:::info
Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
:::
Table of Links
3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
C. Visualisation
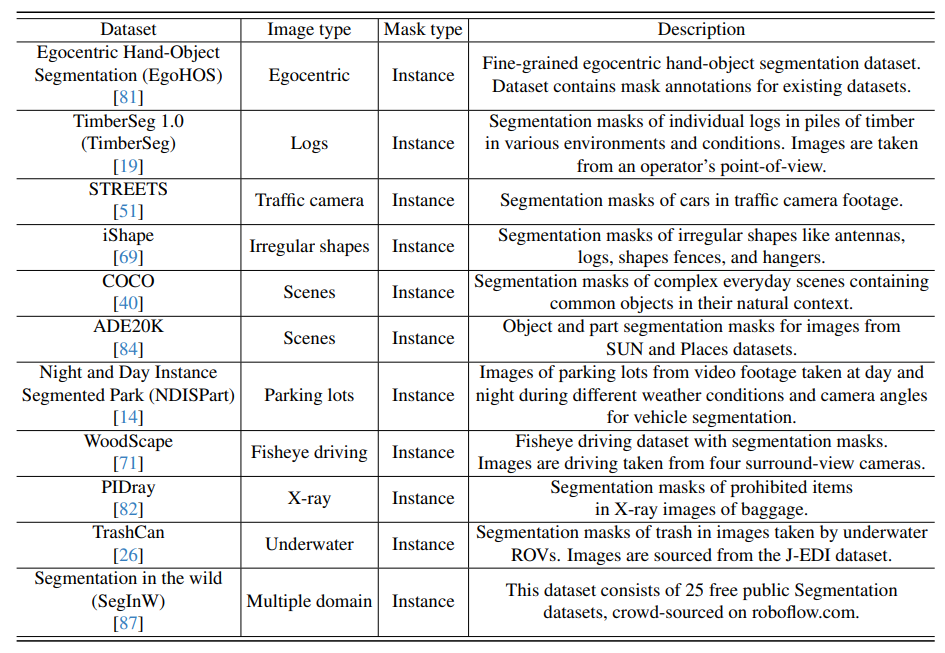
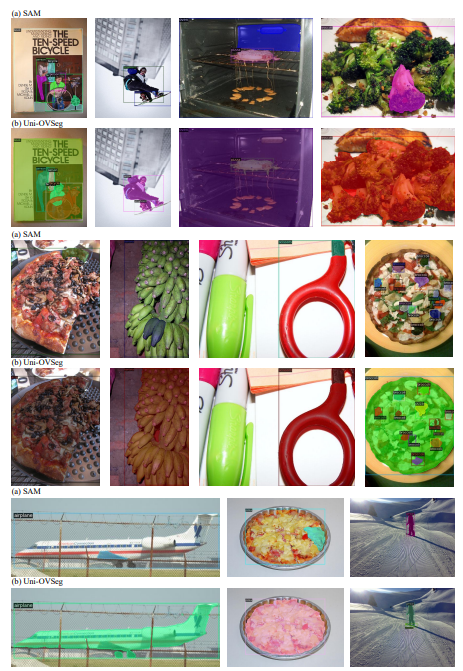
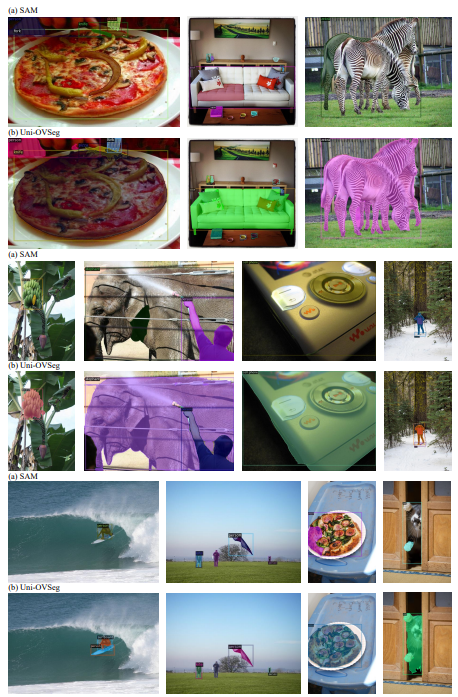
We illustrate a wide range of visualisations of promptable segmentation and open-vocabulary segmentation across multiple datasets.
![Figure 7. Box-promptable segmentation performance. We compare our method with SAM-ViT/L [34] on a wide range of datasets. Given a ground-truth box as the visual prompt, we select the output masks with max IoU by calculating the IoU with the ground-truth masks. We report 1-pt IoU for all datasets.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-x2830no.png)
![Figure 8. Point-promptable segmentation performance. We compare our method with SAM-ViT/L [34] on the SegInW datasets [87]. Given a 20 × 20 point grid as a visual prompt, we select the output masks with max IoU by calculating the IoU with the ground-truth masks. We report 1-pt IoU for all datasets.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-0s930p1.png)
![Figure 9. Box-promptable segmentation performance. We compare our method with SAM-ViT/L [34] on the SegInW datasets [87]. Given a ground-truth box as the visual prompt, we select the output masks with max IoU by calculating the IoU with the ground-truthmasks. We report 1-pt IoU for all datasets.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-dba30p3.png)






:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::