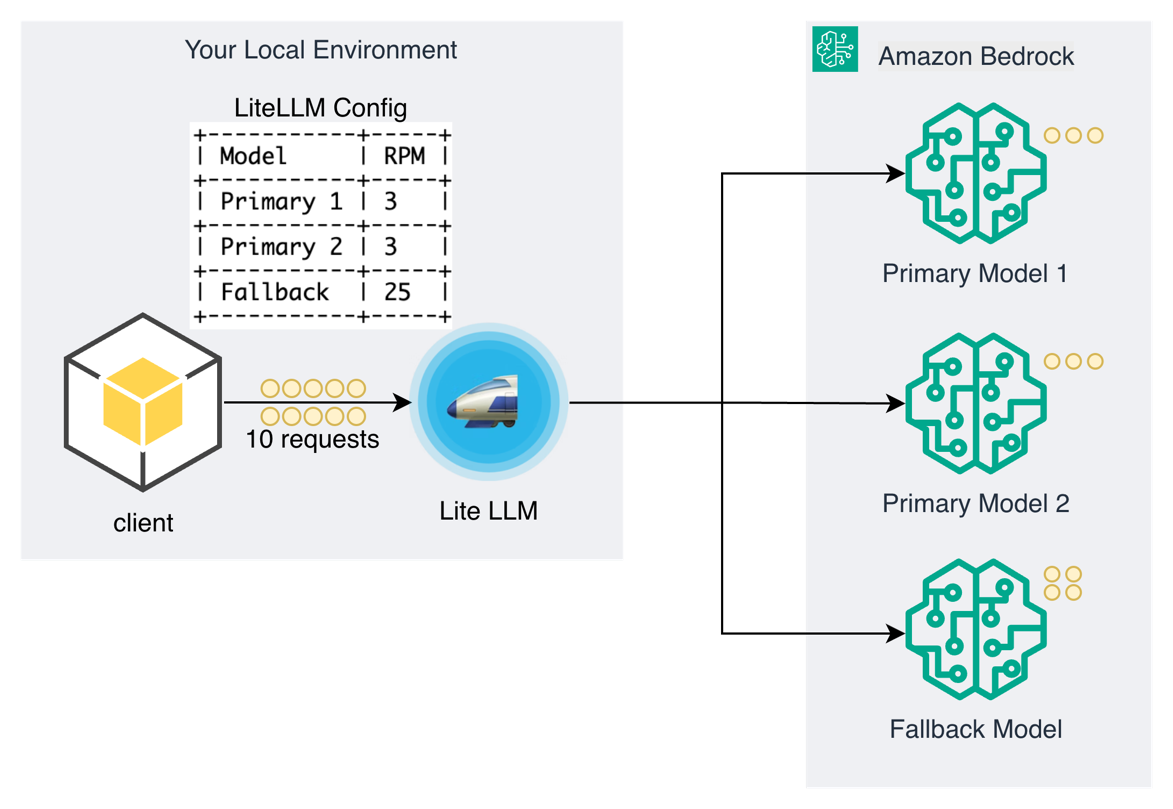
Load balancing across primary models with fallback overflow
In our load balancing demo, the gateway successfully distributes 10 concurrent requests across two models using a shuffle strategy. The load balancer initially routes 3 requests to each of the two configured primary models, and when it reaches its rate limit, the remaining 4 requests are automatically redirected to the fallback model. The result is a 100% success rate, demonstrating how load balancing works together with the fallback strategy.
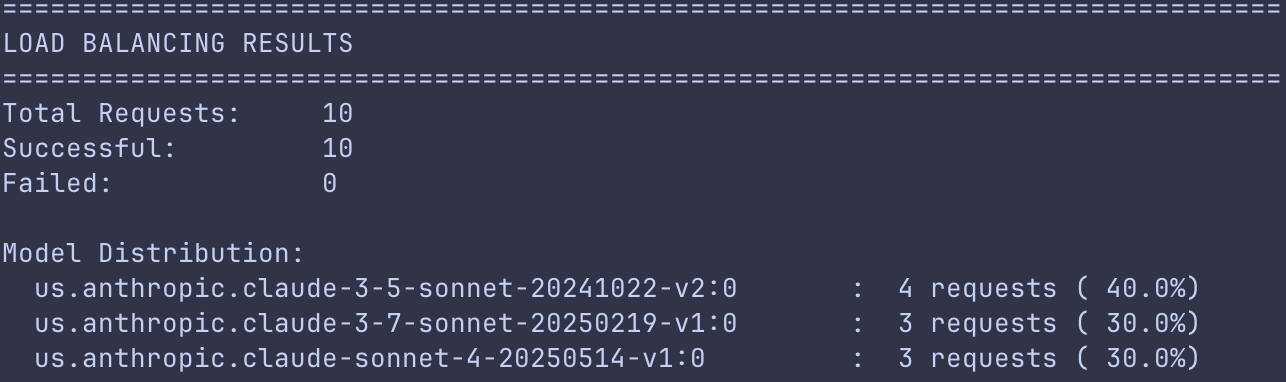
Load balancing demo output
Pattern 5: Multi-tenant quota isolation
The multi-tenant quota isolation pattern creates logically isolated environments equipped with their own quotas and rate limits to manage requests in multi-tenant environments. By implementing independent rate limiting buckets for each consumer, this pattern helps prevent “noisy neighbor” challenges where requests from one consumer negatively impact other consumers’ performance. Each tenant receives a dedicated quota regardless of other tenants’ usage patterns, supporting fair resource allocation and maintaining consistent service quality across consumers.
