This is a guide for data engineers and AI practitioners on building resilient memory systems that survive the chaos of a changing database.
You spent weeks building the perfect Text-to-SQL agent. It has a high-performance vector store, a sleek React frontend, and it handles complex joins like a senior data engineer. Then, Monday morning happens.
An upstream developer renames userevents to factinteractions to follow a new dbt naming convention. Your agent, relying on a Long-Term Memory (LTM) indexed weeks ago, continues to hallucinate queries for a table that no longer exists. The result? A stack trace instead of a revenue report.
This scenario, which we call the “Monday Morning Problem,” is a familiar nightmare for teams deploying analytical AI. In the world of conversational AI for analytics, schema drift is the final boss. This article presents a battle-tested framework for building a memory system that doesn’t just remember facts, but survives and even thrives in the chaos of a constantly evolving database.
The Memory Paradigm: A Tri-Layer Governance Model
Modern agent architectures rely on a memory hierarchy that mirrors human psychology. To build a production-ready system, however, we must move beyond a simple two-part model and introduce a third, non-negotiable layer: the ground truth.
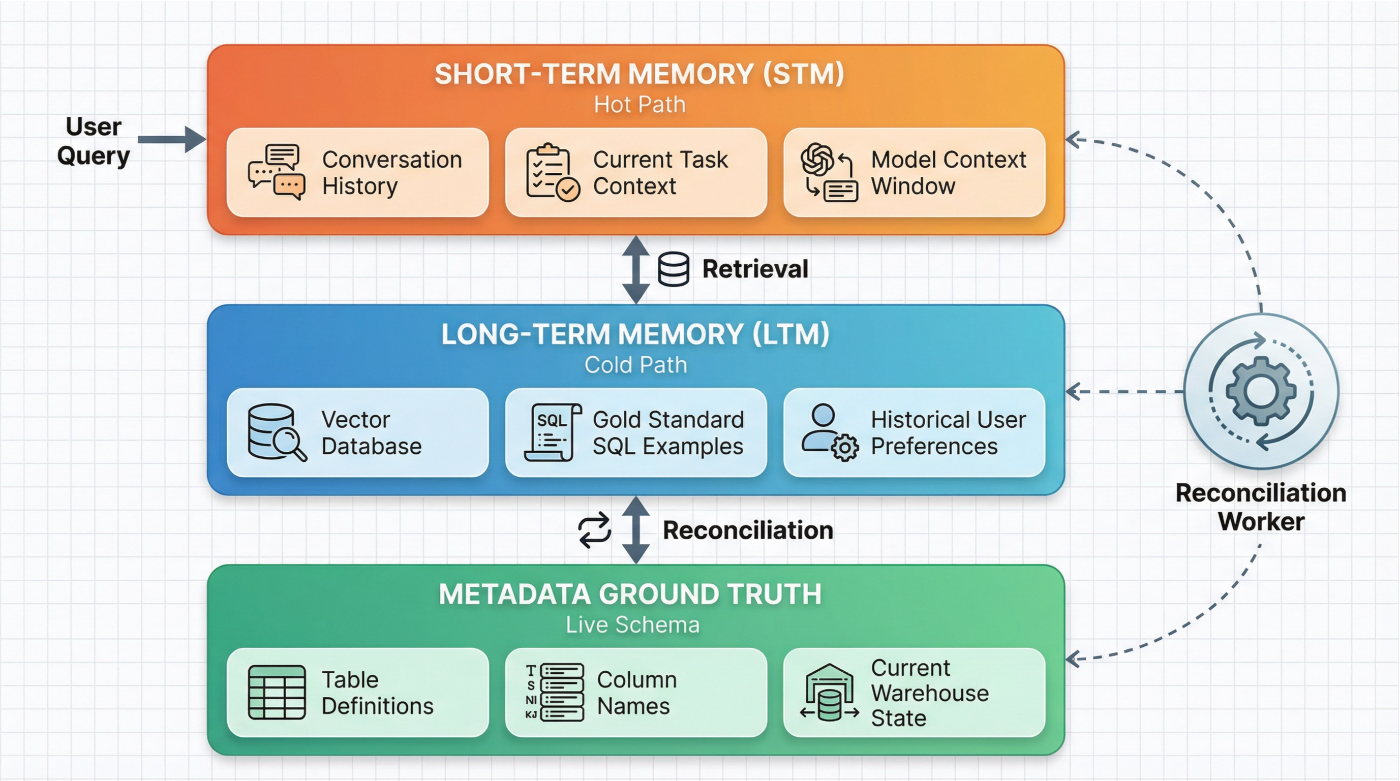
For an agent to be resilient, these three layers must be governed and continuously reconciled. If the Long-Term Memory (what the agent remembers working before) contradicts the Metadata Layer (what is currently in the warehouse), the system fails.
