Month: September 2023
Coding Guidelines for Prolog (2011)
Comments
Coding Guidelines for Prolog (2011)
Comments
Www which WASM works
Comments
Improving your LLMs with RLHF on Amazon SageMaker
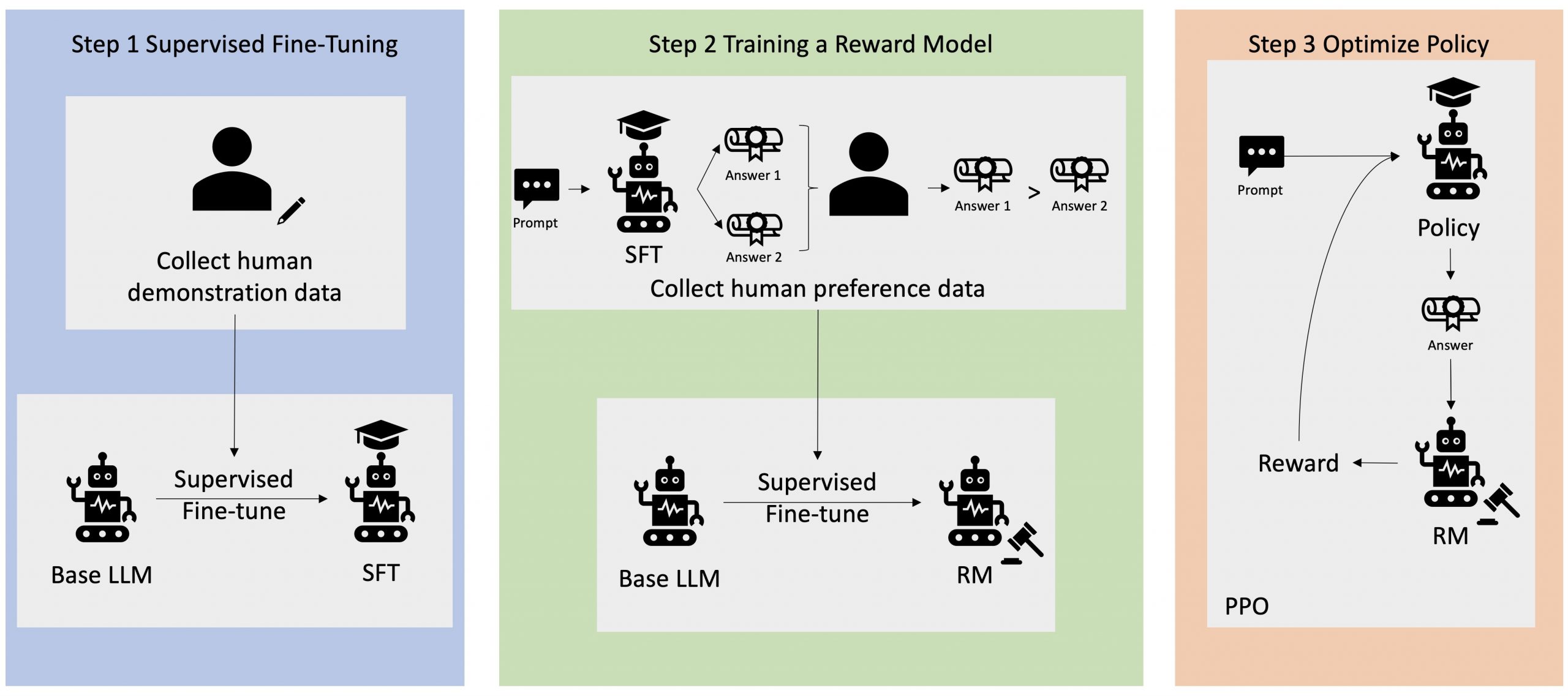
Reinforcement Learning from Human Feedback (RLHF) is recognized as the industry standard technique for ensuring large language models (LLMs) produce content that is truthful, harmless, and helpful. The technique operates by training a “reward model” based on human feedback and uses this model as a reward function to optimize an agent’s policy through reinforcement learning … Read more