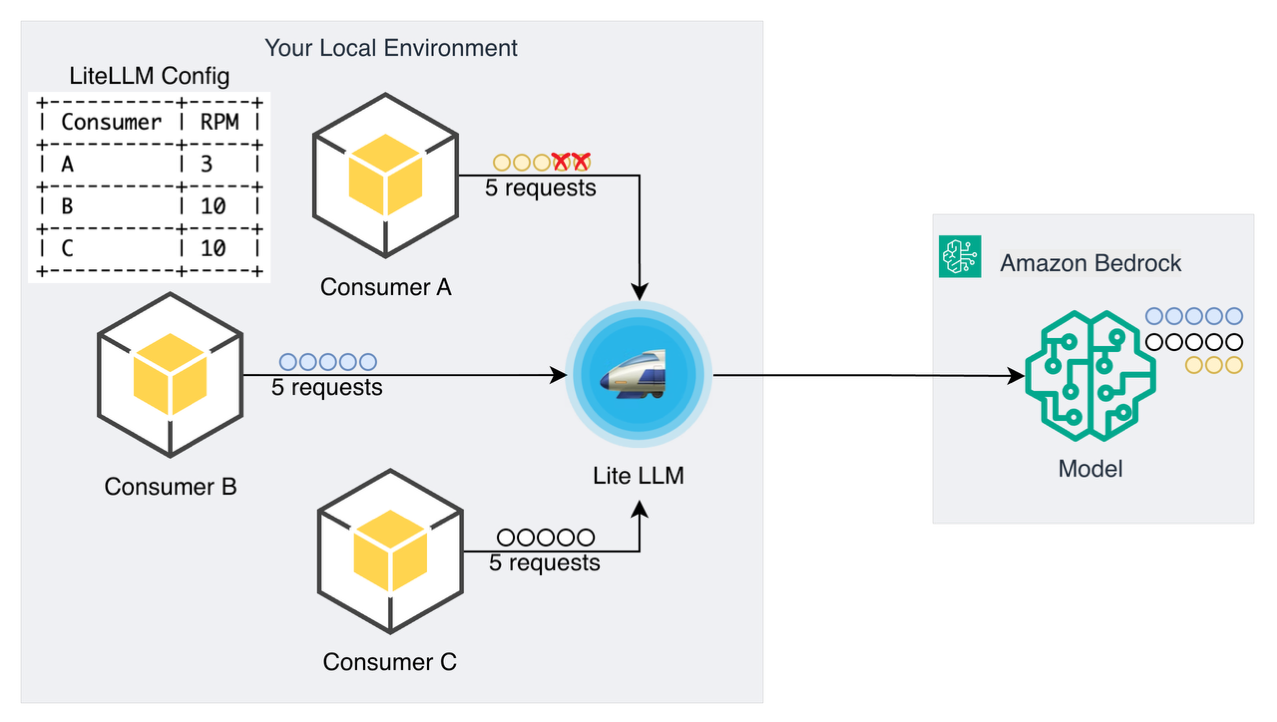
Multi-tenant quota isolation with independent rate limits per consumer
The pattern is ideal for environments where multiple applications share model resources while requiring predictable performance and isolation confidence.
In our demo, three consumers with different rate limits attempt to access the same model simultaneously. Consumer A is configured with only 3 requests per minute (RPM) allowed, while Consumers B and C have 10 RPM each. When the three consumers each send 5 concurrent requests, the gateway enforces individual quotas. Consumer A experiences rate limiting with only 3 requests succeeding and 2 being rejected. Consumer B and Consumer C achieve 100% success rates with all 5 requests processed.
| Quota Isolation Analysis | ||||||
| Consumer | Type | Success Rate | Total | Success | Failed | Rate Limited |
| A | Noisy | 60% | 5 | 3 | 2 | 2 |
| B | Normal | 100% | 5 | 5 | 0 | 0 |
| C | Normal | 100% | 5 | 5 | 0 | 0 |
Multi-tenant isolation demo output
Cleanup
Warning: The following cleanup steps will permanently delete CloudWatch logs. If you need to retain logs for audit or analysis purposes, export them before proceeding with cleanup.
To avoid ongoing charges in your account, complete these steps to stop the gateway and delete the CloudWatch logs.
Important considerations
The preceding guidance makes certain assumptions about workload requirements, data security and compliance obligations, and performance needs. As with most things, the answer to “When should I use these patterns?” is “It depends!”. The following are a few use cases where applying these patterns makes sense.
Applicable scenarios and use cases
High availability requirements: When your application cannot tolerate downtime, multiple models provide automatic failover. If your primary model hits rate limits or experiences outages, requests route to backup models, maintaining 100% availability.
Scaling beyond single model quotas: Individual models have throughput limits. Using multiple models (even the same model type across different accounts/Regions) multiplies your total available capacity. This is essential for high-volume applications where request volume can exceed single model quotas.
Multi-tenant isolation: In software as a service (SaaS) applications, different customers can use different models or model instances, helping prevent one customer’s usage from impacting others.
Development vs production: Separate model configurations for testing (cheaper, faster models) and production (higher quality models) without code changes.
Conclusion
This post covered multiple patterns for resilient LLM inference, starting with Amazon Bedrock native cross-Region inference and ending with more complex patterns that required implementing an LLM gateway. Using these strategies, you can improve the resilience of your generative AI powered workloads and gain granular control over model availability and failover strategies, including dedicated control for specific consumers and applications.
We invite you to experiment with these patterns in detail using the accompanying GitHub repository, which provides code samples and step-by-step instructions for testing each pattern. For a comprehensive reference implementation of a production-ready generative LLM gateway, explore the AWS Solution for Multi-Provider Generative AI Gateway.
For more generative AI architectural patterns and best practices, visit the AWS Artificial Intelligence Blog.
If you have any comments or questions, leave them in the comments section.
TAGS: Generative AI, Amazon Bedrock, Resilience, Architecture