Here’s a breakdown of the key distinctions:
| Aspect | Short-Term Memory (STM) | Long-Term Memory (LTM) |
|:—:|:—:|:—:|
| Primary Role | Hold immediate context, conversation history, and current task parameters. | Store persistent knowledge, historical data, and “gold standard” examples. |
| Typical Size | Small to medium (e.g., 8k to 128k tokens), limited by the context window. | Large and unbounded (GBs to TBs), external to the model. |
| Latency | Very low (sub-millisecond), as it’s part of the synchronous inference pass. | Higher latency is acceptable (100ms+), accessed via asynchronous retrieval. |
| Update Pattern | High-frequency, ephemeral writes during a single session. | Low-frequency, persistent updates and background indexing. |
| Failure Mode | Context truncation, “lost in the middle” attention bias, catastrophic forgetting. | Index staleness, retrieval of irrelevant information, privacy leakage. |
| Common Infra | In-memory context buffers, Redis caches. | Vector databases (Qdrant, Pinecone), Knowledge Graphs, Document Stores. |
Three Workflows to Tame Schema Drift
To prevent the “Monday Morning Problem,” you cannot rely on an LLM to simply “notice” a schema change during a live user session. Instead, you must implement a proactive, multi-layered defense system.
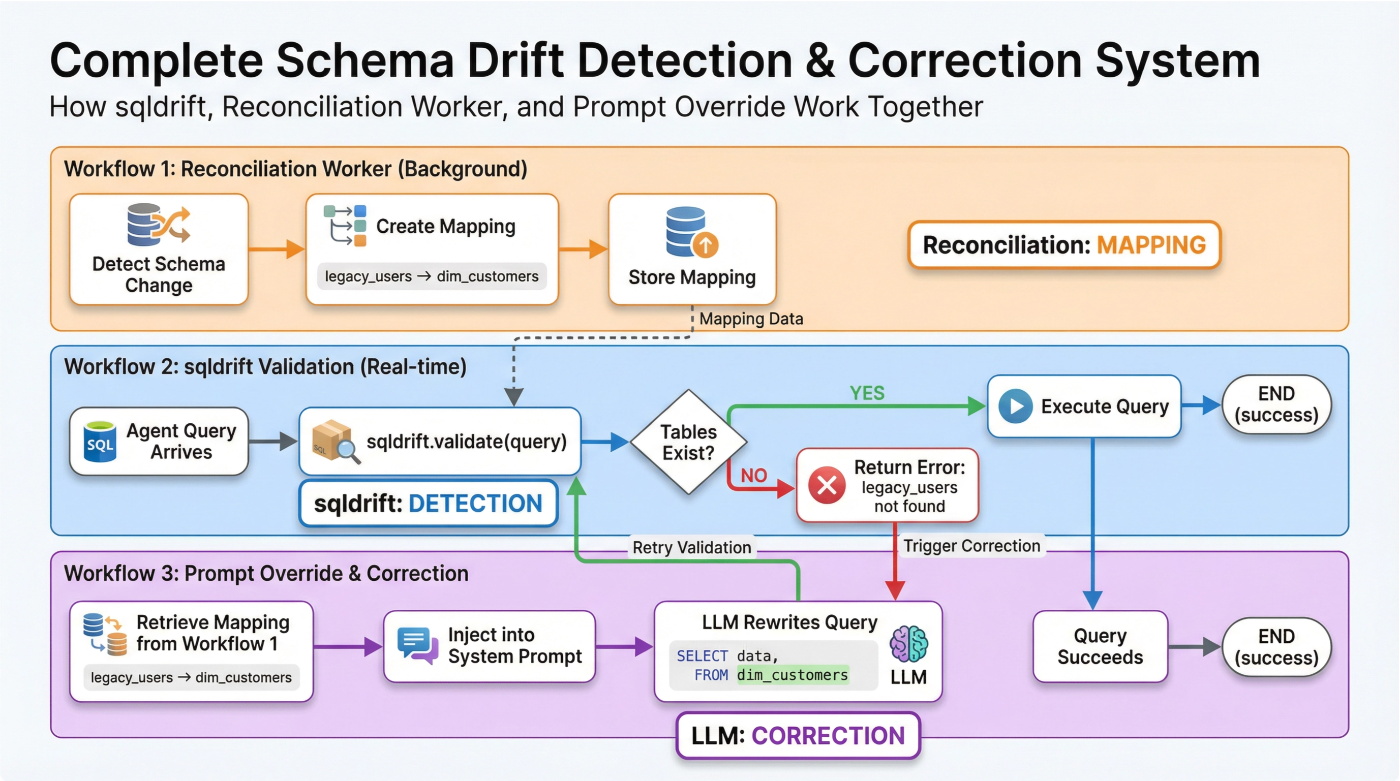
Workflow 1: The Metadata Reconciliation Worker (Mapping)
This is an asynchronous background process that acts as a heartbeat, constantly checking the pulse of your database schema. Its primary job is to create and maintain a mapping between old and new schema names.
- Detection: On a regular schedule, it scans for schema changes (e.g., table renames via DDL logs).
- Mapping: When it detects a rename, it creates a durable mapping, such as {‘legacyusers’: ‘dimcustomers’}.
