Enhance performance of generative language models with self-consistency prompting on Amazon Bedrock
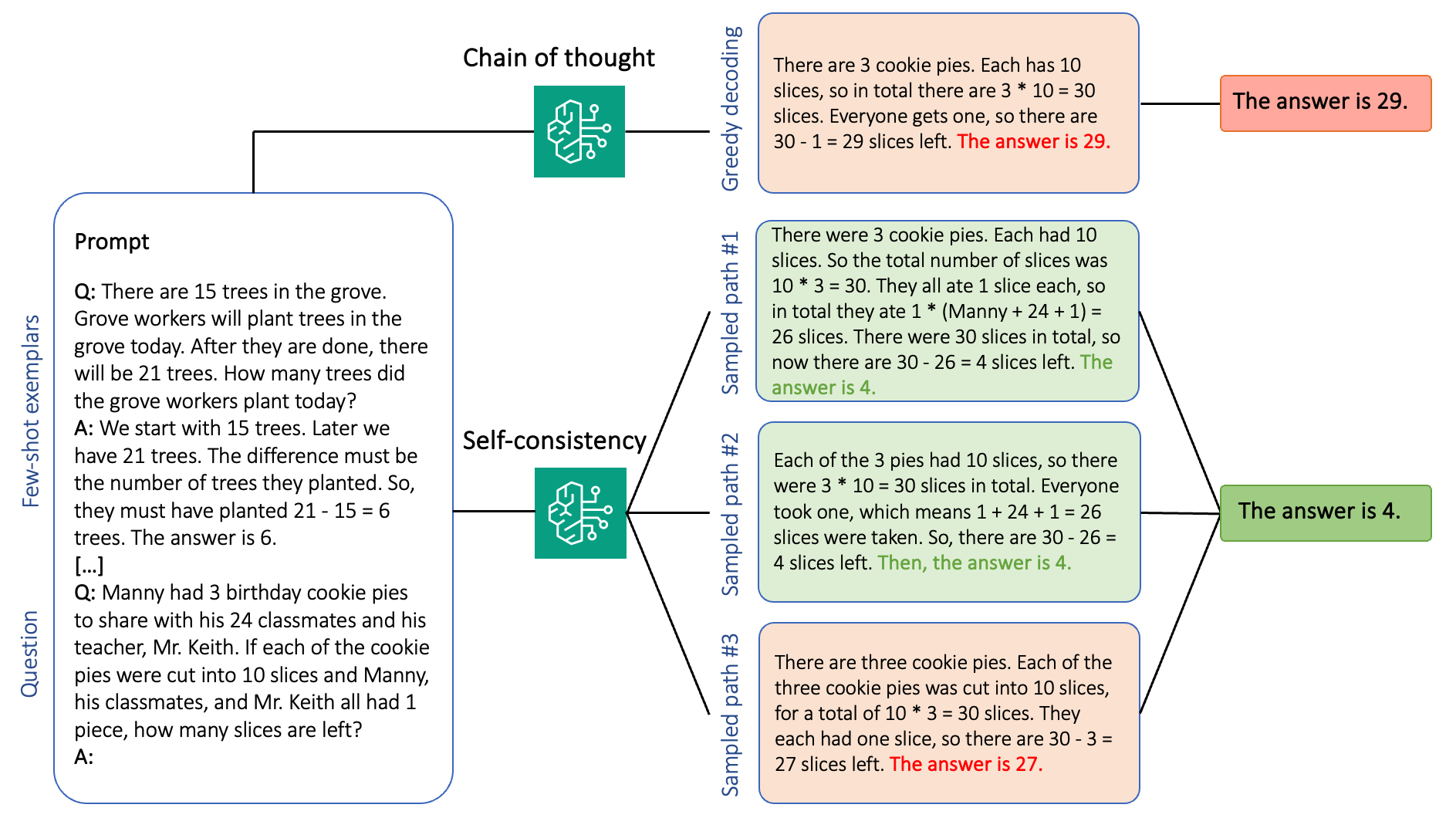
Generative language models have proven remarkably skillful at solving logical and analytical natural language processing (NLP) tasks. Furthermore, the use of prompt engineering can notably enhance their performance. For example, chain-of-thought (CoT) is known to improve a model’s capacity for complex multi-step problems. To additionally boost accuracy on tasks that involve reasoning, a self-consistency prompting … Read more

