Unlock cost savings with the new scale down to zero feature in SageMaker Inference

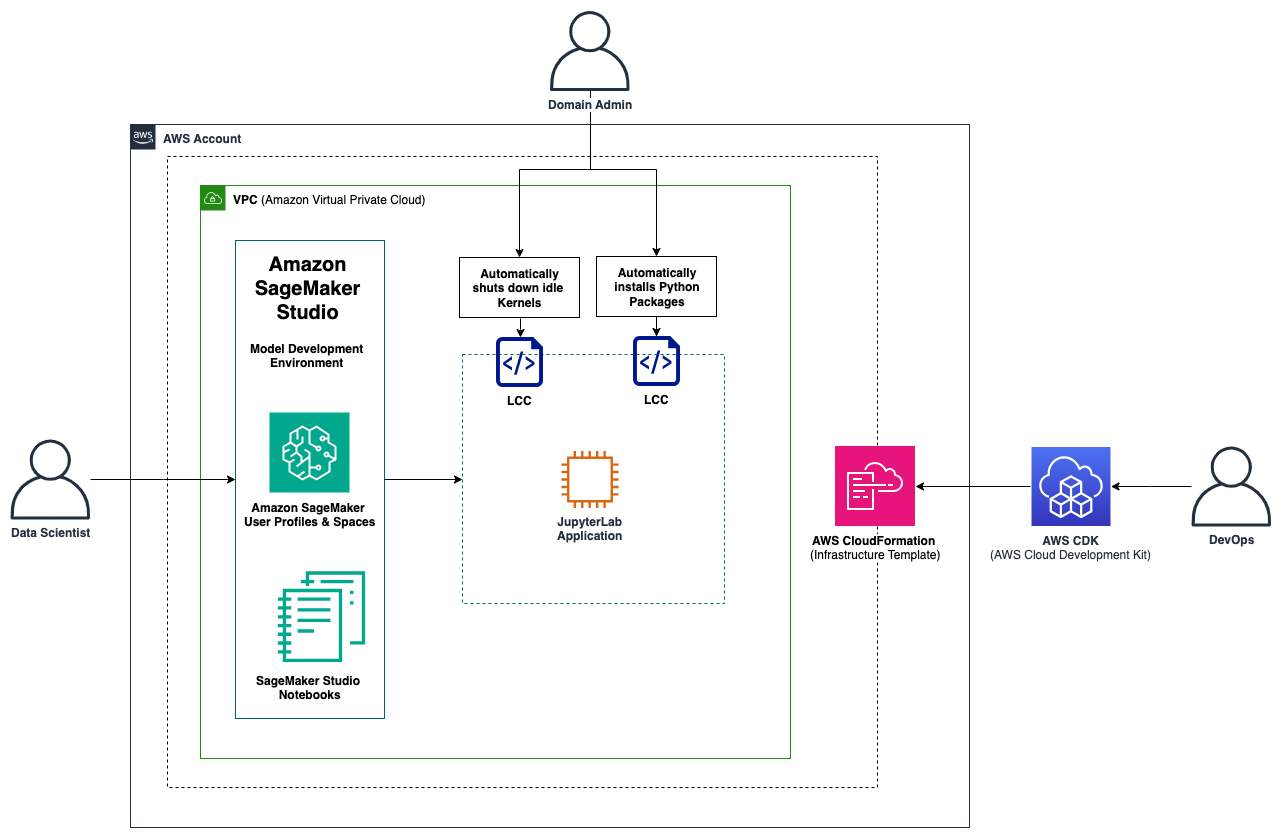