- Storage: This mapping is stored in a fast-access location (like a Redis cache or a simple database table) for other workflows to use.
Workflow 2: Real-Time Drift Detection with sqldrift
Think of this as your agent’s pre-flight check. Before any query hits the database, it must pass through sqldrift, open-source validation engine. Its role is not just detection, but intelligent diagnosis. sqldrift instantly validates both tables and columns against the live schema, providing actionable error messages when drift is detected. If a query fails, sqldrift doesn’t just return False—it tells the LLM why it failed and how to fix it, triggering the correction workflow with all the context needed for a successful rewrite.
Workflow 3: Prompt-Driven Schema Diffs (Correction)
When sqldrift detects a missing table, the system doesn’t just fail. It uses the error as a trigger to initiate the correction workflow.
-
Retrieve Mapping: The system takes the missing table name (e.g., legacy_users) and looks it up in the mapping created by Workflow 1.
-
Inject Context: It finds the corresponding new name (dim_customers) and injects this information directly into the agent’s system prompt as a hot-patch.
### URGENT CORRECTION: SCHEMA DRIFT DETECTED
A query failed because it referenced a table that has been renamed.
- Old Name: `legacy_users`
- New Name: `dim_customers`
ACTION: You MUST REWRITE the last query to use the new table name.
- LLM Rewrites Query: The agent, now equipped with the correct mapping, rewrites the SQL. The corrected query is then sent back to sqldrift for re-validation, where it passes and is executed.
This complete loop Mapping, Detection, and Correction is what makes the system resilient.
