A paper from UGA shows you can match SOTA LLM performance with 2000 targeted samples instead of 300000. The secret? Looking inside model’s feature space.
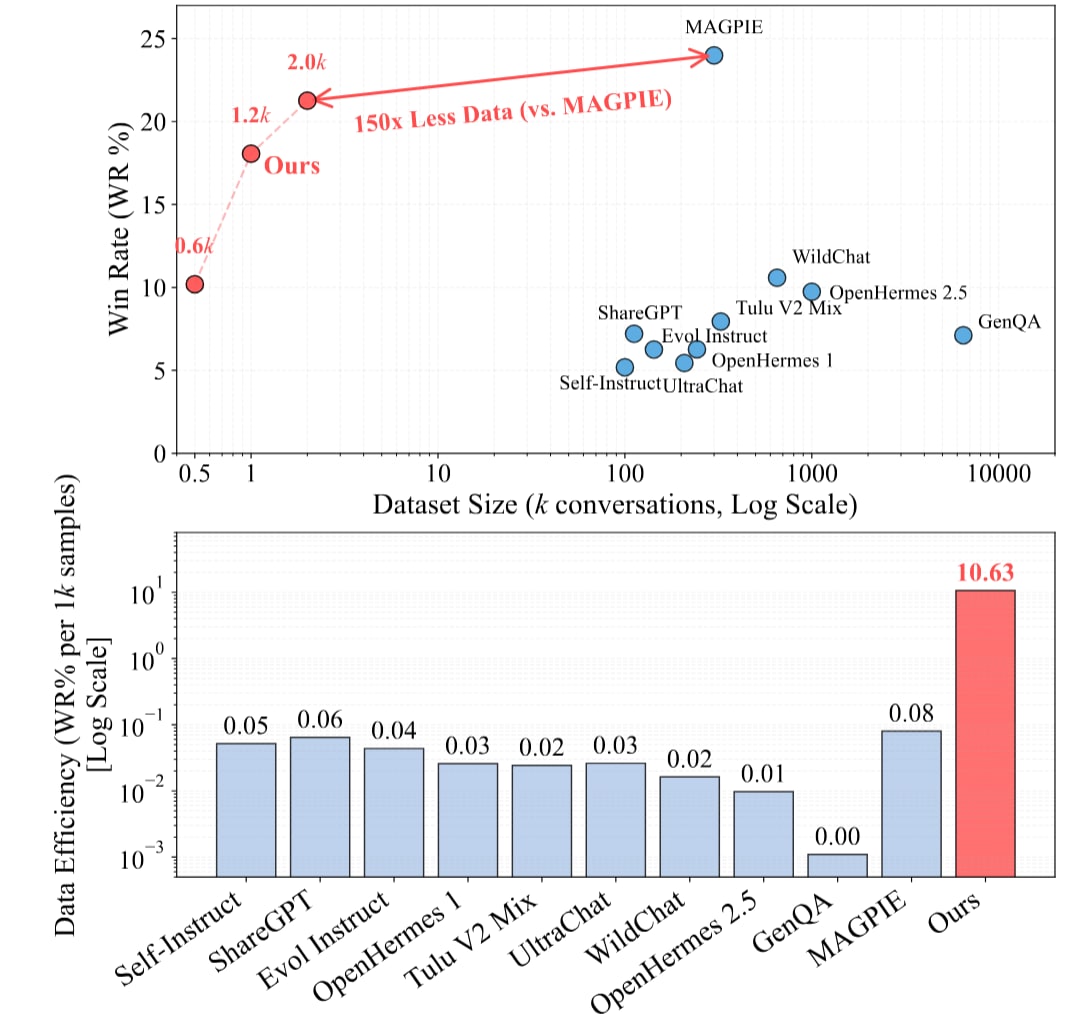
A recent paper called Less is Enough from University of Georgia, UC San Diego matched SOTA performance on instruction-following using 2,000 synthetic samples instead of 300,000. That’s 150x less data for the same results.
The underlying idea is simple: two texts that look completely different can activate nearly identical features inside the model. Real diversity isn’t in the text – it’s in the feature space.
More data, better performance, right?
Model performing poorly? Add more training examples. Dataset not diverse enough? Generate more synthetic data.
Thousands of examples may look different, but they might be teaching the model same things. Different words, same internal features activated.
Well, it’s like following 50 bread recipes that have the same instructions. Waste of time. And flour!
So?
The solution is something called Feature Activation Coverage (FAC). Basically, we check what features are covered/ activated inside the model. We don’t assume different words/ sentences look different – we check if they actually are.
Here’s the process:
- Map the feature space – Check what interpretable features model has learned using sparse autoencoders (a small section on this is down below because I assumed many would be unfamiliar with SAEs)
- Find the gaps – Identify which task-relevant features are missing in training data
- Fill training data to cover gaps – Generate new samples to target those missing features
In their example, they matched MAGPIE’s performance on AlpacaEval 2.0 with just 2,000 carefully chosen samples. MAGPIE used 300,000 samples. Pretty cool.
[
Why care?
A bunch of reasons.
- You get same results with 150x less data. Cheaper finetuning.
- You understand what makes training data useful.
- This works across domains. Instruction following, toxicity prediction, reward modeling, behavior steering.
- Cross-model transfer! (read on to know why I think this)
Counting unique n-grams or measuring cosine distances in embedding space is limited. Limited in the sense that it doesn’t check whether that variation teaches model anything new.
It’s like studying efficiently vs studying a lot.
Cross-model knowledge transfer?
They found a shared feature space across LLaMA, Mistral and Qwen. These are different model families, different architectures trained differently – but the internal features they learn are similar enough to be transferred among each other. That’s… interesting.
Architectures might differ – we have Mistral, Hyena, LLaMA with architectures like MoE, transformers and many more – but the way these models represent knowledge might be more similar than we think.
Sparse Autoencoders
Sparse autoencoders (SAEs) are having their moment in interpretability research. Anthropic’s has been using them to crack open what Claude actually learns internally. DeepMind does the same.
The idea is- models have lots of neurons. If you use an autoencoder on this, you get neuron soup. If you force most neurons off – you have fewer neurons on. Then if you train an autoencoder on this sparse model, this gives you interpretable features. One feature might fire for ‘tensor’, another for ‘woodfire’. You can actually make sense of features now.
Less is Enough uses SAEs to map which features a model has – then synthesizes data to activate underrepresented ones. I can see similar approach translating directly to understand models hallucinating, figure out what causes a specific bias, and debug models behaving unexpecting.
Closing thoughts
There’s a simple catch- to understand your model’s feature space, you need to run sparse autoencoders and do some analysis upfront.
The researchers open-sourced everything – code, pre-trained SAEs for LLaMA/Mistral/Qwen, demo. Links attached.
Links:
- Paper: arXiv:2602.10388
- Code: GitHub
- Demo: Hugging Face Space
- Substack Post: This post was originally published on my substack.