:::info
Authors:
(1) An Yan, UC San Diego, ayan@ucsd.edu;
(2) Zhengyuan Yang, Microsoft Corporation, zhengyang@microsoft.com with equal contributions;
(3) Wanrong Zhu, UC Santa Barbara, wanrongzhu@ucsb.edu;
(4) Kevin Lin, Microsoft Corporation, keli@microsoft.com;
(5) Linjie Li, Microsoft Corporation, lindsey.li@mocrosoft.com;
(6) Jianfeng Wang, Microsoft Corporation, jianfw@mocrosoft.com;
(7) Jianwei Yang, Microsoft Corporation, jianwei.yang@mocrosoft.com;
(8) Yiwu Zhong, University of Wisconsin-Madison, yzhong52@wisc.edu;
(9) Julian McAuley, UC San Diego, jmcauley@ucsd.edu;
(10) Jianfeng Gao, Microsoft Corporation, jfgao@mocrosoft.com;
(11) Zicheng Liu, Microsoft Corporation, zliu@mocrosoft.com;
(12) Lijuan Wang, Microsoft Corporation, lijuanw@mocrosoft.com.
:::
:::tip
Editor’s note: This is the part 11 of 13 of a paper evaluating the use of a generative AI to navigate smartphones. You can read the rest of the paper via the table of links below.
:::
Table of Links
- Abstract and 1 Introduction
- 2 Related Work
- 3 MM-Navigator
- 3.1 Problem Formulation and 3.2 Screen Grounding and Navigation via Set of Mark
- 3.3 History Generation via Multimodal Self Summarization
- 4 iOS Screen Navigation Experiment
- 4.1 Experimental Setup
- 4.2 Intended Action Description
- 4.3 Localized Action Execution and 4.4 The Current State with GPT-4V
- 5 Android Screen Navigation Experiment
- 5.1 Experimental Setup
- 5.2 Performance Comparison
- 5.3 Ablation Studies
- 5.4 Error Analysis
- 6 Discussion
- 7 Conclusion and References
5.4 Error Analysis
We look into GPT-4V prediction traces and attempt to categorize common types of errors that cause mismatching between GPT-4V predictions and human annotations.
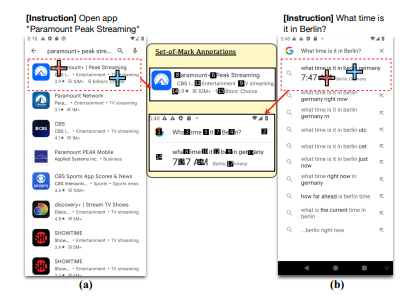
We notice false negative cases where the mismatches are rooted in inaccurate Set-ofMark (Yang et al., 2023b) annotation parsing or imperfect dataset annotation. In these cases, the predictions made by GPT-4V are correct after manual justification, but are classified as wrong predictions in automatic evaluation because the target regions are over-segmented (e.g., Figure 5(a)(b)), or because the ground-truth annotation only covers one of the many valid actions (e.g., Figure 6(a) has two Google Play logo; Figure 6(b) has multiple ways of accessing Google Search; and users may lookup “Setting” by direct search as GPT-4V, or by scrolling down as the human annotation in Figure 6(c)).
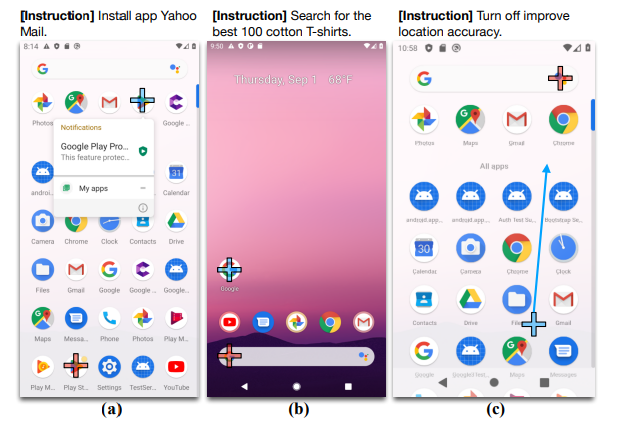
Figure 7 shows a few true negative examples of GPT-4V failing the designated tasks. In our zeroshot testing setup, GPT-4V is not provided with demonstrative examples to learn user action patterns. In this case, while users may scroll down or up to explore the GUI, we notice GPT-4V is more likely to perform the action of “click” on each screen, leading it to occasionally make short sighted decisions. In Figure 7(a), GPT-4V attempts to look for “improve location accuracy” in “Network&Internet” among the listed visible tabs, while the user decides to scroll down and look for more aligned setting tabs. In Figure 7(b), GPT-4V clicks on “Accept All”, which is not a button. In Figure 7(c), GPT-4V also shows a more literal understanding of the instruction and the current observation as in (b), clicking the “News” tab in the Google Search platform instead of actually visiting the news website.
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::