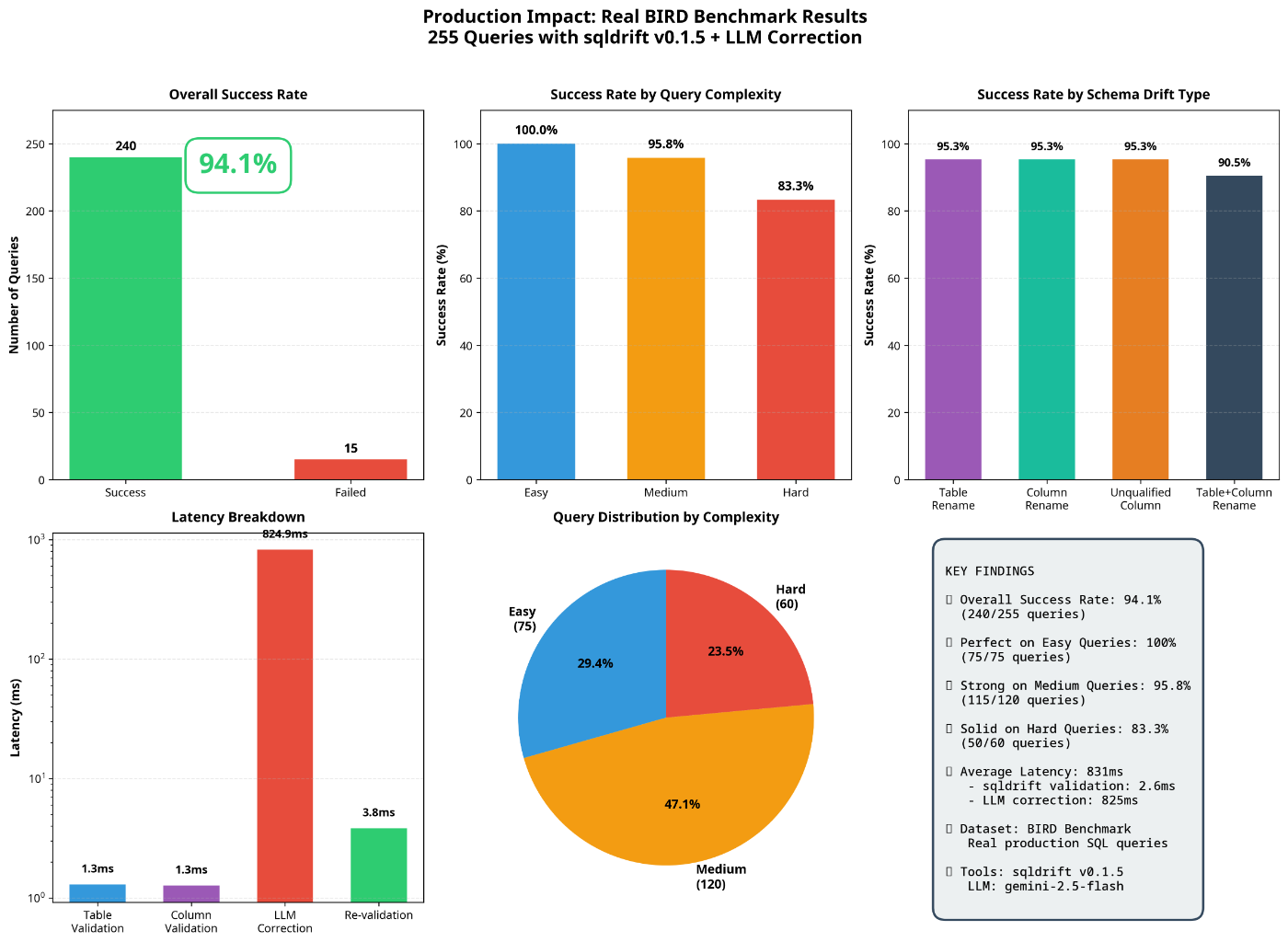
Production Impact: From Brittle to Resilient
The impact on production systems is transformative. By implementing this tri-layer architecture with sqldrift, I achieved a 94.1% of drift-affected queries were autonomously detected and corrected with an average end-to-end latency of 831ms. This translates to a dramatic reduction in failed queries, fewer broken dashboards, and a significant decrease in manual intervention from data teams. Instead of spending Monday mornings fixing broken pipelines, engineers can trust that the system will autonomously adapt to schema changes, ensuring data reliability and freeing up valuable development time.
The Road Ahead: The Future of Memory Governance
We are rapidly moving toward LLM-native schema registries and more autonomous forms of memory management. The next 6 months will see the rise of several key technologies.