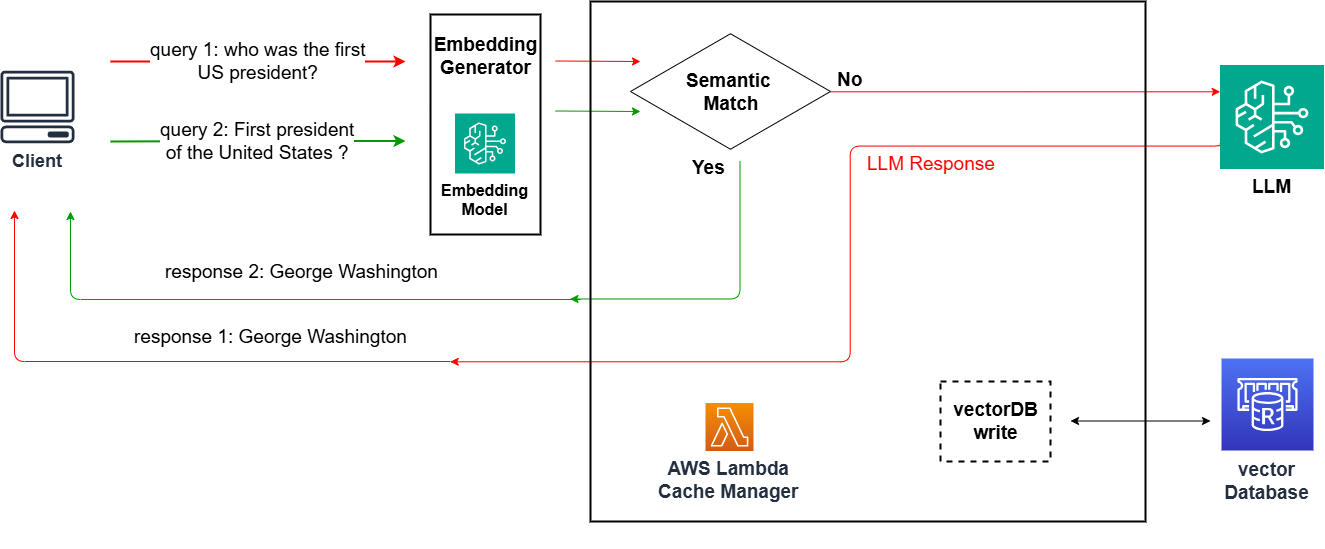
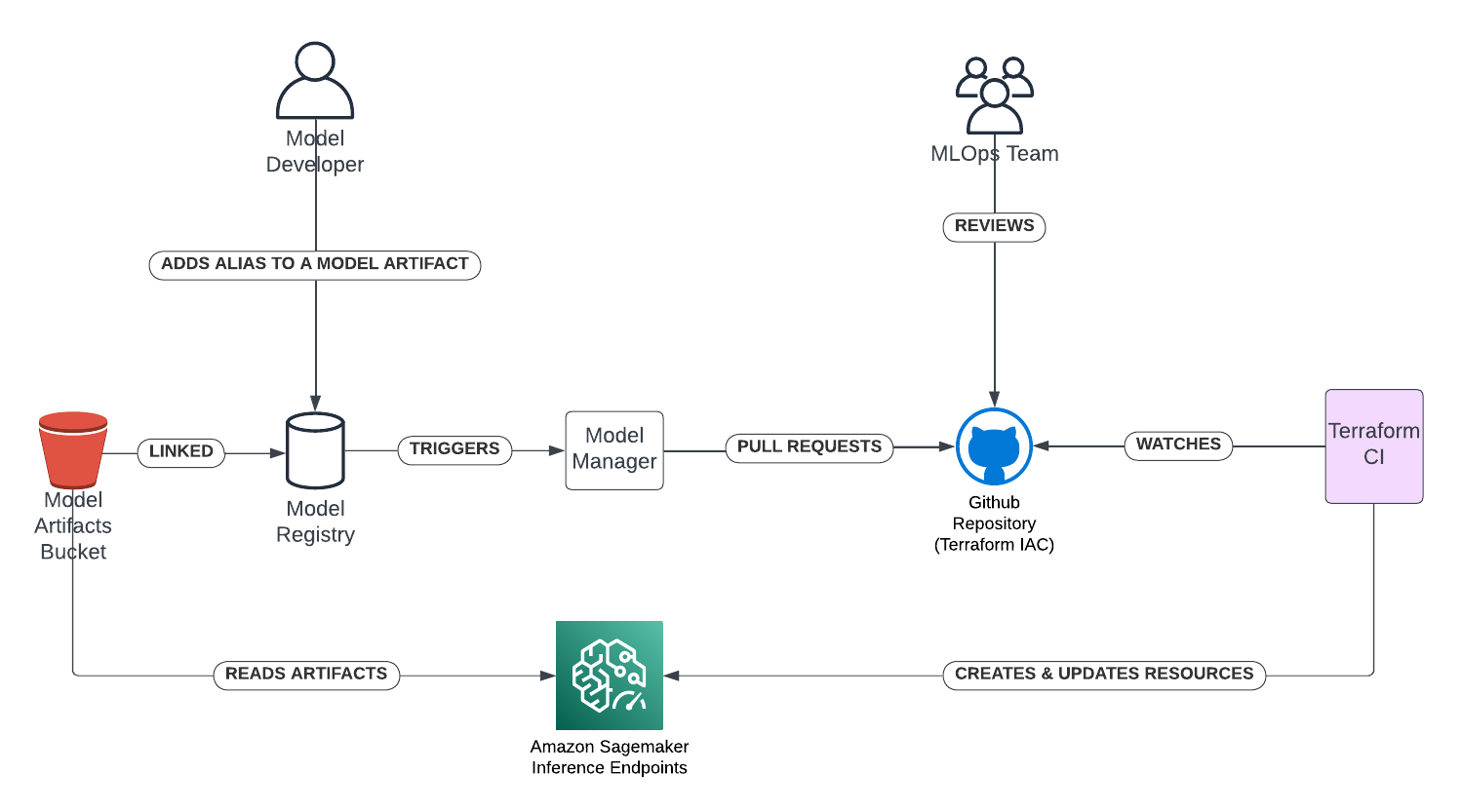
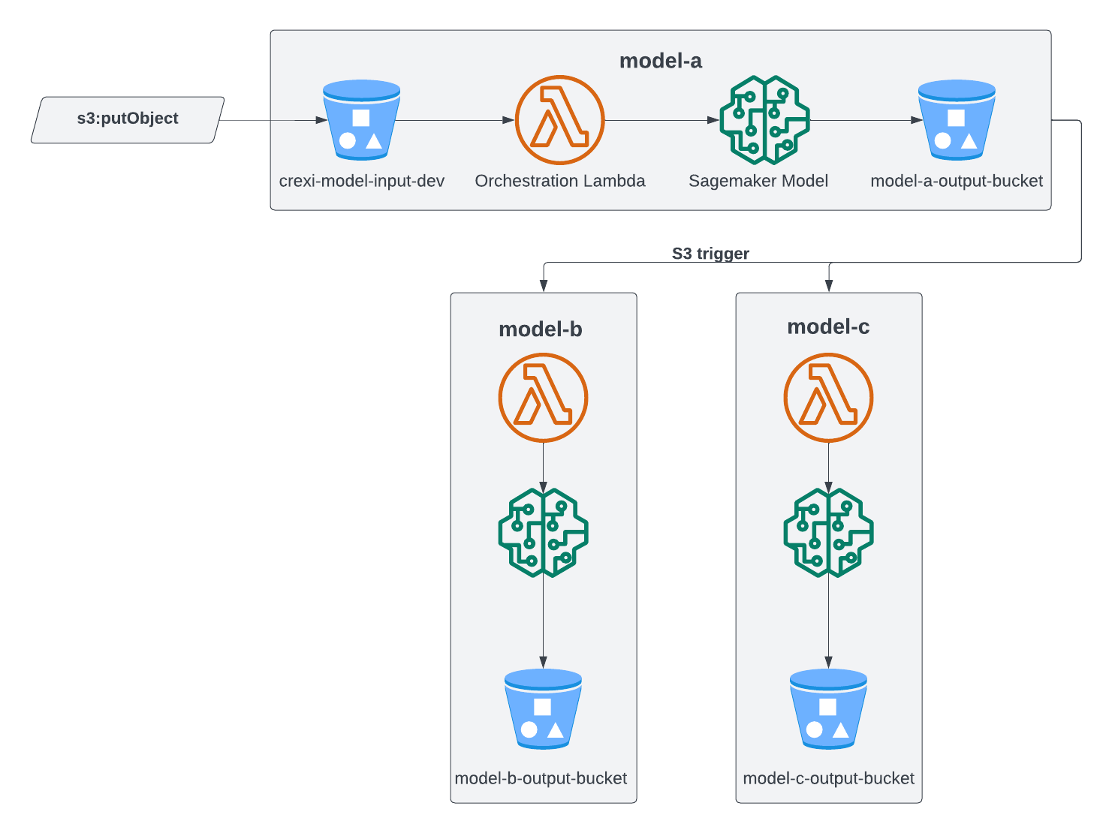
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud. Previously, SageMaker inference endpoints … Read more