Table of Links
Abstract and 1. Introduction and Related Work
3 Experiments
Figure 1 demonstrates how we evaluate the performance of a model on the LLM-Sim task using
in-context learning. We evaluate the accuracy of GPT-4 in both the Full State and State Difference prediction regimes. The model receives the previous state (encoded as a JSON object), previous action, and context message, it produces the subsequent state (either as a complete JSON object or as a diff). See Appendix A for details.

4 Results
Table 2 presents the accuracy of GPT-4 simulating the whole state transitions as well as its accuracy of simulating action-driven transitions and environment-driven transitions alone.[2] We report some major observations below:
Predicting action-driven transitions is easier than predicting environment-driven transitions: At best, GPT-4 is able to simulate 77.1% of dynamic action-driven transitions correctly. In contrast, GPT-4 simulates at most 49.7% of dynamic environment-driven transitions correctly. This indicates that the most challenging part of the LLMSim task is likely simulating the underlying environmental dynamics.
Predicting static transitions is easier than dynamic transitions: Unsurprisingly, modeling a static transition is substantially easier than a dynamic transition across most conditions. While the LLM needs to determine whether a given initial state and action will result in a state change in either case, dynamic transitions also require simulating the dynamics in exactly the same way as the underlying game engine by leveraging the information in the context message.
Predicting full game states is easier for dynamic states, whereas predicting state difference is easier for static states: Predicting the state difference for dynamic state significantly improves the performance (>10%) of simulating static transitions, while decreases the performance when simulating dynamic transitions. This may be because state difference prediction is aimed at reducing potential format errors. However, GPT-4 is able to get the response format correct in most cases, while introducing the state difference increases the complexity of the output format of the task.
Game rules matter, and LLMs are able to generate good enough game rules: Performance of GPT-4 on all three simulation tasks drops in most conditions when game rules are not provided in the context message. However, we fail to find obvious performance differences between game rules generated by human experts and by LLMs themselves.
GPT-4 can predict game progress in most cases: Table 3 presents the results of GPT-4 predicting game progress. With game rules information in the context, GPT-4 can predict the game progress correctly in 92.1% test cases. The presence of these rules in context is crucial: without them, GPT-4’s prediction accuracy drops to 61.5%.
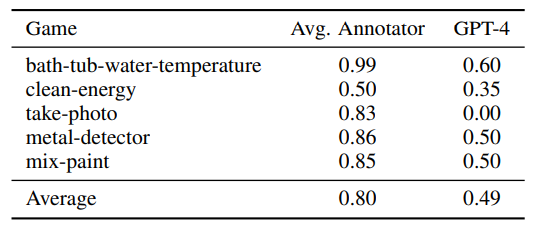
Humans outperform GPT-4 on the LLM-Sim task: We provide a preliminary human study on the LLM-Sim task. In particular, we take the 5 games
from the BYTESIZED32-SP dataset in which GPT4 produced the worst accuracy at modeling Fact. For each game, we randomly sample 20 games with the aim of having 10 transitions where GPT-4 succeeded and 10 transitions where GPT-4 failed (note that this is not always possible because on some games GPT-4 fails/succeeds on most transitions). In addition, we balance each set of 10 transitions to have 5 dynamic transitions and 5 static transitions. We instruct four human annotators (4 authors of this paper) to model as Fact using the human-generated rules as context in a full game state prediction setting. Results are reported in Table 4. The overall human accuracy is 80%, compared to the sampled LLM accuracy of 50%, and the variation among annotators is small. This suggests that while our task is generally straightforward and relatively easy for humans, there is still a significant room for improvement for LLMs.
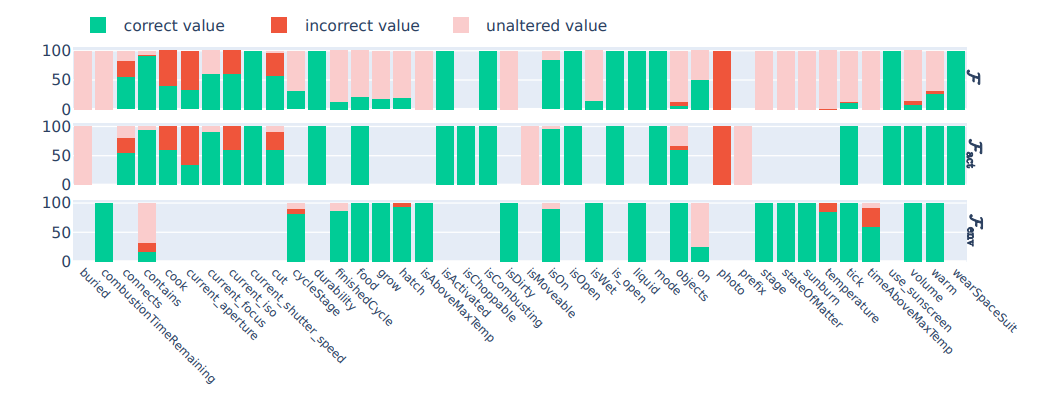
GPT-4 is more likely to make an error when arithmetic, common-sense, or scientific knowledge is needed: Because most errors occur in modeling dynamic transitions, we conduct an additional analysis to better understand failure modes. We use the setting with the best performance on dynamic transitions (GPT-4, Human-written context, full state prediction) and further break down the results according to the specific object properties that are changed during the transition. Figure 2 shows, for the whole state transitions, action-driven transitions, and environment-driven transitions, the proportion of predictions that are either correct, set the property to an incorrect value, or fail to change the property value (empty columns means the property is not changed in its corresponding condition). We observe that GPT-4 is able to handle most simple boolean value properties well. The errors are concentrated on non-trivial properties that requires arithmetic (e.g., temperature, timeAboveMaxTemp), common-sense (e.g., currentaperture, currentfocus), or scientific knowledge (e.g., on). We also observe that when predicting the action-driven and environment-driven transitions in a single step, GPT-4 tends to focus more on action-driven transitions, resulting in more unaltered value errors on states that it can predict correctly when solely simulating environment-driven transitions.
:::info
Authors:
(1) Ruoyao Wang, University of Arizona (ruoyaowang@arizona.edu);
(2) Graham Todd, New York University (gdrtodd@nyu.edu);
(3) Ziang Xiao, Johns Hopkins University (ziang.xiao@jhu.edu);
(4) Xingdi Yuan, Microsoft Research Montréal (eric.yuan@microsoft.com);
(5) Marc-Alexandre Côté, Microsoft Research Montréal (macote@microsoft.com);
(6) Peter Clark, Allen Institute for AI (PeterC@allenai.org).;
(7) Peter Jansen, University of Arizona and Allen Institute for AI (pajansen@arizona.edu).
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::
[2] See Appendix E for the results of GPT-3.5.