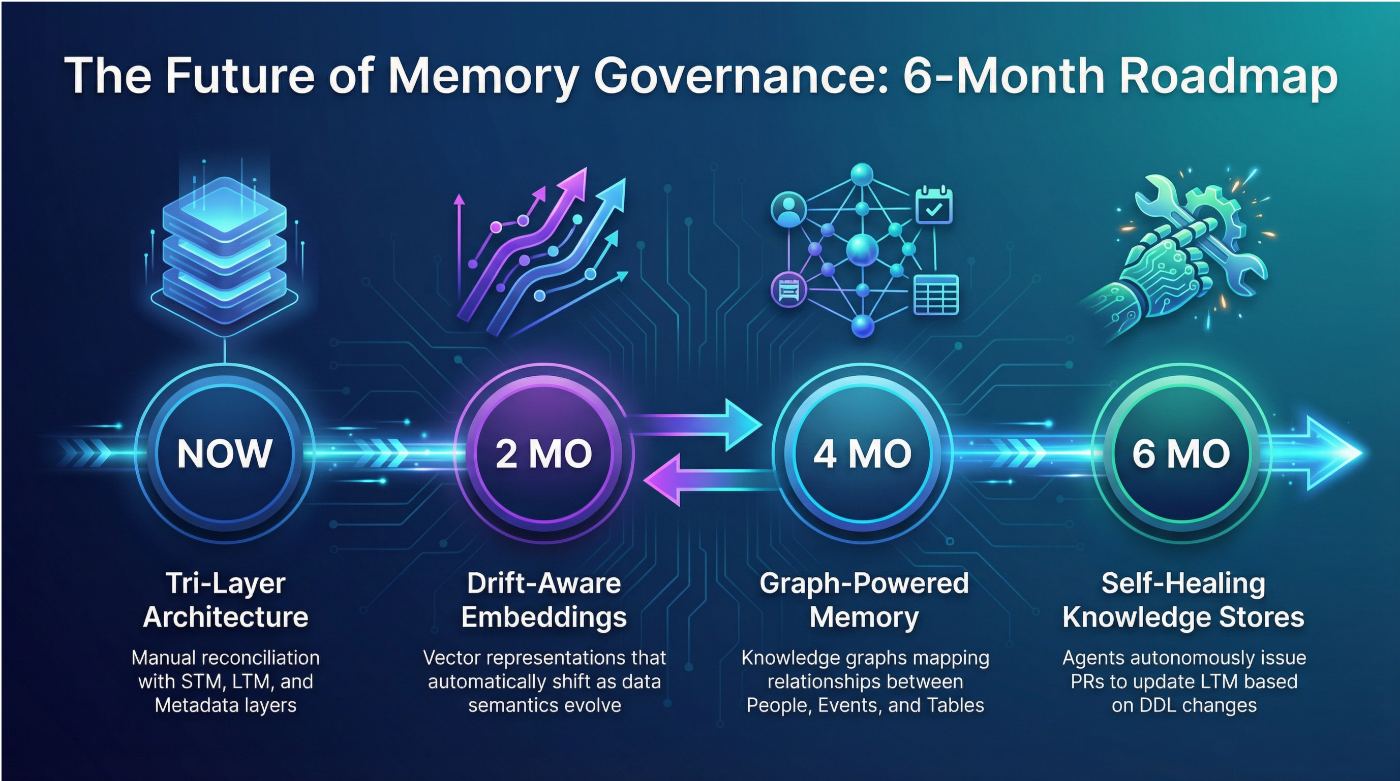
- Drift-Aware Embeddings: Vector representations that automatically shift as the underlying data semantics evolve, reducing the need for costly re-indexing.
- Graph-Powered Memory: A move beyond flat vector search to dynamic Knowledge Graphs that map the relationships between People, Events, and Tables.
- Self-Healing Knowledge Stores: The holy grail agents that don’t just detect drift but autonomously issue pull requests to update their own Long-Term Memory based on Data Definition Language (DDL) changes.
Conclusion: From Brittle Chatbot to Resilient Data Partner
Memory in analytical AI is not just about storage; it is a governed, reconciled, and resilient system. By separating your memory into Active Context (STM) and Durable Indices (LTM), and grounding both in a Metadata Truth Path, you can transform a brittle chatbot into a reliable data partner.
Start by building a solid short-term override buffer, but plan your long-term reconciliation strategy before your first “Monday morning” schema change inevitably arrives. The health of your analytical AI depends on it.
References