Table of Links
-
Analysis
-
Experiments Results
-
Practical Inference Speedup Evaluation
A. Appendix / supplemental material
3.2 dReLU
We introduce a new activation function, named dReLU (Equation 2), where ReLU is applied after both the up- and gate-projection[1].
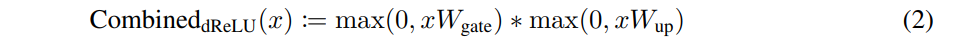
To demonstrate the effectiveness and performance of dReLU, we conducted an experiment comparing 300M-parameter decoder-only architecture models using dReLU and SwiGLU, both pretrained under the fineweb dataset [47] for 5B tokens. Refer to Appendix A.1 for the detailed model architecture hyperparameters. The evaluation result is shown in Table 2.
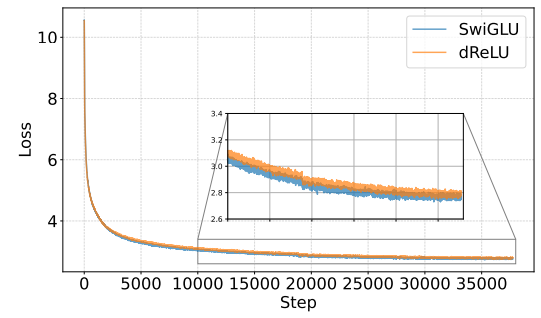
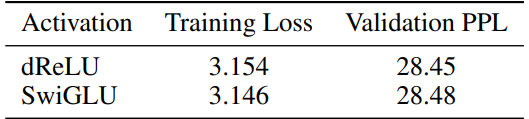
Our findings reveal models employing the dReLU structure exhibit similar convergence compared to those using the SwiGLU structure. Notably, we evaluate the perplexity of both models on Wikitext2 [39]. DReLU-based models show slightly better performance on WikiText-2 [39].
Figure 4 illustrates the loss curves during training, demonstrating that models with the dReLU activation function achieve similar convergence ability compared to their SwiGLU counterparts. To further validate this observation, we evaluate the perplexity of these models on the Wikitext2 dataset. As shown in Table 2. Notably, although SwiGLU-based model has lower training loss, dReLU based model has lower validation perplexity. These results provide strong evidence that adopting the dReLU structure does not compromise model performance. We evaluate on more downstream tasks in Appendix A.1.
Another question we need to address is the dReLU-based model’s sparsity. To investigate the sparsity of the dReLU-based model, we propose a methodology for measuring and evaluating a model’s performance under different sparsity levels. Our approach involves selecting the top-k% of values activated by dReLU or other activation functions based on their absolute magnitude, as described in Equations 3 and 4.


:::info
Authors:
(1) Yixin Song, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Haotong Xie, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zhengyan Zhang, Department of Computer Science and Technology, Tsinghua University;
(4) Bo Wen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Li Ma, Shanghai Artificial Intelligence Laboratory;
(6) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University Mi yzmizeyu@sjtu.edu.cn);
(7) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::
[1] We omit the bias in both the up- and gate-projection to match the form of Equation 1.